ResNet在2015年被提出,在ImageNet比赛classification任务上获得第一名(VGG是ImageNet2014年)在之前的VGG介绍中说过网络的深度对模型识别的准确度有很大的影响,但是在实际训练过程中,如果网络深度过深的话会引起在训练过程中发生退化的问题。为此我们的ResNet克服了这个困难
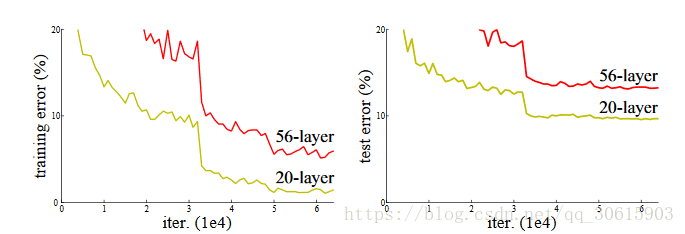
深度影响
随着网络的深度增加学习能力增强,但是如果单纯的增加网络的深度就发生梯度消失或者梯度爆炸。在另一方面退化问题上,更深的模型不应当产生比它更浅的模型更高的错误率。而这个“退化”是因为在模型变复杂时,随机梯度下降的优化变得更加困难,导致了模型达不到好的学习效果。为此论文中提出了Block结构
Block结构
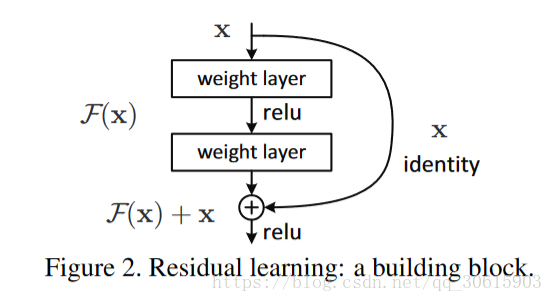
上图就是block结构,在深层网络添加了一个恒等映射,将原始所需要学的函数H(x)转换成F(x)+x,那么模型就退化为一个浅层网络。可以明显的看出直接拟合一个潜在的H(x) = x,比较困难,这可能就是深层网络难以训练的原因。为此使用H(x) = F(x) + x就可以将其转换为学习一个残差函数F(x) = H(x) - x. 只要F(x)=0,就构成了一个恒等映射H(x) = x,所以优化F(x)肯定要比H(x)要容易。
对于block中的shortcut需要注意
A. 使用恒等映射,如果residual block的输入输出维度不一致,对增加的维度用0来填充;
B. 在block输入输出维度一致时使用恒等映射,不一致时使用线性投影以保证维度一致;
C. 对于所有的block均使用线性投影。
这个Residual block通过shortcut将这个block的输入和输出进行加叠,这个简单的加法并不会给网络增加额外的参数和计算量,同时却可以大大增加模型的训练速度、提高训练效果。这样就保证了我在增加网络深度的时候模型的效果起码不会变差
实验
论文中先建立了一个18层和一个34层的普通罗列的CNN,随后又分别建立了同样大小的残差网络,在原来的plain长加入了shortcut,在这两个网络参数完全相同的情况下与之前的vgg19 模型比计算量要少了许多。
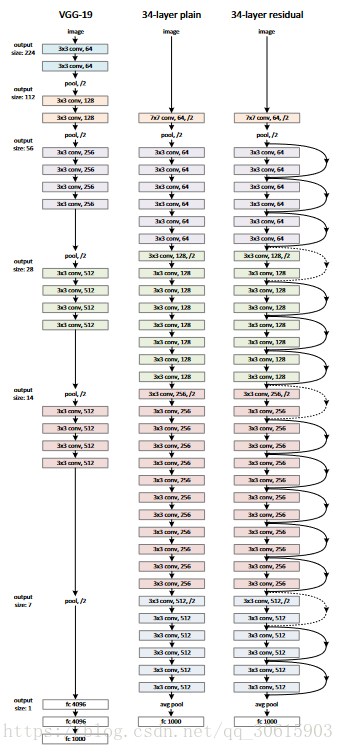
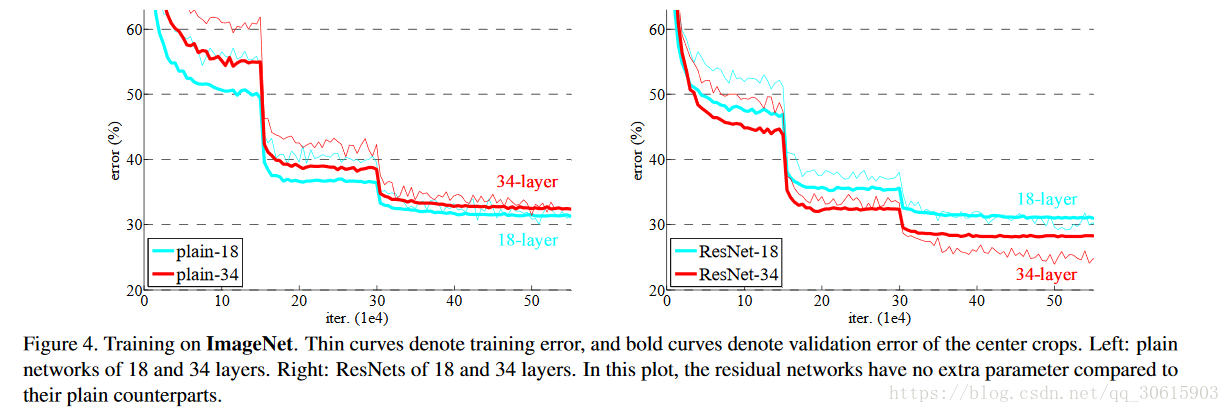
在观察实验结果后发现在不使用残差结构的时候观测到模型曾深层次明显出现的退化,反观ResNet没有出现退化而且效果比18层的更好,同时收敛速也更快。
总结
1、plain-18和plain-34的实验证明了退化问题不是因为梯度弥散,因为加入了BN。而且单纯的增加迭代次数要同样会导致模型退化。
2、实验了ResNet-18和ResNet-34,ResNet-34效果远远优于ResNet-18和plain-34,证明了残差结构解决了退化的问题。 而且同等深度的plain-18和ResNet-18,残差网络收敛更快。
3、对于同等映射维度不匹配时有两种匹配维度的方法
零填充和线性投影。作者比较了这两种方法的优劣。实验证明,投影法会比zero padding表现稍好一些。因为zero padding的部分没有参与残差学习。实验表明,将维度匹配或不匹配的同等映射全用投影法会取得更稍好的结果。
4、更深的瓶颈结构:
将原来的block(残差学习结构)改为瓶颈结构。首端和末端的1x1卷积用来削减和恢复维度,只剩下中间3x3作为瓶颈部分。这两种结构的时间复杂度相似。但是此时投影法的参数出现了输入维度增加,所以要使用zero padding的同等映射。为此网络深度可以继续增加,性能不断提升,最后在1202层的时候,发现网络过深,出现了过拟合