用作记录一些模型的设计构思。
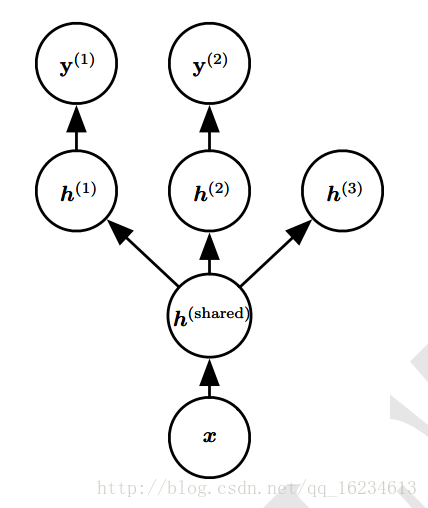
多任务学习,该模型底层存在三个任务x1,x2,x3。每个任务意义不同,甚至维度,分布都不同。但顶层输出变量y具有相同意义,上层结构是共享的。由于上层共享参数,最终导致低层结构学习的是将每个特定任务转化处通用的特征供上层使用。
举例:语音识别,语种的存在导致不同的发音,但最终学得的是相同语义的特征表示。

多任务学习,在某些类似任务中,某些低层概念是类似的,如边缘、光照变化、几何变化等。低层共享可以提高统计强度,改变泛化能力。
举例:任务1学习猫狗,任务2学习蚂蚁蜜蜂。
编码解码器,深度网络很多模型是通过非线性函数对原有的样本空间进行映射,从而达到在映射空间的可分性。编码器将原有样本映射到状态向量C中,而解码器通过对C的解读,输出一种与输入含义近似的输出。
举例:比如英语"good"和汉语"好",虽然不同,但表达的深层意思类似,如果将good映射到一个C变量,然后解码器对C变量转化成汉语中的"好"。从而实现机器翻译。
滑动平均,上式u(t-1)表示过去状态,v(t)表示当前可用于更新状态值,而alpha就是用于控制u(t-1)和v(t)信息量汇入到u(t)的比例,如果alpha接近1,表示模型更看重历史信息,如果接近0,表示更看重当前信息。从而控制模型的记忆能力。
举例:GRU,LSTM, 优化算法Momentum等。
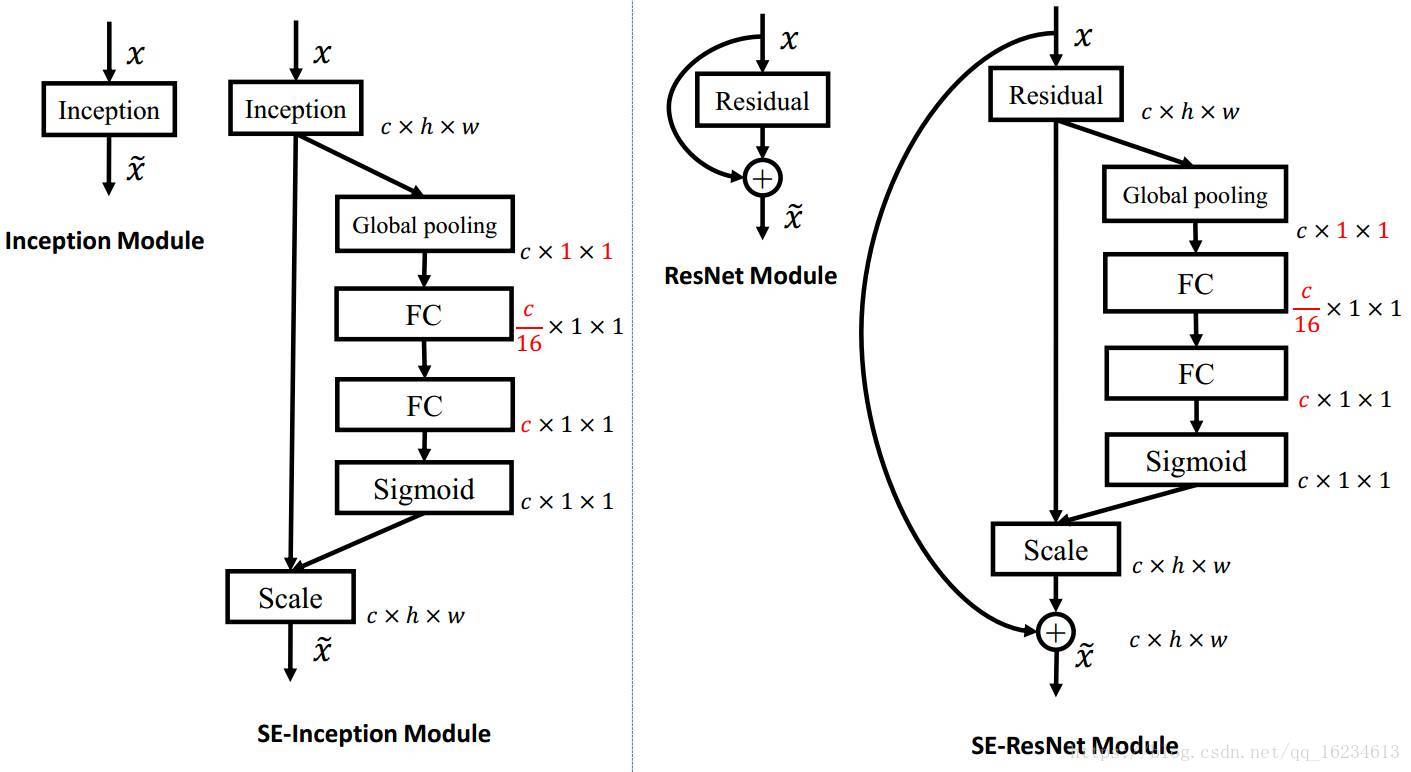
