Binarized Neural Networks: Training Neural Networks with Weights and
Activations Constrained to +1 or − 1
2016年2月份
前身2015年的BinaryConnect,只探讨了权重二值,激活值32bit,在训练讨论上更为详细。
https://www.wandouip.com/t5i180712/#conclusion-and-future-works
文章的主要思想是通过二值化weights和activations,来提高NN的速度和减少其内存占用
1 前向和反向传播的数值计算
1.1权重和激活函数值二值化公式
就符号函数,跟零比,判断正负。
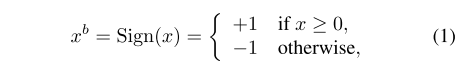
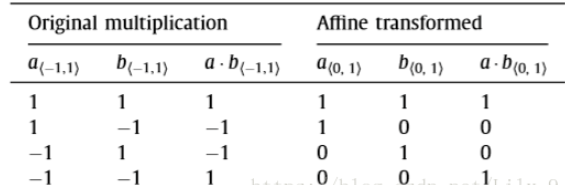
1.2 XNOR乘法
1,-1的乘法运算真值表,把-1 替换为0,和Xnor(同或),异或非真值表一样。
举个例子,a=[1,-1, 1, 1, -1],W=[-1,1,1,-1,-1]。按照正常的乘法应该是:
a1w1+a2w2+a3w3+a4w4+a5w5=
1 * -1+ -1 * 1 +1 1 +1* -1+ -1*-1= -1
转成Xnor的计算方式,
a=[1,0,1,1,0],W=[0,1,1,0,0]表示的,具体运算过程如下:
a ^ W=[1 ^ 0,0^ 1,1^ 1,1^ 0,0^0]=[1,1,0,1,0]
所以Popcount(a^w)=3
Popcount(x)表示统计向量x中1的个数,对应原数据中计算结果为-1的
对应的,如果用vec_len表示向量元素个数的话,(vec_len-Popcount(x))为对应原数据结果为1的
最终结果为
1*(vec_len-Popcount(x))+ -1*(Popcount(x))= -vec_len-2*Popcount(a^w)
1.3二值化的数据梯度
对于输入实数r,经过上面的符号函数后,反向传播时候怎么求r梯度gr。
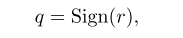
符号函数没法求梯度,造个函数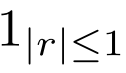 在需要反向传播求梯度时候,替代符号函数,然后就能求输入的梯度gr了。
在需要反向传播求梯度时候,替代符号函数,然后就能求输入的梯度gr了。
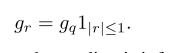
1|r|<=1就是Htanh®,长这样

用表达式表示:
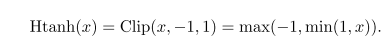
梯度肉眼可见,【-1,1】为1,其他不更新梯度(=0)。
当权值波动幅度超出二进制值±1时,由于二值化操作不受实际权重w的变化的影响,并且由于通常的做法是约束权重(通常是权重向量)以使它们正规化,我们在权重更新后的间隔选择剪切实值权重在[-1,1],
前向和反向传播的数值计算就替换完成
等效于在前向传播中,用了sign函数,而在后向传播中,用了hard tanh函数。
下面改传播算法
2前向和反向传播的算法设计
MLP的计算实例和推导公式:
https://www.cnblogs.com/charlotte77/p/5629865.html
就两点,输入实数改为8bit表示的二值;
训练好的权重进行Sign()二值化。
剩下的计算就是上边的XNOR,网络设计
2.1改前向传播算法

分为第一层和其它层
因为第一层输入图像为8bit 256个像素
2.1.1 第一层
一般使用8位的值来表示一个像素,输入可以表达为一个height×width×8height\times width\times 8height×width×8的张量,
深度改为8
异或乘+BN+sign符号化

很多博主把这个公式解释成反向求取输入,感觉不是。就是作为八通道计算再累加,跟浮点数(连续值)一样的意思,只不过按位去处理的。
Q:不理解作者文中的:1024探讨一下
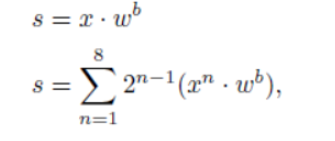

2.1.2 后面层
异或乘+BN+sign符号化

2.2改反向传播算法
Bianrize()就是Sign()
Wk是实数型的参数,用于权重更新,Wkb akb用于前向传播,反向传播计算,所以决定了更新是用在Wk上。
Update()是 Adam更新方式,
需要更新的地方: BN参数 yita theta 和Wk
主要难点在W
仍然是链式法则
先算损失,最后一层用损失函数计算损失梯度,gaL.
然后从后往前更新。
用上节中的实数梯度Htanh() 1|ak|<=1去二值化,具体就是看激活值是否在-1~1范围,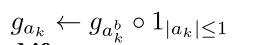
不在梯度为零,直接保持Wk,
在的话接下来一堆链式:
BN的反向公式,
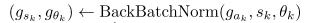
然后就可以得到对二值Wkb的梯度了
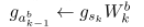
然后再用一次Htanh,注意变量是用Adam更新过的。
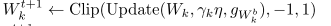

BN层的参数正常操作
PLUS 训练优化的两个小技巧
针对BN,和Adam
算法23,和算法4
BN层计算
因为二值化这一特殊情况,所以可以对BN进行优化,可以在不进行乘法的情况下近似计算BN,这就是shift-based Batch Normalization。

优化算法
且把shift based Adamax的算法列出来吧。

做实验
结构就一个全连接一个卷积
剩下的所谓实验就是换平台换数据集,TORCH,THEANO/ SVHN
比最好的结果要稍差,但差的不会太多。
1 MLP结构
测MNIST
3 hidden layers of 4096 binary units (see Section 1) and a L2-SVM output layer;
2ConvNet
测CIFAR-10
结构差不多是VGG,损失square hinge

效果
- 主要看时间内存
提了一嘴,没有证据 时间复杂度可以降低60% - 内存和计算耗能

code
https://github.com/MatthieuCourbariaux/BinaryNet
ref
https://blog.csdn.net/h__ang/article/details/88389174?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
