对话机器人是最近一个热门话题,许多公司都在开发自己的智能客服系统,笔者将围绕智能对话、智能翻译系统整理出核心技术模型的原理和实战代码详解,撰写【智能聊天机器人技术专辑篇】。
此篇是:【智能客服对话系统专辑:《一、理论篇-核心技术模型原理图文分解》】
下面我们先来看下聊天机器人的神仙组合模型Seq2Seq+attention起源:
Seq2Seq 于 2013年、2014 年被多位学者共同提出,在机器翻译任务中取得了非常显著的效果,随后提出的 attention 模型更是将 Seq2Seq推上了神坛,Seq2Seq+attention 的组合横扫了非常多的任务,只需要给定足够数量的 input-output pairs,通过设计两端的 sequence 模型和 attention 模型,就可以训练出一个不错的模型。除了应用在机器翻译任务中,其他很多的文本生成任务都可以基于 Seq2Seq 模型来做,比如:文本摘要生成、对话生成等。
一、seq2seq模型原理:
seq2seq简单来说就是编码+解码器,把一个语言序列翻译成另一种语言序列,整个处理过程主要使用深度神经网络( LSTM (长短记忆网络)。脑补小时候看抗日大片地道战时,一边是编码发送情报,一边是接收情报用特定的模型进行解码,保证信息不被截胡,不过基本最后都会被我党机智神勇侦破。所以我们最重要的就是理解清楚,这背后的核心原理和模型。

接收输入序列"A B C EOS ( EOS=End of Sentence,句末标记)", 在这个过程中每一个时间点接收一个词或者字,并在读取的EOS时终止接受输入,最后输出一个向量作为输入序列的语义表示向量,这一过程也被称为编码(Encoder)过程,而第二个神经网络接收到第一个神经网络产生的输出向量后输出相应的输出语义向量,并且在这个时候每一个时刻输出词的概率都与前一个时刻的输出有关系,模型会将这些序列一次映射为"W X Y Z EOS",这一过程也被称为解码 (Decoder)过程,这样就实现了句子的翻译过程。整个过程的结构就像下图一样:


1.输入文本处理-词向量化:word embedding (输入文本词向量表达,这里有多种方法,TFIDF、Word2vec、GPT、ELMO、当然了目前ebedding中横扫各个大奖的还应当是BERT,至于BERT为什么夺冠,原理和实战代码,请访问之前写的文章里有详细介绍和代码实战,直通车BERT原理与实战代码。)
2.编码解码处理模型-LSTM:
如果此处你想不起来LSTM原理,下面附加简单介绍,帮你复习下:
2.1RNN弊端与LSTM高明之处
2.1.1先从理解RNN开始:

其中h是隐藏层,y是输出层,输入是一个时间序列x = (x1, x2, …, xT), 对应每一个时间t,RNN中隐藏层的h的更新由下面的表达式决定:
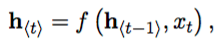
其中,f是一个非线性的激活函数,f可以是tanh或者sigmoid函数。
RNN网络可以通过学习整个输入序列的概率分布来对下一个字或者词进行预测,在这种情况下,对于时间t时,其概率分布为P(xt| xt-1, …, x1), 之后再根据其分布去推测新的字或者词的概率,最后使用softmax函数对输出进行变换之后,得到如下表达式:
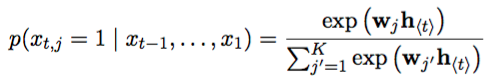
2.1.2为什么RNN不够,LSTM弥补了RNN预测的哪些不足呢?
当我们输入文本很短时,单词总量较少,RNN模型可以通过简单的方式存储先前信息,学会使用先前的信息预测下一个单词。例如,试着预测 “the clouds are in the sky” 最后的词,我们并不需要任何其他的上下文 —— 因此下一个词很显然就应该是 sky。

但是当我们输入的文本足够长,词汇个数较多时,有助于预测目标词的相关信息可能和当前预测位置之间的间隔变得相当的大。RNN 会丧失学习到连接如此远的信息的能力。例如‘他生长在中国,不管到哪里,开会或者聚会,他都说(目标词-中文)’如果我们要预测他说中文,就要去开端链接【中国】这一关键信息,而RNN面对复杂较长的网络语句时,由于结构设计较为简单,对文本的长时记忆存储有限,用较远的词预测当下的目标词汇,准确率则有所欠缺。
LSTM 正是通过调整网络结构,刻意的设计来避免长期依赖问题。LSTM可以看做是RNN中一种特殊的网络结构。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!RNN只有一个tanh层控制输入信息过滤到输出。而LSTM的设计用4个门来完美解决长短时信息依赖传输问题。
2.2LSTM分层图文详解(这里引用朱小虎完美解释)
在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成。该门会读取 h_{t-1} 和 x_t,输出一个在 0 到 1 之间的数值给每个在细胞状态 C_{t-1} 中的数字。1 表示“完全保留”,0 表示“完全舍弃”。

下一步是确定什么样的新信息被存放在细胞状态中。这里包含两个部分。第一,sigmoid 层称 “输入门层” 决定什么值我们将要更新。然后,一个 tanh 层创建一个新的候选值向量,,会被加入到状态中。下一步,我们会讲这两个信息来产生对状态的更新。
在我们语言模型的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。