SeNet,显式地建模特征通道之间的相互依赖关系。顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野。将softmax输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。类似于在通道数上添加attention机制,并且使用每个feature map的通道来获得全局视野。
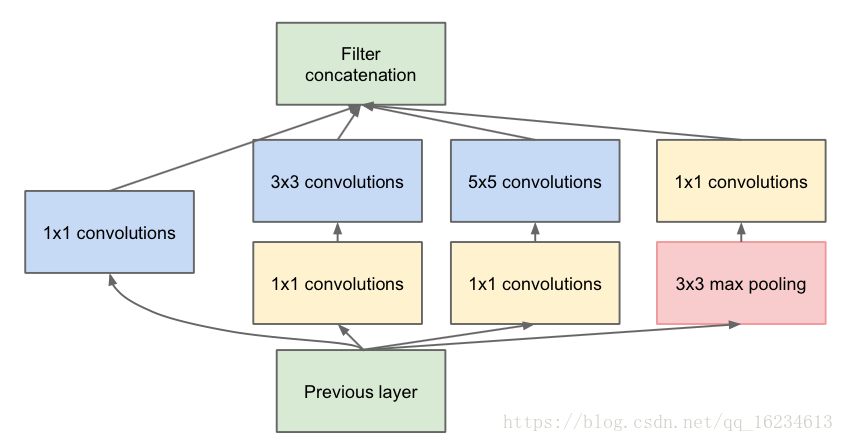
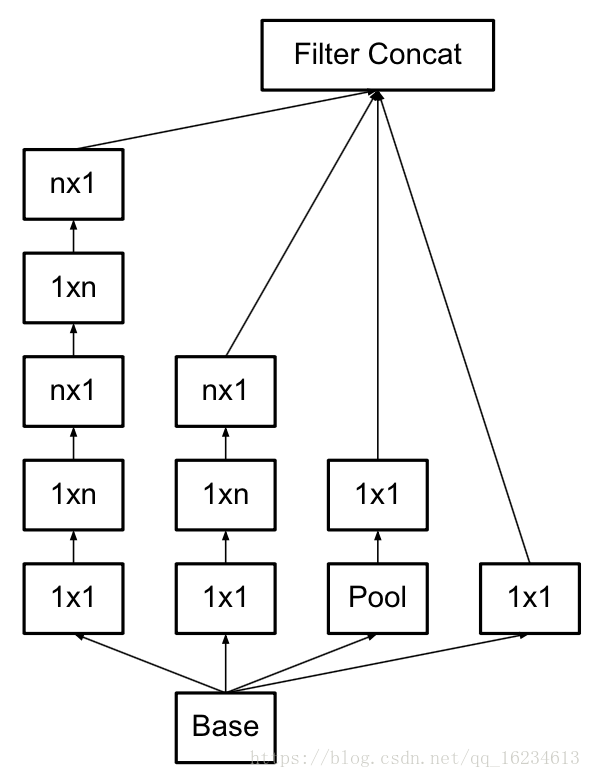
Inception,通过使用不同kernel-size来获得不同尺度的感受野。11的conv类似线性变换,然后分别使用33、55的核。后来进一步发展成用两个33代替55,用15和51代替55。
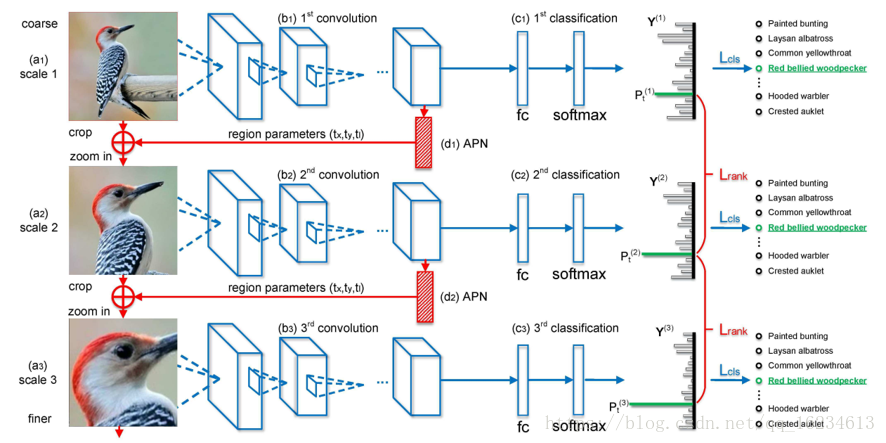
RA-CNN(Recurrent Attention):与一般的attention机制输出概率不同,该attention回归出模型认为存在重点关注特征的坐标位置,将其裁剪放大后继续放入模型进行预测。模型存在两种loss:classification loss和ranking loss。
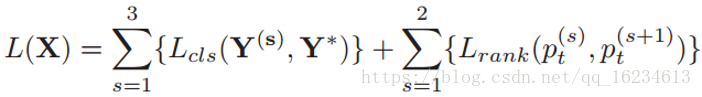
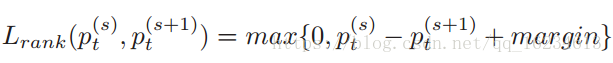
