论文地址:https://arxiv.org/abs/1506.01497
文章内容:
-
论文概述
-
算法核心
-
ROI Pooling
-
普通池化与RIO池化的反向传播:
-
和YOLOV3对比
论文概述:
在Fast R-CNN基础上做了改进,将Selective Search改为RPN网络来提取候选框,提升了检测算法的速度。RPN是全卷积网络,同时预测每个位置的目标概率和边界框回归。RPN和Fast R-CNN融合在单一网络里,共享卷积层。RPN提高了区域提议的质量,也提高了目标检测的准确率
算法核心:
Faster R-CNN总体结构:

更为详细的图,如下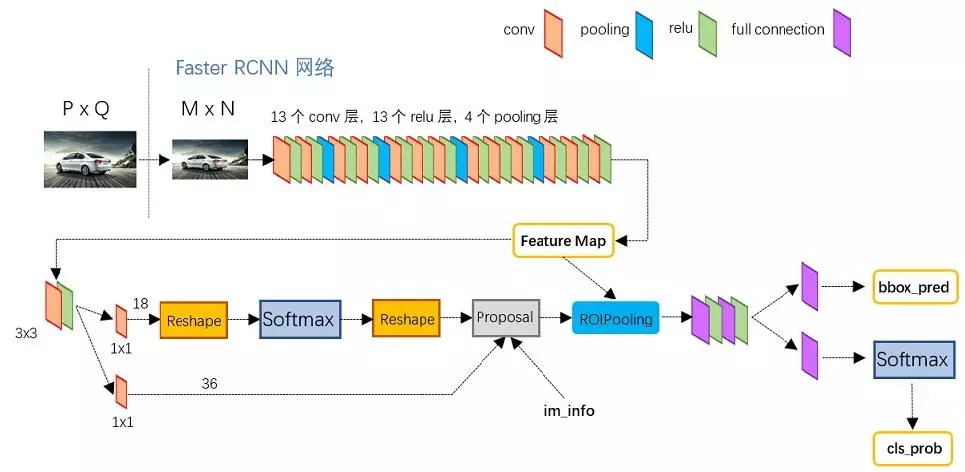
主要包含两个模块:
一个是RPN,深度全卷积网络,提议区域,一个是在提议区域上做Fast R-CNN检测。RPN起到attention的作用,告诉Fast R-CNN where to look。
网络先进入共享卷积层提取特征,输入RPN后得到候选框区域的位置和二分类结果(是否是目标),将这些候选框从特征图中获取后,经过ROI Pooling统一大小,再经过卷积、全连接进行分类和边界框回归
RPN

RPN网络为CNN后面接一个3*3的卷积层,再接两个11的卷积层(原文称这两个卷积层的关系为sibling),其中一个是用来给softmax层进行分类,另一个用于给候选区域精确定位。
Anchors:每个滑框位置,都预设k个不同的框,如文中用9个,分别是3个scale和3个aspect ratio。因为提出的候选区域是在原图上的区域,所以要清楚anchors在原图中的位置。假设CNN得到的feature map大小为w∗hw*hw∗h,那总的anchors个数为9∗w∗h9*w*h9∗w∗h,9为上述的9种anchors。假设原图大小为W∗HW*HW∗H,由SPP-net文章详细解读知W=S⋅w,H=S⋅h,S为之前所有层的stride size相乘,所以feature map上的点乘以S即为anchors的原点位置,得到所有框的原点位置以及大小就可以得到原图上的anchors区域了。
Loss函数:

RPN训练中对于正样本文章中给出两种定义。第一,与ground truth box有最大的IoU的anchors作为正样本;第二,与ground truth box的IoU大于0.7的作为正样本。文中采取的是第一种方式。文中定义的负样本为与ground truth box的IoU小于0.3的样本
其中,i表示mini-batch中第i个anchor,pip_{i}p i表示第i个anchor是前景的概率,当第i个anchor是前景时p i∗为1反之为0,t i表示预测的bounding box的坐标,t i∗为ground truth的坐标。
其中t,t*的计算为:

This can be thought of as bounding-box regression from an anchor box to a nearby ground-truth box
Faster R-CNN的训练方法主要分为两个,目的都是使得RPN和Fast R-CNN共享CNN部分,如下图所示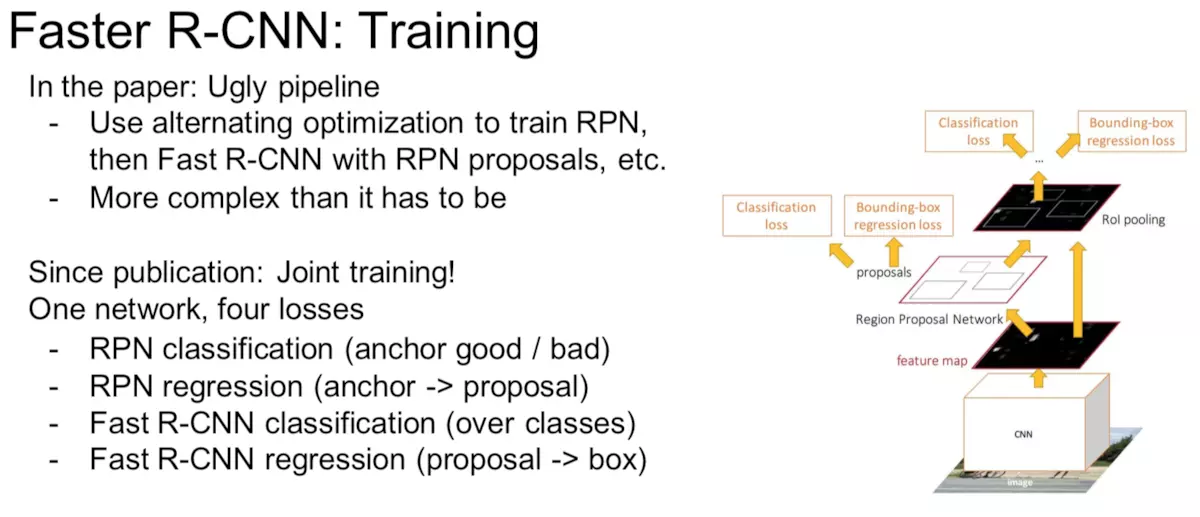
一个是迭代的,先训练RPN,然后使用得到的候选区域训练Fast R-CNN,之后再使用得到的Fast R-CNN中的CNN去初始化RPN的CNN再次训练RPN(这里不更新CNN,仅更新RPN特有的层),最后再次训练Fast R-CNN(这里不更新CNN,仅更新Fast R-CNN特有的层)。
还有一个更为简单的方法,就是end-to-end的训练方法,将RPN和Fast R-CNN结合起来一起训练,tf版本的代码有这种方式的实现。
RPN提议的区域有很多重叠的框,为了减少候选框的数量,使用了NMS,最终每张图大概剩2000个候选框
ROI Pooling
ROI pooling作用:
(1)用于目标检测任务;(2)允许我们对CNN中的feature map进行reuse;(3)可以显著加速training和testing速度;(4)允许end-to-end的形式训练目标检测系统。
ROI pooling具体操作如下:
(1)根据输入image,将ROI四个顶点的坐标映射到feature map对应位置;
(2)将映射后的区域划分为相同大小的sections(sections数量与输出的尺寸如7*7相同);
(3)对每个sections进行max pooling操作。
这样我们就可以从不同大小的方框(ROI)得到固定大小的相应的feature maps(ROI Pooling后输出的结果)。值得一提的是,输出的feature maps的大小不取决于ROI和feature maps的大小,而取决于输出维度的大小(如7×7)。ROI pooling 最大的好处就在于极大地提高了处理速度。
上面这句注释的意思是RoI Pooling结果的每个bin在RoI中起始和结束的index。
比如对于上图来说最终RoI Pooling的结果的第0个bin,其实际计算应该是:

也就是实际上应该如下图划分bin:
可以看到在实际划分时,roi中有一些特征点是被重复使用的,最终得到RoI Pooling结果应该是:
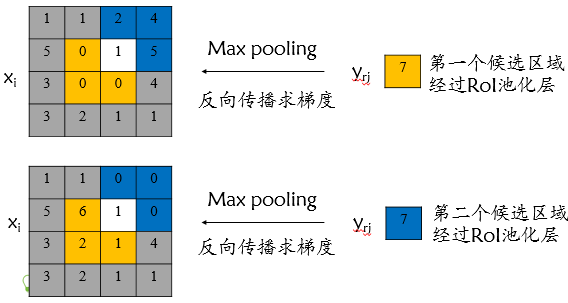
上述内容实际上在RoI Pooling的反向传播公式中也有体现:

其中j的累加意思就是对于RoI中的特征点i,在相同的RoI中其可能会被多个bin所使用,所以其梯度需要考虑多个RoI的多个bin。
普通池化与RIO池化的反向传播:
无论max pooling还是mean pooling,都没有需要学习的参数。因此,在卷积神经网络的训练中,Pooling层需要做的仅仅是将误差项传递到上一层,而没有梯度的计算。
(1)max pooling层:对于max pooling,下一层的误差项的值会原封不动的传递到上一层对应区块中的最大值所对应的神经元,而其他神经元的误差项的值都是0;
(2)mean pooling层:对于mean pooling,下一层的误差项的值会平均分配到上一层对应区块中的所有神经元。
- 普通池化:
参考链接:https://blog.csdn.net/Jason_yyz/article/details/80003271
![]()



上图中,第二行中表示后一层中所计算梯度均为1,故传递至输入中为1,其余位置均为0。以下所有图示中后一层反向输入的梯度均默认为1。
- RoI 池化

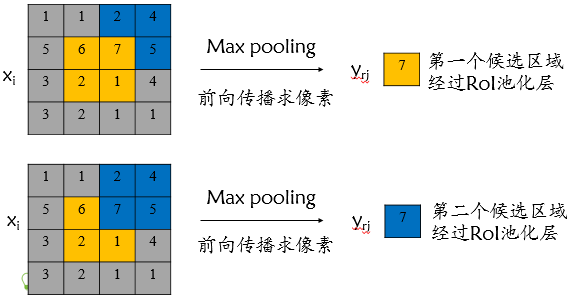
![]()


与YOLOV3对比:
YOLOV3在原来的基础上也集成了Faster R-CNN一个位置选多个anchors的方法,在s*s的网格上,每个网格选取K个候选框,这是YOLOV3借鉴到的地方,两个框架很相似了,只不过YOLOV3没有使用RPN提取候选框,而是直接在网格上做预测。
参考文章:
https://blog.csdn.net/liuxiaoheng1992/article/details/81843363
https://blog.csdn.net/xunan003/article/details/86597954
https://www.jianshu.com/p/4d6b544807bd
