背景
Fast R-CNN存在一个缺点,它需要使用selective search提取框,这个方法比较慢,有时检测一张图片,大部分时间不是花费在神经网络分类上,而是花在selective search提取框上。而它的升级版Faster R-CNN中,使用RPN网络取代了selective search,不仅速度大大提高,而且获得了更加精确的结果。
网络结构

对于任意大小的图片,首先缩放至固定大小MxN,然后将图像送入网络;Conv中包含了13个conv层+13个relu层+4个pooling层;RPN网络首先经过3x3卷积,再分别生成positive anchors和对应bounding box regression偏移量,然后计算出proposal;而ROI Pooling层则利用proposals从feature maps中提取proposals feature送入后续全连接和softmax网络做classification。
关键点
RPN网络

- 在feature map上滑动窗口
- 建一个神经网络用于物体分类+框位置的回归
- 滑动窗口的位置提供了物体的大体位置信息
- 框的回归提供了框更精确的位置
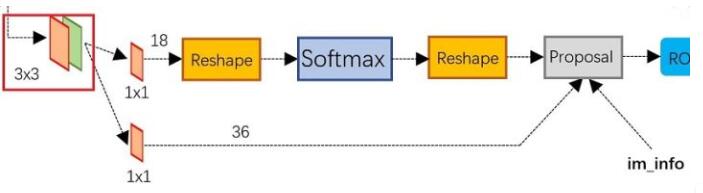
RPN网络实际分为2条线,上面一条通过softmax分类anchors获得positive和negative分类,下面一条用于计算对于anchors的bounding box regression偏移量,以获得精确的proposals。最后的proposal层则负责综合positive anchors和对应bounding box regression偏移量获取proposals,同时提出太小和超出边界的proposals。其实整个网络到了proposal layer这里,就完成了相当于目标定位的功能。
anchors
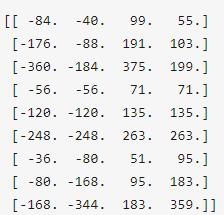
每行的4个值分别表示矩形左上和右下角坐标。9个矩形共有三种形状,长宽比有{1:1, 1:2, 2:1}三种。
作用 遍历Conv layers计算获得的feature maps,为每一个点都配备9中anchors作为初始的检测框。这样做获得检测框很不准确,不用担心,后面还有两次bounding box regression可以修正检测框位置。
softmax判定positive和negative
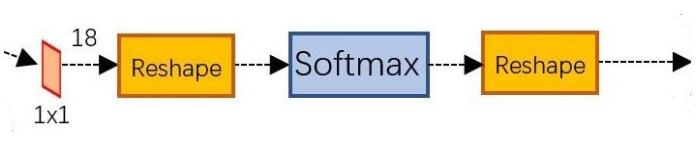
一副MxN大小的矩阵送入Faster R-CNN网络后,到RPN网络变为(M/16)x(N/16),不妨设W=M/16, H=N/16。在进入reshape与softmax之前,先做1x1卷积。经过卷积后图像变为WxHx18的大小。这也就刚好对应了feature maps中每一个点都有9个anchors,同时每个anchors有可能是positive或negative,所有这些信息都保存为WxHx(9*2)大小的矩阵。后面进行softmax分类获得positive anchors,也就相当于初步提取了检测目标候选区域box。
bounding box regression
点击查看