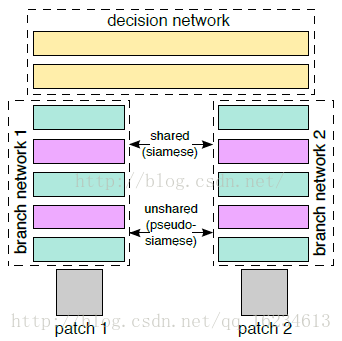
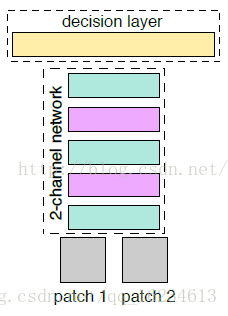
Siamese和2-channel:计算两张图像的相似度,siamese有两个分支,可以共享权重(siamese)或不共享权重(pseudo siamese)。通过分别输入图像后计算提取特征后计算二者相似度。2-channel在siamese上提出改进,将两者图像叠加后同时输入。且在后来处理上将6464的图像才成2个3232实现多尺度输入。

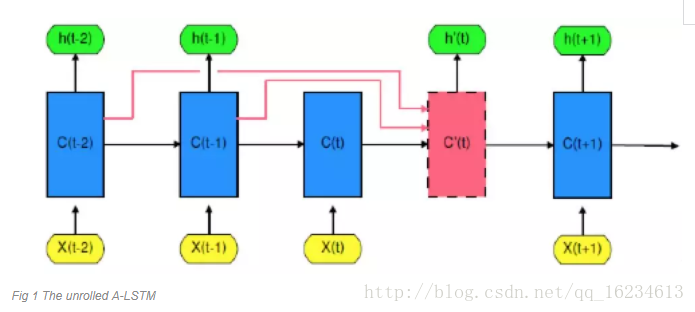
A-LSTM:在LSTM中将前几个单元的输出同样输入到当前单元,实现历史信息的传递。在传递过程中使用注意力机制来控制信息量。
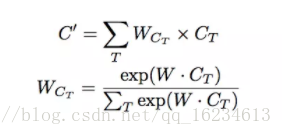
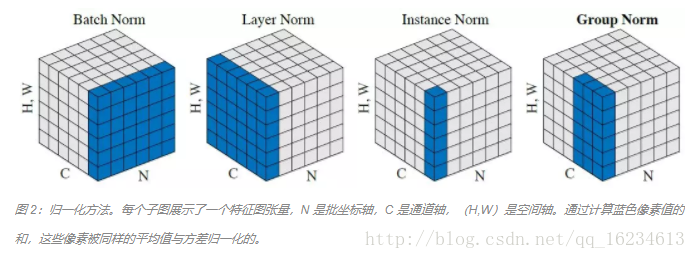
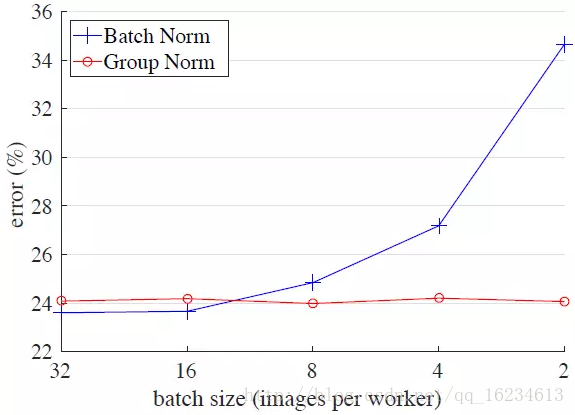
BN-LN-IN-GN:看图归一化
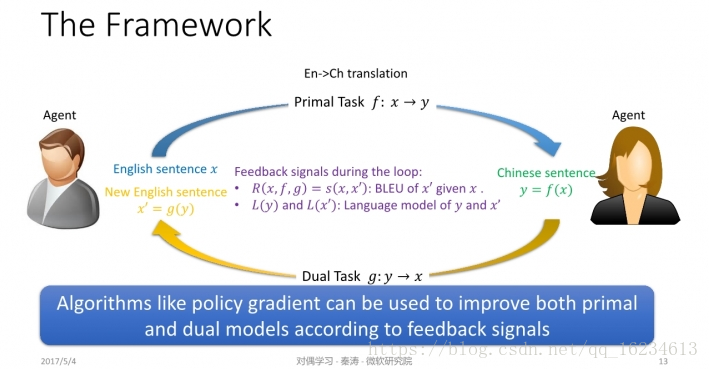
Dual Supervised Learning:对偶学习,以图为例,英语句子x,通过模型f翻译成中文y,然后将y输入模型g,翻译成x’。在此过程中有三个损失函数:agent对中文句子y进行语法等规则评判,另一个agent对生成的x’语句进行评判,以及x和生成的x’之间的重构误差。采用policy gradient策略,即如果模型预测获得了好的奖励,则继续扩大这种可能性,反之,如果获得反馈不好,则减小这种概率。
