Very Deep Convolutional Networks for Large-Scale Image Recognition
在图像识别这一方面ImageNet挑战赛会定期产出优秀的模型从最初的AlexNet到VGG,RESNet,再到最新的DenseNet。每一次诞生出新的网络都会带来一次革新,今天要说的是VGG网络,ResNet和DenseNet会在接下来几篇介绍
VGG模型是2014年ILSVRC竞赛的第二名,第一名是GoogLeNet。但是VGG模型在多个迁移学习任务中的表现要优于googLeNet。而且,从图像中提取CNN特征,VGG模型是首选算法。它的缺点在于,参数量有140M之多,需要更大的存储空间。但是这个模型很有研究价值。
这篇论文的主要价值在于,他提出了卷积神经网络的深度增加和小卷积核的使用对网络的最终分类识别效果有很大的作用。后两个网络对卷积核的开刀的优化方法也证明了这一观点。
在论文的实验中,证明了在大规模图像识别任务中卷积神经网络的深度对准确率的影响。主要的贡献是利用带有很小卷积核(3*3)的网络结构对逐渐加深的网络进行评估,结果表明通过加深网络深度至16-19层可以极大地改进前人的网络结构。网络结构如下
网络结构
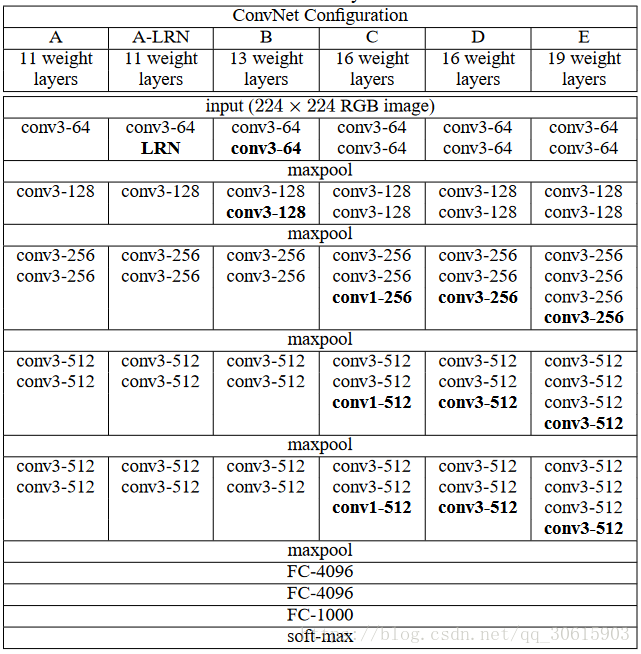
网络参数设置
- 输入为的经过去均值处理的224x224大小的RGB图片。
- 卷积核大小均是3x3,步长为1(stride = 1)Padding 为 1。
- 池化层均采用max pooling,但不是所有的卷积层都有池化层,池化窗口为2x2,步长为2。
- 所有隐藏层都接上ReLU层

讨论选用3x3卷积核的原因
2个3x3的卷积核串联和用一个5x5的卷积核有相同的感知野,3个3x3的卷积核串联和用一个7x7的卷积核有相同的感知野,因此发现采用3x3的可以减少参数数量
假设输入feature map的大小为32x32x3(宽 x 高 x 通道数)
如果采用1个5x5的卷积核
,输出特征图的大小等于:
参数的数量为
个(每个通道25个,共3个通道)
如果采用2个3x3的卷积核,
, 输出大小等于:
,第二次卷积输出特征图的大小等于:
,总参数的数量为
个(每个通道9个,共3个通道,2个卷积层),比单独使用一个5*5的卷积核少了21个。
1*1 卷积核的作用
在不影响感受野的情况下,增加模型的非线性性
1x1卷机相当于线性变换,非线性激活函数起到非线性作用
网络深度对结果的影响(同年google也独立发布了深度为22层的网络GoogleNet)
深度对模型效果的影响
VGG与GoogleNet模型都很深都采用了小卷积
VGG只采用3x3,而GoogleNet采用1x1, 3x3, 5x5,模型更加复杂(模型开始采用了很大的卷积核,来降低后面卷机层的计算)
模型训练
训练和AlexNet基本相同(除了从多尺度训练图像上采样裁切的输入图像,稍后会解释)。也就是说,通过使用含动量的小批量(mini-batch)梯度下降(基于反向传播)优化多元逻辑回归来对模型进行训练。小批量的尺寸为256,动量为0.9。通过权值衰减(L2惩罚系数设置为5⋅10−4)以及对前两个全连接层执行dropout(dropout比率设置为0.5)来对训练进行正则化。初始学习率设置为10−2,当验证集准确率稳定时将学习率除以10。学习率总共降低了3次,训练一共进行了370K次迭代(74个epoch)。采用2种设置训练图像大小方法:
(1)固定训练集图片大小,如256*256和384*384;
(2)多尺度训练,让训练集的大小在一个范围内随机变化,如S∈[Smin,Smax]=[256,512]
模型测试
两种测试方案:
第一种用来比较使用不同网络修正(即调优方式不同,所有层调优/全连接层调优)在验证集上的区别,只考虑对真实类别的边界框预测(排除了分类错误).只在图像的中心裁切上使用网络来获得边界框。
第二种,完全基于定位卷积网络在整幅图像上密集应用的测试程序。不同的是,最后一个全连接层的输出是由一组边界框的预测取代了分类得分图。为了获得最终预测结果,我们使用了sermanet2013overfeat中的贪婪合并程序,先合并空间上接近的预测(通过计算坐标的平均值),然后使用由分类卷积网络获得的分类得分对他们进行评级。当使用了一些定位卷积网络时,我们首先得到它们对边界框预测的合集,然后在这个合集上运行合并程序。