首先引入相关的库
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
加载数据集
(mnist_images, mnist_labels), _ = tf.keras.datasets.mnist.load_data()
print(type(mnist_images))
print(mnist_images.dtype)
print(mnist_images.shape)
此时可以查看数据集的相关信息:
<class 'numpy.ndarray'>
uint8
(60000, 28, 28)
切分产生dataset
dataset = tf.data.Dataset.from_tensor_slices(
(tf.cast(mnist_images[...,tf.newaxis]/255, tf.float32),
tf.cast(mnist_labels,tf.int64)))
print(dataset)
其中:
mnist_images[…,tf.newaxis] 是指在mnist_images(维度为(60000, 28, 28))后面再加一个维度,即变成(60000, 28, 28, 1)。省略号表示的是很多个冒号,也就是说[…,tf.newaxis]即为[:, :, :, tf.newaxis]。
tf.cast() 的作用是将mnist_images原来的数据类型(uint8)转化为float32。
tf.data.Dataset.from_tensor_slices() 用来将输入按照第一维度进行切分,所以最终得到的dataset为:
<TensorSliceDataset shapes: ((28, 28, 1), ()), types: (tf.float32, tf.int64)>
将dataset打乱、分批
dataset = dataset.shuffle(1000).batch(32)
print(dataset)
得到的dataset为:
<BatchDataset shapes: ((None, 28, 28, 1), (None,)), types: (tf.float32, tf.int64)>
这个操作的目的是,每次调用dataset.take(1)就会得到32个样本的组合,如果调用的时dataset.take(x),则得到的是x个这样的组合。
构建模型
mnist_model = tf.keras.Sequential([
tf.keras.layers.Conv2D(16,[3,3], activation='relu',
input_shape=(None, None, 1)),
tf.keras.layers.Conv2D(16,[3,3], activation='relu'),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(10)
])
先展示一波dataset.take()的作用
for images,labels in dataset.take(2):
print(images.shape)
print("Logits: ", mnist_model(images[0:1]).numpy())
得到:
(32, 28, 28, 1)
Logits: [[-0.01555313 0.02404156 0.01355665 -0.03020764 0.0092129 0.02039536
0.01312329 -0.01198696 0.00587582 0.00114011]]
(32, 28, 28, 1)
Logits: [[-0.03150982 0.04380588 0.02759154 -0.04930525 0.0152742 0.03806124
0.02004753 -0.01281266 0.01789122 0.00325774]]
由此可见,每次得到的要输入模型的样本数都是32个。Logits是取这32个样本中的第一个输入模型时得到的结果。
优化器+损失函数
optimizer = tf.keras.optimizers.Adam()
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
训练过程
loss_history = []
for (batch, (images, labels)) in enumerate(dataset.take(400)):
if batch % 10 == 0:
print('.', end='')
with tf.GradientTape() as tape:
logits = mnist_model(images, training=True)
loss_value = loss_object(labels, logits)
loss_history.append(loss_value.numpy().mean())
grads = tape.gradient(loss_value, mnist_model.trainable_variables)
optimizer.apply_gradients(zip(grads, mnist_model.trainable_variables))
以上涉及梯度带的使用,请参考:Tensorflow中的梯度带(GradientTape)以及梯度更新。
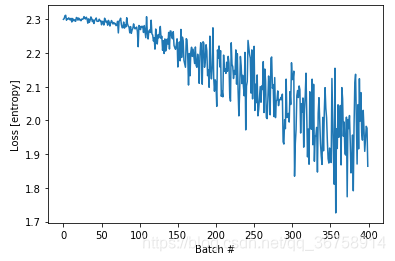
画出损失图
plt.plot(loss_history)
plt.xlabel('Batch #')
plt.ylabel('Loss [entropy]')
plt.show()