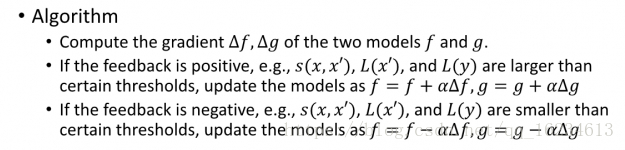
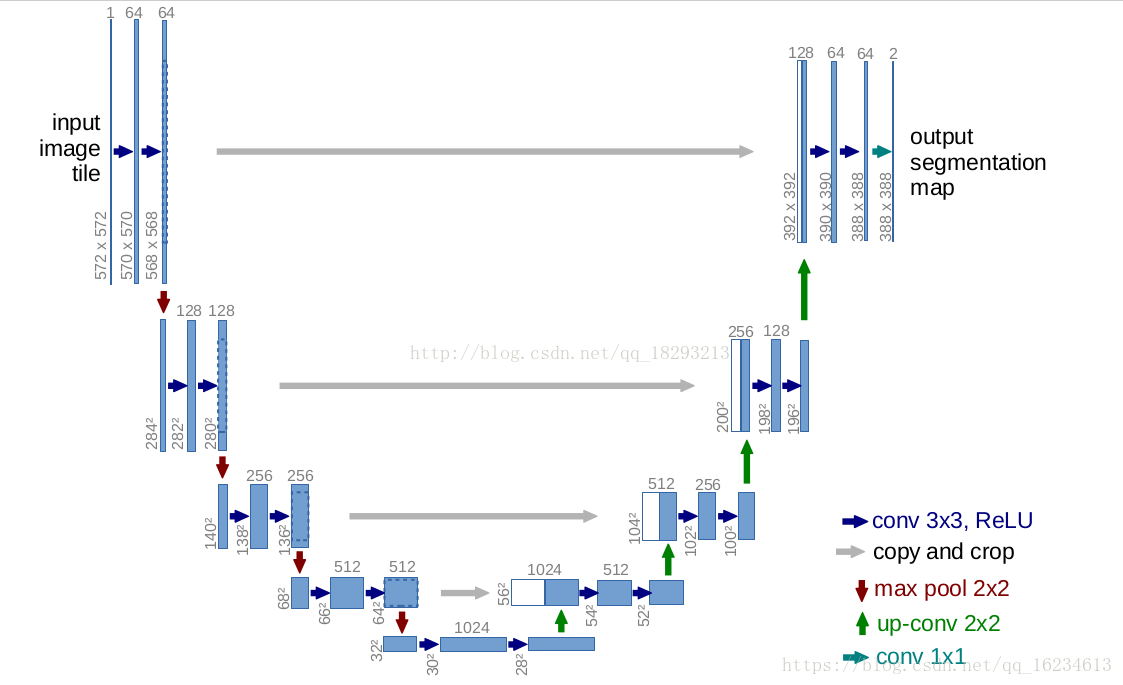
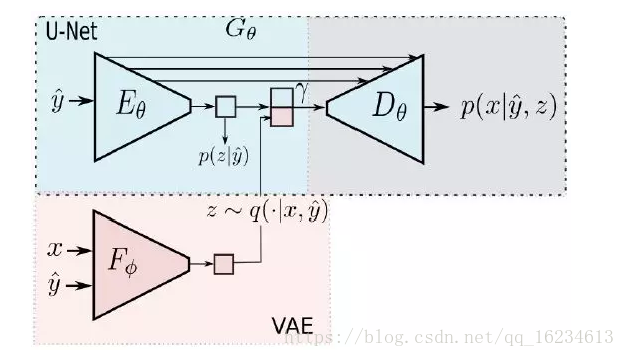
变分U-Net:U-Net常用于图像分割,其的强处在于对各个尺度的信息的利用。一直将底层的特征不断加入到高层。上图y hat是物体形状信息,x是输出图像。多加了个变分模块生成外观信息z。
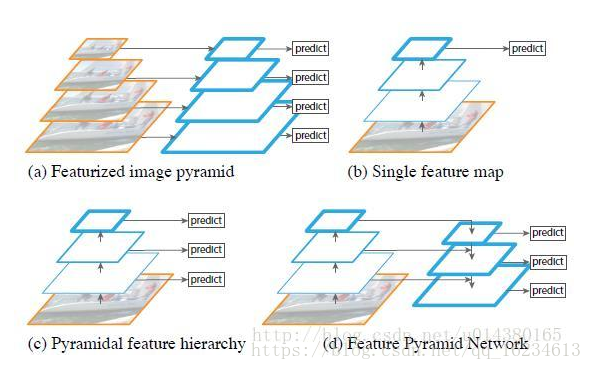
如何利用不同尺度特征:底层特征语义信息较少,但目标位置精确,顶层特征语义丰富,但定位粗糙。(a)使用不同大小的图像输入模型。 (b)使用模型的最后一层特征,SPP net,Fast RCNN,Faster RCNN采用的都是这种方式。 ©自底向上对不同尺度的特征分别预测,SSD采用此法 (d)自顶向下对不同尺度的特征分别做预测,为了在底层的同时利用顶层信息,对顶层特征进行上采样以获得同等大小。FPN,FCN使用此类思想。
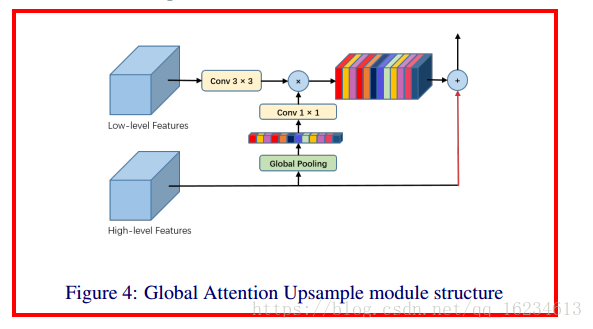
GAU:全局注意力上采样,在使用金字塔特征进行上采样时加入注意力机制,使用高层全局特征信息对底层特征在组合时进行筛选。
