概述
DenseNet是CVPR2017的最佳论文,主要是以ResNet为基础,在此之上进行改进优化,借鉴了ResNet的核心思想提出了全新的dense block结构。如果说ResNet是以网络深度取胜的话,那么denseNet则是以对特征入手,得到了更好的结果。
DenseNet的核心思想来源于随机深度网络,经研究发现在训练过程中的每一步都随机地丢掉一些层,可以显著的提高 ResNet 的泛化性能。也就是说神经网络不一定非得是一个层级结构,在网络中的每一层与上一层的依赖关系也就可以重新修改,让他可以依赖更前面几层的信息。
在训练过程随机丢掉几层没有影响收敛,也就意味着原来的ResNet是存在冗余的,因为ResNet的独特残差结构使得网络的每一层实际上只提取了很少的特征。
DenseNet结构

在传统的卷积神经网络中,一般情况下连接数和层数是保持一致的,若果有 L 层那么就会对应的存在L个连接,但是在DenseNet中,从上面dense block的结构图我们可以看出,当前层的输入是依赖于前面所有层的,而且他的输出也会被映射到后续的层中,所以会有
个连接。
通过两个公式可以看出ResNet和DenseNet的区别
DenseNet中的 表示将0到i-1层的输出 就是上面提到的深度级联concatenation。concatenation是做通道的合并,就像(Google的盗梦空间网络)Inception那样。而前面resnet是做值的相加,通道数是不变的。
过渡层
concatenation串联操作会出现通道数改变的现象,然而在CNN中有conv和pooling层可以下采样进行降维。论文引出过度层(Transition Layer)级联多个dense block,希望将每个dense block内的feature map的size最后能统一,这样在进行concatenation时就不会有size不统一的问题。过度层是由1*1的conv和2*2的pooling层组成

另外这些特征通过depth concatenation深度级联连接在一起可以使网络能够支持“特征重用”提高了参数的利用率,也增加网络输出的多样性
增长率
DenseNet使用“增长率”(k)防止网络变得过宽,如果每个复合函数H输出k个feature map,那么第 ℓ 层有 个输入 ,其中 是输入层的通道数,论文里面将k称为 Growth rate。DenseNet和resnet相比的一个优点是设置很小的k值,使得网络更窄从而参数更少。在 dense block中每个卷积层的输出feature map的数量k都很小(小于100),而不是像其他网络一样动不动就几百上千的宽度。另外论文还观察到这种denseblock有正则化的效果,因此对于过拟合有一定的抑制作用,我认为主要是网络通道更窄使得参数减少了,所以过拟合现象减轻。
