1、Keras版本模型训练
1.1 构造模型(顺序模型、函数式模型、子类模型)
import numpy as np
import tensorflow as tf
inputs = tf.keras.Input(shape=(32,)) # 数据维度为32
x = tf.keras.layers.Dense(64, activation='relu')(inputs) # 64个隐藏神经元
x = tf.keras.layers.Dense(64, activation='relu')(x) # 64个隐藏神经元
predictions = tf.keras.layers.Dense(10)(x) # 输出10分类结果
# - inputs:模型的输入
# - outputs:模型的输出
model = tf.keras.Model(inputs=inputs, outputs=predictions)
# 指定损失函数(loss) tf.keras.optimizers.RMSprop
# 优化器(optimizer) tf.keras.SparseCategoricalCrossentropy
# 指标(metrics) ['accuracy']
model.compile(optimizer=tf.keras.optimizers.RMSprop(0.001),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 构造训练集、验证集、测试集
x_train = np.random.random((1000,32)) # 1000条数据,维度为32
y_train = np.random.randint(10, size=(1000,))
x_val = np.random.random((200, 32)) # 200条数据,维度为32
y_val = np.random.randint(10, size=(200,))
x_test = np.random.random((200, 32)) # 200条数据,维度为32
y_te t = np.random.randint(10, size=(200,))
tf2.0提供了许多内置的优化器,损失函数和评价指标。通常不需要从头开始创建自己的损失函数、评价指标或者优化器,因为所需的可能已经是Keras API的一部分。
1.2 模型训练:model.fit()
构造模型后,通过将数据切成大小为"batch_size"的"批"来训练模型,并针对给定数量的"epoch"重复遍历整个数据集。
# help(model.fit) 查看model.fit()的各项功能
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_val, y_val))
上面代码中使用validation_data=(x_val, y_val)表示验证集,其中(x_val, y_val)是一个元组。参数validation_data将Numpy的元组传递(x_val, y_val)给模型,以在每个时期结束时评估验证损失和验证指标。
除了使用参数validation_data传递验证集以外,还可以使用参数validation_split,validation_split允许自动保留部分训练数据以供验证,参数值表示要保留用于验证的数据的一部分,因此应将其设置为大于0小于1的数字。例如,validation_split=0.2表示“使用20%的训练数据作为验证集”,而validation_split=0.6表示“使用60%的数据用于验证”。
验证的计算方法是在进行任何改组之前,对fit调用接收到的数组进行最后x%的采样。
注意,validation_split只能在使用Numpy进行训练时使用。
1.3 模型验证:model.evaluate()
results = model.evaluate(x_test, y_test, batch_size=128)
1.4 模型预测:model.predict()
predictions = model.predict(x_test[:3])
1.5 使用样本加权和类别加权
在模型训练的时候,除了输入数据和目标数据外,还可以在使用时将样本权重或类别权重传递给模型fit。
从Numpy数据进行训练时,通过sample_weight和class_weight参数设置样本权重或者累呗权重。
在数据集训练时,通过使数据集返回一个元组(input_batch, target_batch, sample_weight_batch)。“样本权重”数组是一个数字数组,用于指定批次中每个样本在计算总损失时应具有的权重,它通常用于不平衡的分类问题中(这种想法是为很少见的类别赋予更多的权重)。当使用的权重为1和0时,该数组可以作为损失函数的掩码(完全丢弃某些样本对总损失的贡献)。
“类别权重”字典是同一个概念的一个更具体的实例,它将类别索引映射到应该属于该类别的样本的样本权重。例如,如果在数据中类“0”的表示量比类“1”的表示量少两倍,则可以使用class_weight={0:1,1:0.5}。
下面列举一个Numpy示例,其中使用类权重或样本权重来更加重视第5类的正确分类。
构建模型
import tensorflow as tf
def get_uncompiled_model():
inputs = tf.keras.Input(shape=(32,), name='digits')