对抗+强化学习的对话模型:融入了对抗学习的思想。将Agent生成回复的过程看成是一个生成器,并使用额外的判别器来生成reward,判别数据集中真实的客服与用户的对话与系统生成的对话之间的“真”与“假”。将生成器与判别器进行对抗学习,生成器的目标是生成“以假乱真”的样本迷惑判别器,判别器的目标是尽可能的判别真实的数据与生成的样本。当模型训练好之后,就能像真正的客服一样回复用户了(理想状态下)。
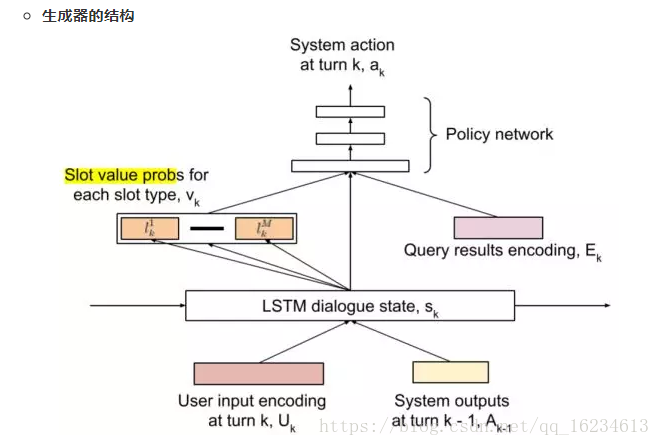
生成器的模型如上图所示,Agent使用一个LSTM来进行序列建模。在每轮对话中,用户的输入和系统上一轮的输出首先被编码成向量表示。在生成隐层状态之后,可以对它进行进一步计算,得到用户的目标的表示(Slot Value)。以订餐的任务而言,slot 的类型可以是“菜系”、“地点”、“时间”等。如“五道口东来顺,今天六点,两个人的位子”就可以提取出(place=五道口),(restaurant=东来顺),(time=6pm)等slot-value对。除此之外,生成回答时,还需要从额外的数据库中查找对应的信息,如订餐的任务,首先要查找该餐馆对应时间还有没有空余的座位等,查询的结果经过编码之后,用Ek表示。将slot value Vk LSTM 的输出状态Sk,查询结果Ek输入到策略网络(Policy Network),即可从回复的候选池中选择回复。在这里,Policy Network使用的是单层感知机,输出一个softmax,即系统中每个可能的回复的概率。