瓶颈层
论文在每个dense block中3*3的conv(卷积)层前面引入1*1的conv层,就是所谓的bottleneck layer,目的是减少输入的feature map数量,既能降维减少计算量,又能融合各个通道的特征。称之为Densenet-B结构。
压缩
为了提高模型的紧密性,论文在过渡层中减少feature map的数量,引入一个参数 ,假设一个dense block输出的feature map是m个,在过渡层引入 后输出的feature map就是 个,0< <1,论文中 取0.5,当 <1时称为其结构为Densenet-C。
因此可以看出DenseNet的优点就是通过使用dense block让网络更窄,参数更少,从block出来的feature map与其他网络相比宽度是很小的。同时这种连接方式使得特征和梯度的传递更加有效,网络也就更加容易训练。梯度消失的主要原因就是因为网络加深原因就是输入信息和梯度信息在很多层之间传递导致的,而DenseNet的dense connection相当于每一层都直接连接input和loss所以就可以解决这种问题。
DenseNet优点
- 减轻了vanishing-gradient(梯度消失)
- 加强了feature的传递
- 更有效地利用了feature
- 一定程度上较少了参数数量
网络参数设置
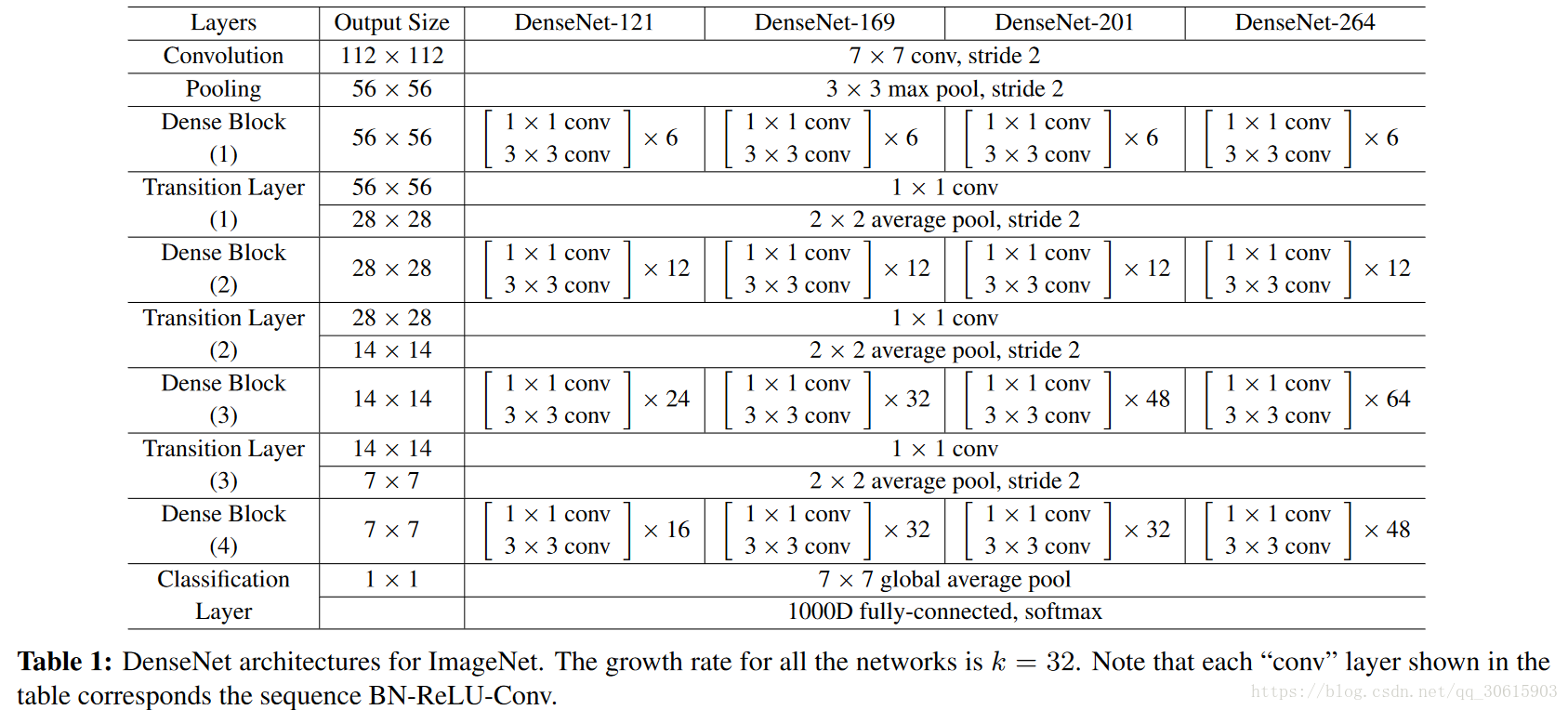
实验
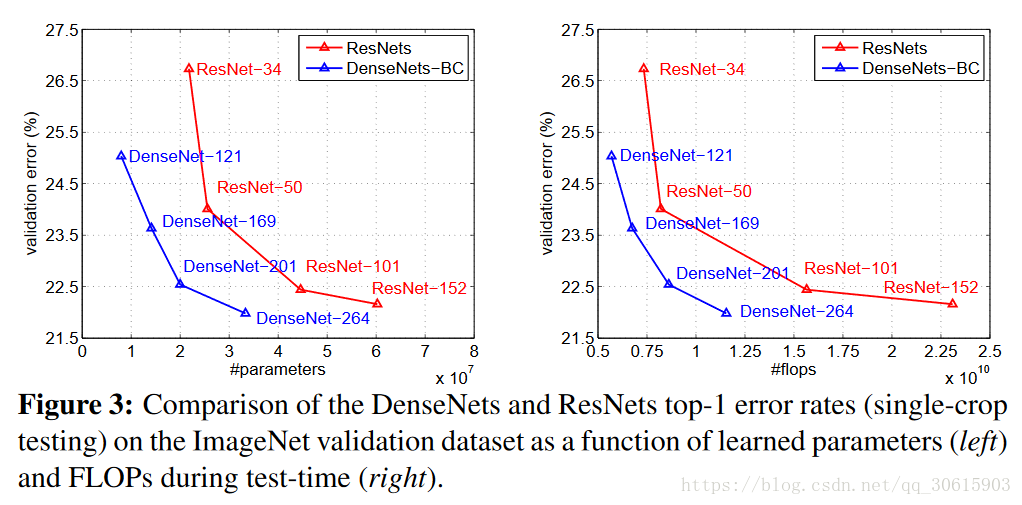
下图是DenseNet-BC和ResNet在Imagenet数据集上的对比,作图是参数复杂度和错误率的对比,你可以在相同错误率下看参数复杂度,也可以在相同参数复杂度下看错误率,效果有明显的提升,右侧为计算复杂度和错误率的对比。
参考
https://blog.csdn.net/xjz18298268521/article/details/79078337
https://blog.csdn.net/malele4th/article/details/79429028
https://blog.csdn.net/u014380165/article/details/75142664