现在是更新旧细胞状态的时间了, 更新为 。前面的步骤已经决定了将会做什么,我们现在就是实际去完成。
我们把旧状态与 相乘,丢弃掉我们确定需要丢弃的信息。接着加上 。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
在语言模型的例子中,这就是我们实际根据前面确定的目标,丢弃旧代词的性别信息并添加新的信息的地方。

最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 到 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
在语言模型的例子中,因为他就看到了一个 代词,可能需要输出与一个 动词 相关的信息。例如,可能输出是否代词是单数还是负数,这样如果是动词的话,我们也知道动词需要进行的词形变化。

3.编码和解码过程图文解析
3.1 encoder层
举个简单的小例子:
输入层:HOW ARE YOU >>>Word Embedding
中间层输出H与状态层C(LSTM):[h1、c1]、[h2、c2]、[h3、c3]
预测输出层:e0,e1,e2(BUT 输出预测层在我们seq2seq里并没有什么卵用,最主要用的是中间层输出H和状态层C,强调强调!!!!!)

撇除上图的预测输出层E,保留我们编码过程里仅仅需要的中间层H和状态层C,如下图所示呢:

3.2decoder层
从上个encoder阶段 ,我们拿到了最终的状态层C3和最后一道中间输出层h3。开始咱们的解码过程。将encoder阶段的h3、c3输入到decoder的第一层,然后通过一个激活函数和softmax层,得到概率最大的symbol,然后作为下一个时间步长的输入,传到cell中。后面循环往复,得到最终一个完整的输出语句。当然这样的结果主要是利用贪心算法每次取概率最大的分支,在实际应用中会影响对话或者翻译效果,例如语句不通畅,我喜欢中国茶,翻译成我中国茶喜欢类似问题。如何解决呢,攻城狮总是有办法的,下面切入我们的注意力机制,来解决润滑我们的解码过程,提高整个翻译语句/对话质量。

二、注意力机制:attention
什么是注意力机制?下图get注意力机制原理:

1attention原理介绍:
相对于仅仅seq2seq模型,transformer模型加入了Positional encoding也就是为输入文本每个词汇进行位置编码。这在输出预测对应位置词汇,进行语句排版时起到了重要的作用。初次之外,还增加了重要的一项,多头注意力Multi-head attention,MaskedMulti-head attention更充分地实现输入文本中单个词汇语义功能、语句功能的表达和预测。
如何理解transformer模型能够改善翻译语句呢,我们以一个小例子举例:
输入的序列是“我在编程”,如果只是按照上文seq2seq的原理,可能会得到【编程在我】,【在我编程】,【程编我在】多种词义对的上但是顺序混乱的语句,特别是你想翻译诗歌,最后的效果驴头对得上马嘴的情况下,仅仅用seq2seq还是有时会失手的。
而注意力机制 相当于在原文输入时,为每个词汇对应的翻译输出,下了一个位置锚,更好的定位预测词,翻译输出合理的自然的语序。首先Encoder中的h1、h2、h3、h4就可以分别看做是“我”、“在”、“编”、“程”所代表的信息。在翻译成英语时,第一个上下文c1应该和“我”这个字最相关,因此对应的a11比较大,相应的a12、a13、a14会比较小。c2应该和“在”最相关,因此对应的a22比较大。最后的c3和h3、h4最相关,因此a33/a34的值就比较大。由此看来,输入字符与输出字符除了编码以外,对应的位置相当重要,在最终翻译结果中,可以将模糊的一句话,结合输入时原文的词汇位置进行权重赋值,最终输出的模糊语文轮次的句子被编排的更加得体自然。
2attention核心-权重计算:我们如何计算aij的权重呢?
首先下图是加入了Attention机制的seq2seq:
其中encoder的Ht层和decoder的Hs层是计算权重的关键所在。

再然后是开始计算咱们的aij权重啦:
有三种计算方式:主要看第一种dot模式下aij权重计算。
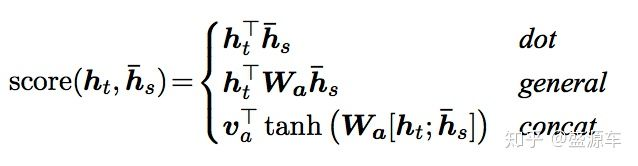
输入是encoder的所有hidden states H: 大小为(hid dim, sequence length)。decoder在一个时间点上的hidden state, s: 大小为(hid dim, 1)。
第一步:旋转H为(sequence length, hid dim) 与s做点乘得到一个 大小为(sequence length, 1)的分数。
第二步:对分数做softmax得到一个合为1的权重。
第三步:将H与第二步得到的权重做点乘得到一个大小为(hid dim, 1)的context vector。
第二种模式图解如下:很类似 增加了一个中间调解向量W。

好了,以上就是关于seq2seq+attention原理图文详解部分了,代码部分放到智能对话客服专辑《二》中吧。
PS:本博持续更新AI算法与最新应用,如果您感兴趣,欢迎留爪点赞,点击关注AI工匠(AI算法与最新应用前沿研究)。
AI工匠博客:https://i.csdn.net/#/uc/profile
其中文中提到的BERT传送门:
AI工匠:输入文本词向量最强模型BERT原理详解与实战代码
https://blog.csdn.net/weixin_37479258/article/details/95987244
感谢本文参考来源:
作者:北邮张博
https://blog.csdn.net/irving_zhang/article/details/78889364
作者:lovive
链接:https://www.jianshu.com/p/eeb4d5b47321
作者:朱小虎XiaohuZhu
链接:https://www.jianshu.com/p/9dc9f41f0b29
