1. VGG
(1)卷积层串联
两个3*3卷积层的串联相当于1个5*5的卷积层,三个3*3的卷积层串联相当于1个7*7的卷积层
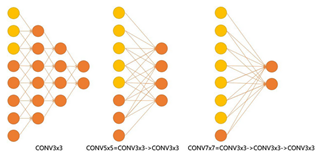
3个3*3卷积层的感受野大小相当于1个7*7的卷积层。但是3个3*3的卷积层参数量只有7*7的一半左右,同时前者可以有3个非线性操作,而后者只有1个非线性操作,这样使得前者对于特征的学习能力更强。
(2)1*1卷积
- 1*1的卷积层常被用来提炼特征,即多通道的特征组合在一起,凝练成较大通道或者较小通道的输出,而每张图片的大小不变。
- 1*1的卷积神经网络还可以用来替代全连接层。
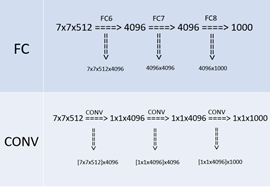
全连接转卷积:测试阶段将训练阶段的三个全连接替换为三个卷积,测试重用训练时的参数,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入
(3)网络结构
VGGNet包含很多级别的网络,深度从11层到19层不等,比较常用的是VGGNet-16和VGGNet-19。VGGNet把网络分成了5段,每段都把多个3*3的卷积网络串联在一起,每段卷积后面接一个最大池化层,最后面是3个全连接层和一个softmax层。
2. GoogleNet-Inception
2.1 Inception V1
- 由于信息位置的巨大差异,为卷积操作选择合适的卷积核大小就比较困难。信息分布更全局性的图像偏好较大的卷积核,信息分布比较局部的图像偏好较小的卷积核。
- 降低算力成本,在 3x3 和 5x5 卷积层之前添加额外的 1x1 卷积层,来限制输入信道的数量。要注意,1x1 卷积是在最大池化层之后,而不是之前。

2.2 Inception V2 / V3
当卷积不会大幅度改变输入维度时,神经网络可能会执行地更好。过多地减少维度可能会造成信息的损失,这也称为「表征性瓶颈」。
- 将 5×5 的卷积分解为两个 3×3 的卷积运算以提升计算速度。
- 将 n*n 的卷积核尺寸分解为 1×n 和 n×1 两个卷积。增加了网络的非线性,减小过拟合的概率。

2.3 Inception-V4 / Resnet
inception结构加上了resnet结构
2.4 Xception
在Inception模块中,从跨通道的关系看,先是由一系列1*1的卷积把输入映射为3到4个通道数少的特征图,然后从跨空间的角度看,再用3*3或者5*5的卷积对这些特征图进行映射。
Inception之后的一个假设是跨通道的关系和跨空间的关系可以被充分地解耦合,这比起同时映射跨通道和跨空间而言更可取。那么问题来了,1*1的卷积映射为多少个小的特征图比较好呢?极端的情况下,就是先用1*1的卷积映射跨通道的关系,然后每个通道进行独立地空间关系的映射。
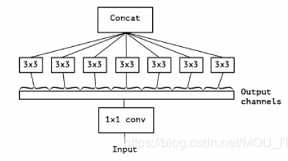
极端情况的Inception和深度可分离卷积非常相似了,深度可分离卷积先是对每个通道独立进行跨空间的卷积,然后接着是跨通道的卷积(通常是一个1*1的卷积)来映射跨通道的关系。
极端情况的Inception模块和深度可分离卷积的区别如下:
- 顺序不一样,深度可分离卷积是逐通道跨空间卷积,然后才是1*1的跨通道卷积,而Inception极端情况恰好相反;
- Inception的极端情况中两种卷积之后都有激活函数ReLU,而深度可分离卷积逐通道跨空间卷积之后没有激活函数ReLU。
- 极端情况的Inception模块的形式为: Conv(1*1) + BN + ReLU + Depthconv(3*3) + BN + ReLU;而深度可分离卷积的形式为:Depthconv(3*3) + BN + Conv(1*1) + BN + ReLU。
补充说明:
一般的卷积如下图(a),而depthwise separable convolution分成两步,一步叫depthwise convolution,就是下图的(b),另一步是pointwise convolution,就是下图的(c)。

3. Residual结构
(1) ResNet
网络的深度提升不能通过层与层的简单堆叠来实现。由于臭名昭著的梯度消失问题,深层网络很难训练。因为梯度反向传播到前面的层,重复相乘可能使梯度无穷小。结果就是,随着网络的层数更深,其性能趋于饱和,甚至开始迅速下降。
ResNet 的核心思想是引入一个所谓的「恒等快捷连接」(identity shortcut connection),直接跳过一个或多个层

(2) ResNeXt
- 不同路径的输出通过相加合并,而在inception中它们是深度级联(depth concatenated)的。
- Inception中的每一个路径互不相同(1x1、3x3 和 5x5 卷积),而在 ResNeXt 架构中,所有的路径都遵循相同的拓扑结构。

(3) DenseNet
如果卷积网络在接近输入和输出段的层之间包含较短的连接,那么,该网络可以显著地加深,变得更精确并且能够更有效地训练。
网络架构中,两个层之间都有直接的连接,因此该网络的直接连接个数为(L+1)* L / 2。
每一层,使用前面所有层的特征映射作为输入,并且使用其自身的特征映射作为所有后续层的输入。


4. SENet
对通道间的依赖关系进行建模,可以自适应的调整各通道的特征响应值。

给定一个输入x,其特征通道数为c_1,通过一系列卷积变换后得到一个特征通道数为c_2的特征。
通过三个操作来重标定前面得到的特征:
- 首先是Squeeze操作,顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。使用global average pooling作为Squeeze操作
- 其次是Excitation操作,它是一个类似于循环神经网络中门的机制。通过参数 来为每个特征通道生成权重,其中参数 被学习用来显式地建模特征通道间的相关性。两个Fully Connected 层建模通道间的相关性,首先将特征维度降低到输入的1/16,再通过一个Fully Connected 层升回到原来的维度。这样做的好处在于:1)具有更多的非线性,可以更好地拟合通道间复杂的相关性;2)极大地减少了参数量和计算量。
- 最后是一个Reweight的操作,我们将Excitation的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。通过一个Sigmoid的门获得0~1之间归一化的权重,最后通过一个Scale的操作来将归一化后的权重加权到每个通道的特征上。

