从RCNN到fast RCNN,再到本文的faster RCNN,目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)终于被统一到一个深度网络框架之内(RCNN4步->fast RCNN2步->Faster R-CNN1步)。所有计算没有重复,完全在GPU中完成,大大提高了运行速度。
Faster R-CNN统一的网络可以简单看作RPN网络+Fast R-CNN网络。RPN网络代替了原来的候选框操作。

创新点
设计Region Proposal Networks【RPN】,利用CNN卷积操作后的特征图生成region proposals(候选框生成),代替了Selective Search、EdgeBoxes等方法,速度上提升明显;
训练Region Proposal Networks与检测网络【Fast R-CNN】共享卷积层,大幅提高网络的检测速度。
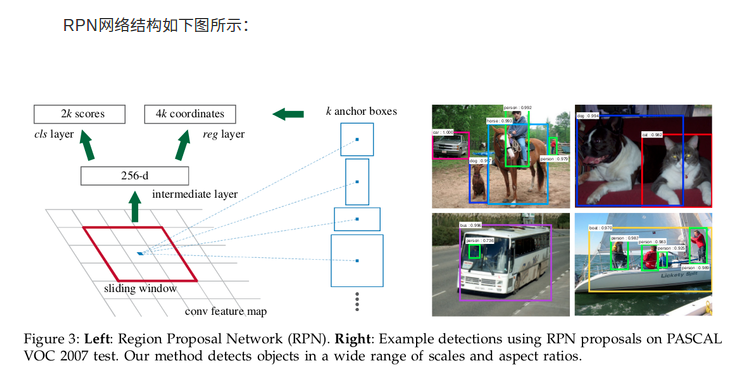
Faster R-CNN统一的网络结构如下图所示

整体训练流程如下:
首先向CNN网络【ZF或VGG-16】输入任意大小图片,进行特征提取;
经过CNN网络前向传播至最后共享的卷积层,一方面得到供RPN网络输入的特征图,另一方面继续前向传播至特有卷积层,产生更高维特征图;
供RPN网络输入的特征图经过RPN网络得到区域建议和区域得分,并对区域得分采用非极大值抑制【阈值为0.7】,输出其Top-N【文中为300】得分的区域建议给RoI池化层;
第2步得到的高维特征图和第3步输出的区域建议同时输入RoI池化层,提取对应区域建议的特征;
第4步得到的区域建议特征通过全连接层后,输出该区域的分类得分以及回归后的bounding-box。