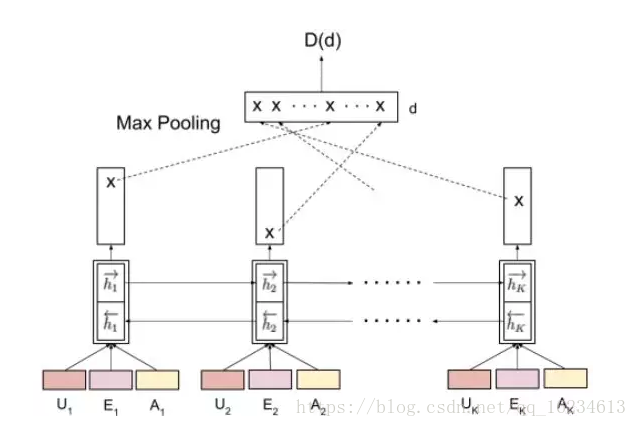
在一组多轮对话的任务完成之后,接下来就依靠判别器对整个回复的过程进行判别,生成reward。首先将对话过程中每一轮的用户的话,系统中检索到的结果,系统的回复输入到一个双向LSTM中,并取结果中的LSTM最终输出、max-pooling(将输出向量中每一维最大的拼接起来),Average-pooling(输出向量每一维的平均),attention(每一维按照计算得到的attention加权)等方式组成最后的输出向量,判别最后的结果。–来自专知
相似性度量方法和学习:
度量学习 度量函数 metric learning deep metric learning 深度度量学习
近邻成分分析(Neighbourhood Components Analysis):学习低维的距离度量
siamese网络:孪生网络
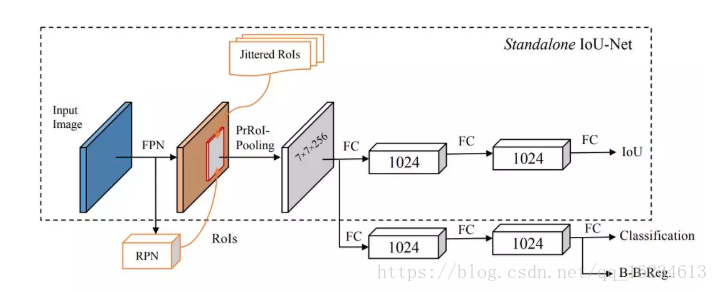
IoU-Net:在以前的目标检测中,通常使用分类置信度作为NMS的判定标准,但文章认为分类置信度是识别类别,而不是为了判定目标框。这使得其缺少解释性,且存在偏见。IoU 是定位准确度的一个天然标准。研究者可以使用预测得到的 IoU 替代分类置信度作为 NMS 中的排名依据。这种技术被称为 IoU 引导式 NMS(IoU-guided NMS),可消除由误导性的分类置信度所造成的抑制错误。