x = tf.keras.layers.Dense(64, activation='relu', name="dense_1")(inputs)
x = tf.keras.layers.Dense(64, activation='relu', name='dense_2')(x)
outputs = tf.keras.layers.Dense(10, name="predictions")(x)
model = tf.keras.Model(inputs=inputs,outputs=outputs)
return model
def get_compiled_model():
model = get_uncompiled_model()
model.compile(optimizer=tf.keras.optimizers.RMSprop(learning_rate=1e-3),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['sparse_categorical_accuracy'])
return model
类别加权
import numpy as np
# 构造训练集、验证集、测试集
x_train = np.random.random((1000,32)) # 1000条数据,维度为32
y_train = np.random.randint(10, size=(1000,))
x_val = np.random.random((200, 32)) # 200条数据,维度为32
y_val = np.random.randint(10, size=(200,))
x_test = np.random.random((200, 32)) # 200条数据,维度为32
y_test = np.random.randint(10, size=(200,))
# 类别5:加权
class_weight = {
0:1, 1:1, 2:1, 3:1, 4:1, 5:2, 6:1, 7:1, 8:1, 9:1}
model = get_compiled_model()
model.fit(x_train, y_train, class_weight=class_weight, batch_size=64, epoch=4)
样本加权
# 样本加权
import numpy as np
# 构造训练集、验证集、测试集
x_train = np.random.random((1000,32)) # 1000条数据,维度为32
y_train = np.random.randint(10, size=(1000,))
x_val = np.random.random((200, 32)) # 200条数据,维度为32
y_val = np.random.randint(10, size=(200,))
x_test = np.random.random((200, 32)) # 200条数据,维度为32
y_test = np.random.randint(10, size=(200,))
sample_weight = np.ones(shape=(len(y_train),))
sample_weight[y_train==5] = 2
model = get_compiled_model()
model.fit(x_train, y_train, sample_weight=sample_weight, batch_size=64, epoch=4)
1.6 回调函数
Keras中的回调是在训练期间(在某个时期开始,在批处理结束时,在某个时期结束时等)在不同时间点调用的对象,这些对象可用于实现以下行为:
- 在训练过程中的不同时间点进行验证(除了内置的按时间段验证);
- 定期或在超过特定精度阈值时对模型进行检查;
- 当训练似乎停滞不前时,更改模型的学习率;
- 当训练似乎停滞不前时,对顶层进行微调;
- 当训练结束或超出特定性能阈值时发送电子邮件或在即时消息通知等等;
- 回调可以作为列表传递给model.fit;
1.6.1 EarlyStopping(早停)
- monitor:被监测的数据;
- min_delta:在被监测的数据中被认为是提升的最小变化。例如,小于min_delta的绝对变化会被认为没有提升;
- patience:没有进步的训练轮数,在这之后训练就会被停止;
- verbose:详细信息模式;
- mode:{auto,min,max}其中之一。在min模式中,当被监测的数据停止下降时,训练就会停止;在max模式中,当被监测的数据停止上升,训练就会停止;在auto模式中,方向会自动从被监测的数据的名字中判断出来。
# 早停的应用示例
model = get_compiled_model()
# callbacks相当于list
callbacks = [
tf.keras.callbacks.EarlyStopping(
# 当“val_loss”不再下降时停止训练,'val_loss'为监控的指标
monitor='val_loss',
# “不再下降”被定义为“减少不超过1e-2”
min_delta=1e-2,
# “不再改善”进一步定义为“至少2个epoch”
patience=2,
verbose=1)
]
model.fit(x_train, y_train,
epoch=20,
batch_size=64,