CNN提取的原始图片特征为 51宽x39 长x256通道,对它再一次卷积运算再次得到一个51x39x256的卷积特征。
共有51X39个像素位置,每个位置都有9中候选框检测。
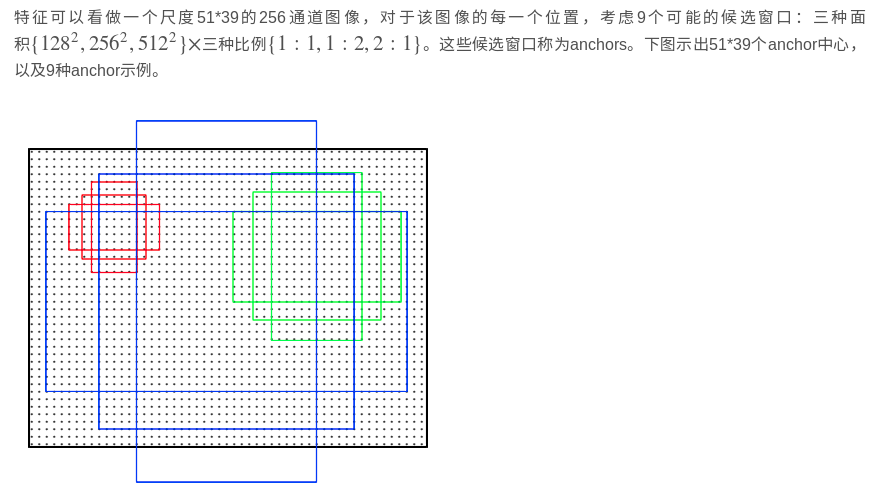
使用3x3的滑动窗口,使得该51x39x256的卷积特征的每一个像素对应的位置转换为统一的256维特征。并不是指最终卷积后的尺寸。通过上面图表可知,结果任然是原尺寸51X39 X256维
k为单个位置对应的anchor个数,此时k=9
分类层(cls_layer)输出每一个位置上,9个anchor,属于前景(即是物体)和背景(当前没有物体,只有背景)的概率;
定位窗口回归层(reg_layer)输出每一个位置上,9个anchor对应窗口应该平移缩放的参数。
对于每一个位置来说,分类层从256维特征中输出属于前景和背景的概率;
窗口回归层从256维特征中输出4个平移缩放参数。
就局部来说,这两层是全连接网络;就全局来说,由于网络在所有位置(共51*39个)的参数相同,所以实际用尺寸为1×1的卷积网络实现。
=======
具体实现:
①首先套用ImageNet上常用的图像分类网络,本文中试验了两种网络:ZF或VGG-16,利用这两种网络的部分卷积层产生原始图像的特征图;
② 对于①中特征图,用n×n【论文中设计为3×3,n=3看起来很小,但是要考虑到这是非常高层的feature map,其size本身也没有多大,因此9个矩形中,每个矩形窗框都是可以感知到很大范围的】的滑动窗口在特征图上滑动扫描【代替了从原始图滑窗获取特征】,每个滑窗位置通过卷积层1映射到一个低维的特征向量【ZF网络:256维;VGG-16网络:512维,低维是相对于特征图大小W×H,typically~60×40=2400】后采用ReLU,并为每个滑窗位置考虑k种【论文中k=9】可能的参考窗口【论文中称为anchors,见下解释】,这就意味着每个滑窗位置会同时预测最多9个区域建议【超出边界的不考虑】,对于一个W×H的特征图,就会产生W×H×k个区域建议;
③步骤②中的低维特征向量输入两个并行连接的卷积层2:reg窗口回归层【位置精修】和cls窗口分类层,分别用于回归区域建议产生bounding-box【超出图像边界的裁剪到图像边缘位置】和对区域建议是否为前景或背景打分,这里由于每个滑窗位置产生k个区域建议,所以reg层有4k个输出来编码【平移缩放参数】k个区域建议的坐标,cls层有2k个得分估计k个区域建议为前景或者背景的概率
RPN网络中bounding-box回归怎么理解?同Fast R-CNN中的bounding-box回归相比有什么区别?
对于bounding-box回归,采用以下公式:
其中,x,y,w,h表示窗口中心坐标和窗口的宽度和高度,变量x
, xa和 x∗分别表示预测窗口、anchor窗口和Ground Truth的坐标【y,w,h同理】,因此这可以被认为是一个从anchor窗口到附近Ground Truth的bounding-box 回归;
RPN网络中bounding-box回归的实质其实就是计算出预测窗口。这里以anchor窗口为基准,计算Ground Truth对其的平移缩放变化参数,以及预测窗口【可能第一次迭代就是anchor】对其的平移缩放参数,因为是以anchor窗口为基准,所以只要使这两组参数越接近,以此构建目标函数求最小值,那预测窗口就越接近Ground Truth,达到回归的目的;
文中提到, Fast R-CNN中基于RoI的bounding-box回归所输入的特征是在特征图上对任意size的RoIs进行Pool操作提取的,所有size RoI共享回归参数,而在Faster R-CNN中,用来bounding-box回归所输入的特征是在特征图上相同的空间size【3×3】上提取的,为了解决不同尺度变化的问题,同时训练和学习了k个不同的回归器,依次对应为上述9种anchors,这k个回归量并不分享权重。因此尽管特征提取上空间是固定的【3×3】,但由于anchors的设计,仍能够预测不同size的窗口。
参考:
https://blog.csdn.net/wopawn/article/details/52223282#comments
https://blog.csdn.net/shenxiaolu1984/article/details/51152614
https://blog.csdn.net/shenxiaolu1984/article/details/51036677
但是真正涉及到核心难点细节的建议看:
https://blog.csdn.net/qq_17448289/article/details/52871461
http://www.360doc.com/content/17/0303/14/10408243_633634497.shtml
http://www.360doc.com/content/17/0809/10/10408243_677742029.shtml