softmax损失函数的可视化图像
特征组合方式(如图像特征和语言特征的组合):
concatenation, elementwise multiplication, or elementwise addition
bilinear pooling or related schemes
compute spatial attention maps
for the visual features or that adaptively scales local features based on their relative importance
Using Bayesian models that exploit the underlying relationships between questionimage-answer feature distributions
Unified Perceptual Parsing:统一感知解析定义了一个新的task:根据同一张图像同时理解场景,目标,材质,纹理。UPerNet根据CNN不同深度的语义特征做不同任务。如果高层特征用于场景分类;低层特征的用于文理识别。

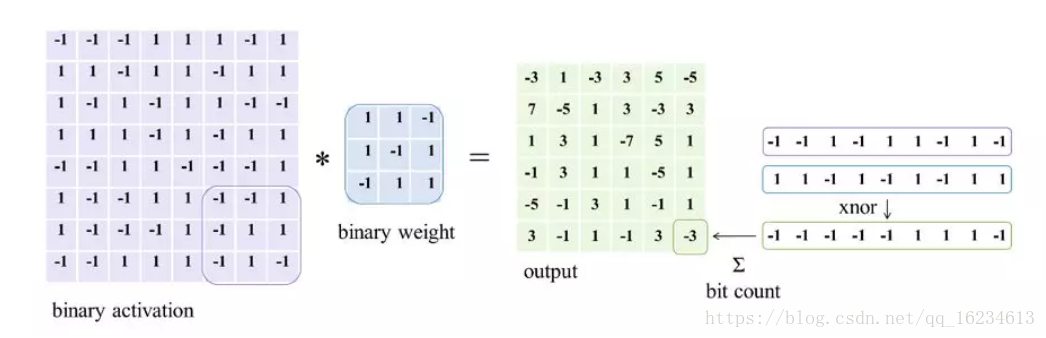
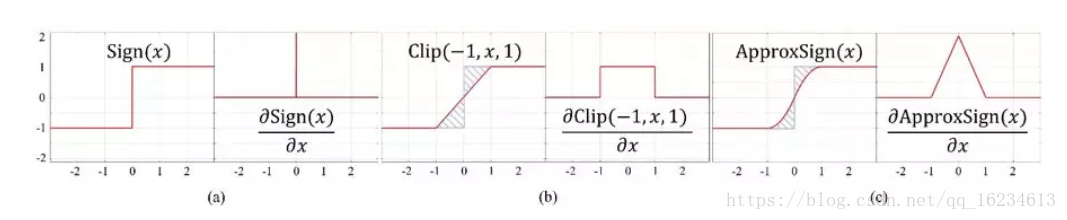