callbacks=callbacks,
validation_split=0.2)
1.6.2 checkpoint模型
在相对较大的数据集上训练模型时,至关重要的是要定期保存模型的checkpoint,最简单的方法是使用ModelCheckpoint回调。
# 模型保存checkpoint示例
model = get_compiled_model()
callbacks = [
tf.keras.callbacks.ModelCheckpoint(
filepath='mymodel_{epoch}', # 模型保存路径
save_best_only=True,
monitor='val_loss',
save_weights_only=True, # 保存模型权重
verbose=1
)
]
model.fit(x_train, y_train,
epoch=20,
batch_size=64,
callbacks=callbacks,
validation_split=0.2)
1.6.3 使用回调实现动态学习率调整
由于优化程序无法访问验证指标,因此无法使用这些计划对象来实现动态学习率计划(例如当验证损失不再改善的时候降低学习率);
但是回调确实可以访问所有指标,包括验证指标!因此可以通过使用回调函数来修改优化程序上的当前学习率,从而实现此模式。实际上,它是作为ReduceLROnPlateau回调内置的。
ReduceLROnPlateau参数:
- monitor:被监测的指标;
- factor:学习速率被降低的因数。新的学习速率=学习速率*因数;
- patience:没有进步的训练轮数,在这之后训练速率会被降低;
- verbose:整数,是否显示信息,0或者1;
- mode:{auto,min,max}其中之一。如果是min模式,如果被监测的数据已经停止下降则学习速率会被降低;如果是max模式,如果被监测的数据已经停止上升则学习速率会被降低;如果是auto模式,方向会被从监测的数据中自动推断处理;
- min_delta:衡量新的最佳阈值,仅关注重大变化;
- cooldown:在学习速率被降低后,重新恢复正常操作之前等待的训练轮数量;
- min_lr:学习速率的下边界;
# 动态调整学习率示例
model = get_compiled_model()
callbacks = [
tf.keras.callbacks.ModelCheckpoint(
filepath='mymodel_{epoch}', # 模型保存路径
save_best_only=True,
monitor='val_loss',
save_weights_only=True, # 保存模型权重
verbose=1
),
tf.keras.callbacks.ReduceLROnPlateau(monitor="val_sparse_categorical_accuracy",
verbose=1,
mode='max',
factor=0.5,
patience=3)
]
model.fit(x_train, y_train,
epoch=20,
batch_size=64,
callbacks=callbacks,
validation_split=0.2)
许多内置的回调函数可用:
- TensorBoard:定期编写可在TensorBoard中可视化的模型日志
- CSVLogger:将损失和指标数据流式传输到CSV文件;
1.7 将数据传递到多输入、多输出模型
在前面的示例中,我们考虑一个具有单个输入(shape的张量(32,))和单个输出(shape的预测张量(10,))的模型,但是具有多个输入或输出的模型呢?
考虑以下模型,该模型具有形状的图像输入(32,32,3),即(height,width,channels)和形状的时间序列输入(None,10),即(timesteps,features)。我们的模型将具有根据这些输入的组合计算出的两个输出:“得分”(形状为(1,))和五类(形状为(5,))的概率分布。
image_input = tf.keras.Input(shape=(32,32,3), name='img_input')
timeseries_input = tf.keras.Input(shape=(20,10), name='ts_input')
x1 = tf.keras.layers.Conv2D(3, 3)(image_input)
x1 = tf.keras.layers.GlobalAveragePooling2D()(x1)
x2 = tf.keras.layers.Conv1D(3, 3)(timeseries_input)
x2 = tf.keras.layers.GlobalAveragePooling1D()(x2)
x = tf.keras.layers.concatenate([x1,x2])
score_output = tf.keras.layers.Dense(1, name='score_output')(x)
class_output = tf.keras.layers.Dense(5, name='class_output')(x)
model = tf.keras.Model(inputs=[image_input, timeseries_input], outputs=[score_output, class_output])
下面绘制这个模型,以便可以清楚知道我们在这里做什么(请注意,图中显示的形状是批处理形状,而不是按样本的形状)。
我们通过tf.keras.utils.plot_model进行可视化操作,在window中直接使用该方法可能会出现一些问题,我们可以通过博客尝试解决这个问题。
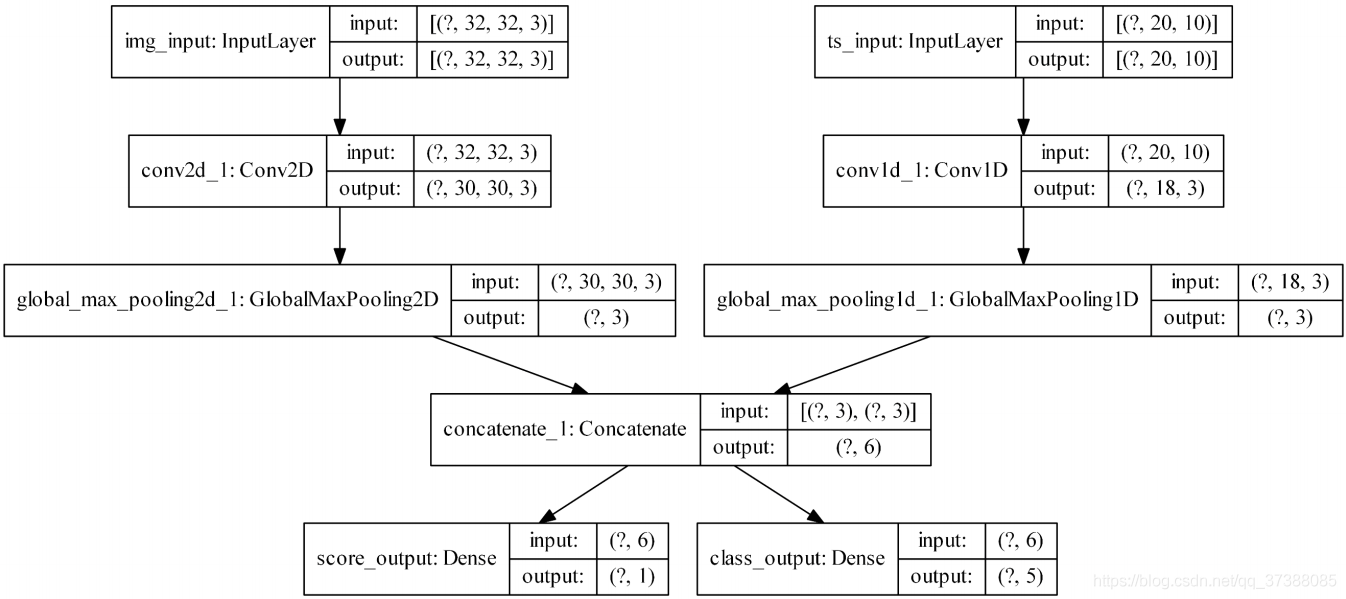
1.7.1 损失函数
在编译时,通过将损失函数作为列表传递,我们可以为不同的输出指定不同的损失:
model.compile(
optimizer=tf.keras.optimizers.RMSprop(1e-3),
loss=[tf.keras.losses.MeanSquaredError(),
tf.keras.losses.CategoricalCrossentropy(from_logits=True)]
)
如果我们仅使用单个损失函数传递给模型,则将相同的损失函数应用于每个输出,这在此处不合适。
1.7.2 指标函数
model.compile(
optimizer=tf.keras.optimizers.RMSprop(1e-3),
loss=[tf.keras.losses.MeanSquaredError(),
tf.keras.losses.CategoricalCrossentropy(from_logits=True)],
metrics = [
[tf.keras.metrics.MeanAbsolutePercentageError(),
tf.keras.metrics.MeanAbsoluteError()],
[tf.keras.metrics.CategoricalAccuracy()]
]
)
由于我们为输出层命名,因此还可以通过dict指定每个输出的损失和指标:
model.compile(
optimizer=tf.keras.optimizers.RMSprop(1e-3),
loss={
'score_output':tf.keras.losses.MeanSquaredError(),
'class_output':tf.keras.losses.CategoricalCrossentropy(from_logits=True)},
metrics={
'score_output':[tf.keras.metrics.MeanAbsolutePercentageError(),
tf.keras.metrics.MeanAbsoluteError()],
'class_output':[tf.keras.metrics.CategoricalAccuracy()]})
如果有两个以上的输出,建议使用显式名称和字典。
可以使用以下参数对不同的特定于输出的损失赋予不同的权重(例如在我们的示例中,我们可能希望给某类损失函数赋予更高的权重)
model.compile(
optimizer=tf.keras.optimizers.RMSprop(1e-3),
loss={
'score_output':tf.keras.losses.MeanSquaredError(),
'class_output':tf.keras.losses.CategoricalCrossentropy(from_logits=True)},
metrics={
'score_output':[tf.keras.metrics.MeanAbsolutePercentageError(),
tf.keras.metrics.MeanAbsoluteError()],
'class_output':[tf.keras.metrics.CategoricalAccuracy()]},
loss_weight={
'score_output':2.,'class_output':1.})
如果某些输出仅用于预测而不是训练,我们可以选择不为某些输出计算损失。
model.compile(
optimizer=tf.keras.optimizers.RMSprop(1e-3),
loss=[None, tf.keras.losses.CategoricalCrossentropy(from_logits=True)])
model.compile(
optimizer=tf.keras.optimizers.RMSprop(1e-3),
loss={
'class_output':tf.keras.losses.CategoricalCrossentropy(from_logits=True)})
1.7.3 完整运行
import tensorflow as tf
import numpy as np
image_input = tf.keras.Input(shape=(32,32,3), name='img_input')
timeseries_input = tf.keras.Input(shape=(20,10), name='ts_input')
x1 = tf.keras.layers.Conv2D(3, 3)(image_input)
x1 = tf.keras.layers.GlobalAveragePooling2D()(x1)
x2 = tf.keras.layers.Conv1D(3, 3)(timeseries_input)
x2 = tf.keras.layers.GlobalAveragePooling1D()(x2)
x = tf.keras.layers.concatenate([x1,x2])