二值网络:参数和特征都用1或-1表示,专门用于压缩网络大小。模型有XNOR-net、Bi-Real net等;Bi-Real net是对XNOR-net的改进。改进点有1、XNOR-net在xnor和bitcout后出现实值,但强行进行-1、1处理导致信息丢失。提出在二值化前将这些实值特征图shortcut传递出去,从而保留信息。2、由于使用sign二值化,而sign无法可导,因此以前是使用Clip来拟合sign的导数,但这样模型在前向过程中看到的是sign,后向过程看到的是clip,存在一个导数差异的问题。因此作者使用一个二阶拟合Sign的ApproxSign的导数来作为反向导数,减小了这种差异性。文章细节思路很好,可用于借鉴思考。
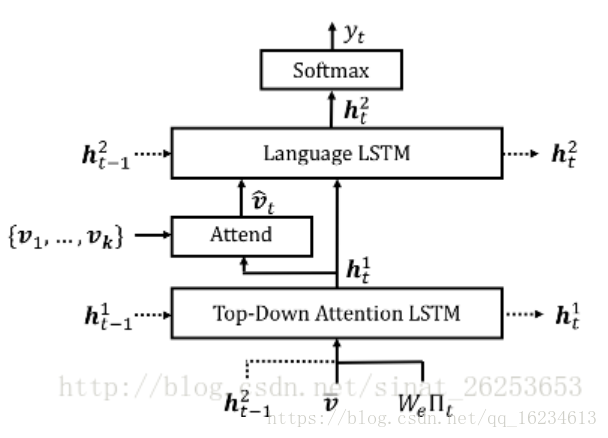
Bottom-Up and Top-Down Attention:这个模型主要用于视觉问答和图像标注之类的结合图像和NLP的task。第一张图为Bottom-Up attention,其实就是使用Faster R-CNN提取区域进行分类,由于提取出来的是一个个目标区域,可以认为比全局更为底层。提取出来的局部特征经过全局均值池化后形成k个特征Vi。第二张图里有Top-Down attention模块,可以看到这个LSTM模块输入的是语言LSTM的t-1隐状态、k个vi的均值(可以认为是图像的全局信息)和当前t时刻的词向量,输出的是t时刻隐状态,用于和k个区域图像特征生成关于v的attention,从而输出到语言LSTM中。有意思的是可以看到这两个LSTM在互相使用彼此的信息。