score_output = tf.keras.layers.Dense(1, name='score_output')(x)
class_output = tf.keras.layers.Dense(5, name='class_output')(x)
model = tf.keras.Model(inputs=[image_input, timeseries_input], outputs=[score_output, class_output])
img_data = np.random.random_sample(size=(100, 32, 32, 3))
ts_data = np.random.random_sample(size=(100, 20, 10))
score_targets = np.random.random_sample(size=(100, 1))
class_targets = np.random.random_sample(size=(100, 5))
model.compile(
optimizer=tf.keras.optimizers.RMSprop(1e-3),
loss=[tf.keras.losses.MeanSquaredError(),
tf.keras.losses.CategoricalCrossentropy(from_logits=True)],
metrics = [
[tf.keras.metrics.MeanAbsolutePercentageError(),
tf.keras.metrics.MeanAbsoluteError()],
[tf.keras.metrics.CategoricalAccuracy()]
]
)
# 两种训练方式
model.fit([img_data, ts_data], [score_targets, class_targets], batch_size=32, epochs=3)
model.fit({
'img_input':img_data, 'ts_input':ts_data},
{
'score_output':score_targets, 'class_output':class_targets},
batch_size=32,
epochs=3)
2、自动求导方法
tensorflow中的梯度求解利器:tf.GradientTape。
GradientTape是eager模式下计算梯度用的,而eager模式是TensorFlow 2.0的默认模式。
举个例子,计算 y = x 2 y=x^2 y=x2在 x = 3 x=3 x=3时的导数:
import tensorflow as tf
x = tf.constant(3.0)
with tf.GradientTape() as g:
g.watch(x) # watch的作用:确保某个tensor被tape追踪
y = x * x
dy_dx = g.gradient(y,x) # gradient的作用:根据tape上面的上下文来计算某个或者某些tensor的梯度
2.1 tf.GradientTape详解
tf.GradientTape(persistent=False,
watch_accessed_variables=True)
- persistent:用来指定新创建的gradient tape是否是可持续性,默认是False,意味着只能够调用一次gradient()函数。
- watch_accessed_variables:表明这个GradientTape是不是会自动追踪任何能被训练(trainable)的变量。默认是True,要是False的话,意味着需要手动去指定想追踪的那些变量。
gradient(target,sources)
- 作用:根据tape上面的上下文来计算某个或者某些tensor的梯度参数。
- target:被微分的Tensor,可以理解为loss值(针对深度学习训练来说),就像上面代码中的y。
- sources:Tensor或者Variable列表(当然可以只有一个值)。
- 返回:一个列表表示各个变量的梯度值,和source中的变量列表一一对应,表明这个变量的梯度。
watch(tensor)
- 作用:确保某个tensor被tape追踪;
- 参数:一个Tensor或者一个Tensor列表;
- 一般在网络中使用时,不需要显式调用watch函数,使用默认设置。GradientTape会监控可训练变量;
apply_gradients(grads_and_vars, name=None)
- 作用:把计算出来的梯度更新到变量上;
- grads_and_vars:(gradient,variable)对的列表形式;
- name:操作名;
大概的使用方法如下面代码所示:
loss_object = tf.keras.losses.CategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
with tf.GradientTape() as tape:
predictions = model(data)
loss = loss_object(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
3、自定义模型训练
3.1 模型自动求导
- 构建模型(神经网络的前向传播);
- 定义损失函数;
- 定义优化函数;
- 定义tape;
- 模型得到预测值;
- 前向传播得到loss;
- 反向传播;
- 用优化函数将计算出来的梯度更新到变量上面;
import numpy as np
import tensorflow as tf
class MyModel(tf.keras.Model):
def __init__(self, num_classes=10):
super(MyModel, self).__init__(name='my_model')
self.num_classes = num_classes
# 定义自己需要的层
self.dense_1 = tf.keras.layers.Dense(32, activation='relu')
self.dense_2 = tf.keras.layers.Dense(self.num_classes)
def call(self, inputs):
# 定义前向传播
x = self.dense_1(inputs)
return self.dense_2(x)
data = np.random.random((1000, 32))
labels = np.random.random((1000, 10))
model = MyModel(num_classes=10)
loss_object = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
optimizer = tf.keras.optimizers.Adam()
with tf.GradientTape() as tape:
predictions = model(data)
loss = loss_object(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
3.2 用GradientTape自定义训练模型
3.2.1 模型构建
import tensorflow as tf
class MyModel(tf.keras.Model):
def __init__(self, num_classes=10):
super(MyModel, self).__init__(name='my_model')
self.num_classes = num_classes
# 定义自己需要的层
self.dense_1 = tf.keras.layers.Dense(32, activation='relu')
self.dense_2 = tf.keras.layers.Dense(self.num_classes)
def call(self, inputs):
# 定义前向传播
x = self.dense_1(inputs)
return self.dense_2(x)
3.2.2 创建数据
import numpy as np
data = np.random.random((1000, 32))
labels = np.random.random((1000, 10))
3.2.3 定义损失函数和优化器
model = MyModel(num_classes=10)
# 优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=1e-3)
# 损失函数
loss_fn = tf.keras.losses.CategoricalCrossentropy()
# 训练数据集准备(准备dataset并且打乱数据)
batch_size = 64
train_dataset = tf.data.Dataset.from_tensor_slices((data, labels))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(batch_size)
3.2.4 模型训练
import numpy as np
import tensorflow as tf
class MyModel(tf.keras.Model):
def __init__(self, num_classes=10):
super(MyModel, self).__init__(name='my_model')
self.num_classes = num_classes
# 定义自己需要的层
self.dense_1 = tf.keras.layers.Dense(32, activation='relu')
self.dense_2 = tf.keras.layers.Dense(num_classes)
def call(self, inputs):
#定义前向传播
# 使用在 (in `__init__`)定义的层
x = self.dense_1(inputs)
return self.dense_2(x)
data = np.random.random((100, 32))
labels = np.random.random((100, 10))
model = MyModel(num_classes=10)
# Instantiate an optimizer.
optimizer = tf.keras.optimizers.SGD(learning_rate=1e-3)
# Instantiate a loss function.
loss_fn = tf.keras.losses.CategoricalCrossentropy()
# Prepare the training dataset.
batch_size = 16
train_dataset = tf.data.Dataset.from_tensor_slices((data, labels))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(batch_size)
epochs = 3
for epoch in range(epochs):
print('Start of epoch %d' % (epoch,))
# 遍历数据集的batch_size
for step, (x_batch_train, y_batch_train) in enumerate(train_dataset):
# 打开GradientTape以记录正向传递期间运行的操作,这将启用自动区分。
with tf.GradientTape() as tape:
# 运行该模型的前向传播。 模型应用于其输入的操作将记录在GradientTape上。
logits = model(x_batch_train, training=True) # 这个minibatch的预测值
# 计算这个minibatch的损失值
loss_value = loss_fn(y_batch_train, logits)
# 使用GradientTape自动获取可训练变量相对于损失的梯度。
grads = tape.gradient(loss_value, model.trainable_weights)
# 通过更新变量的值来最大程度地减少损失,从而执行梯度下降的一步。
optimizer.apply_gradients(zip(grads, model.trainable_weights))
# 每200 batches打印一次.
if step % 200 == 0:
print('Training loss (for one batch) at step %s: %s' % (step, float(loss_value)))
print('Seen so far: %s samples' % ((step + 1) * 64))
3.3 使用GradientTape自定义训练模型进阶(加入评估函数)
让我们将metric添加到组合中。下面可以在从头开始编写的训练循环中随时使用内置指标(或编写的自定义指标)。流程如下:
- 在循环开始时初始化metrics
- metric.update_state():每batch之后更新
- metric.result():需要显示metrics的当前值时调用
- metric.reset_states():需要清除metrics状态时重置(通常在每个epoch的结尾)
3.3.1 模型构建
class MyModel(tf.keras.Model):
def __init__(self, num_classes=10):
super(MyModel, self).__init__(name='my_model')
self.num_classes = num_classes
# 定义自己需要的层
self.dense_1 = tf.keras.layers.Dense(32, activation='relu')
self.dense_2 = tf.keras.layers.Dense(num_classes)
def call(self, inputs):
#定义前向传播
# 使用在 (in `__init__`)定义的层
x = self.dense_1(inputs)
return self.dense_2(x)
3.3.2 构造数据集、优化器、损失函数
import numpy as np
x_train = np.random.random((1000, 32))
y_train = np.random.random((1000, 10))
x_val = np.random.random((200, 32))
y_val = np.random.random((200, 10))
x_test = np.random.random((200, 32))
y_test = np.random.random((200, 10))
# 优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=1e-3)
# 损失函数
loss_fn = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
# 准备metrics函数
train_acc_metric = tf.keras.metrics.CategoricalAccuracy()
val_acc_metric = tf.keras.metrics.CategoricalAccuracy()
# 准备训练数据集
batch_size = 64
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(batch_size)
# 准备测试数据集
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
val_dataset = val_dataset.batch(64)
3.3.3 模型训练
model = MyModel(num_classes=10)
epochs = 3
for epoch in range(epochs):
print('Start of epoch %d' % (epoch,))
# 遍历数据集的batch_size
for step, (x_batch_train, y_batch_train) in enumerate(train_dataset):
#一个batch
with tf.GradientTape() as tape:
logits = model(x_batch_train)
loss_value = loss_fn(y_batch_train, logits)
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
# 更新训练集的metrics
train_acc_metric(y_batch_train, logits)
# 在每个epoch结束时显示metrics。
train_acc = train_acc_metric.result()
print('Training acc over epoch: %s' % (float(train_acc),))
# 在每个epoch结束时重置训练指标
train_acc_metric.reset_states()#!!!!!!!!!!!!!!!
# 在每个epoch结束时运行一个验证集。
for x_batch_val, y_batch_val in val_dataset:
val_logits = model(x_batch_val)
# 更新验证集merics
val_acc_metric(y_batch_val, val_logits)
val_acc = val_acc_metric.result()
print('Validation acc: %s' % (float(val_acc),))
val_acc_metric.reset_states()
#显示测试集