批训练
把训练数据切割成很多个 batch ,接着一个 batch 一个 batch 的喂给模型;
优点
- 提高训练速度;
- 对训练过程引入随机性;
这个随机性最重要,可以有效解决局部最优,我现在切分成很多很多 batch ,那么每个 batch 的初始位置随机性很大,就好像撒豆子,每个地方都撒一点,就不容易卡在某一个小坑。
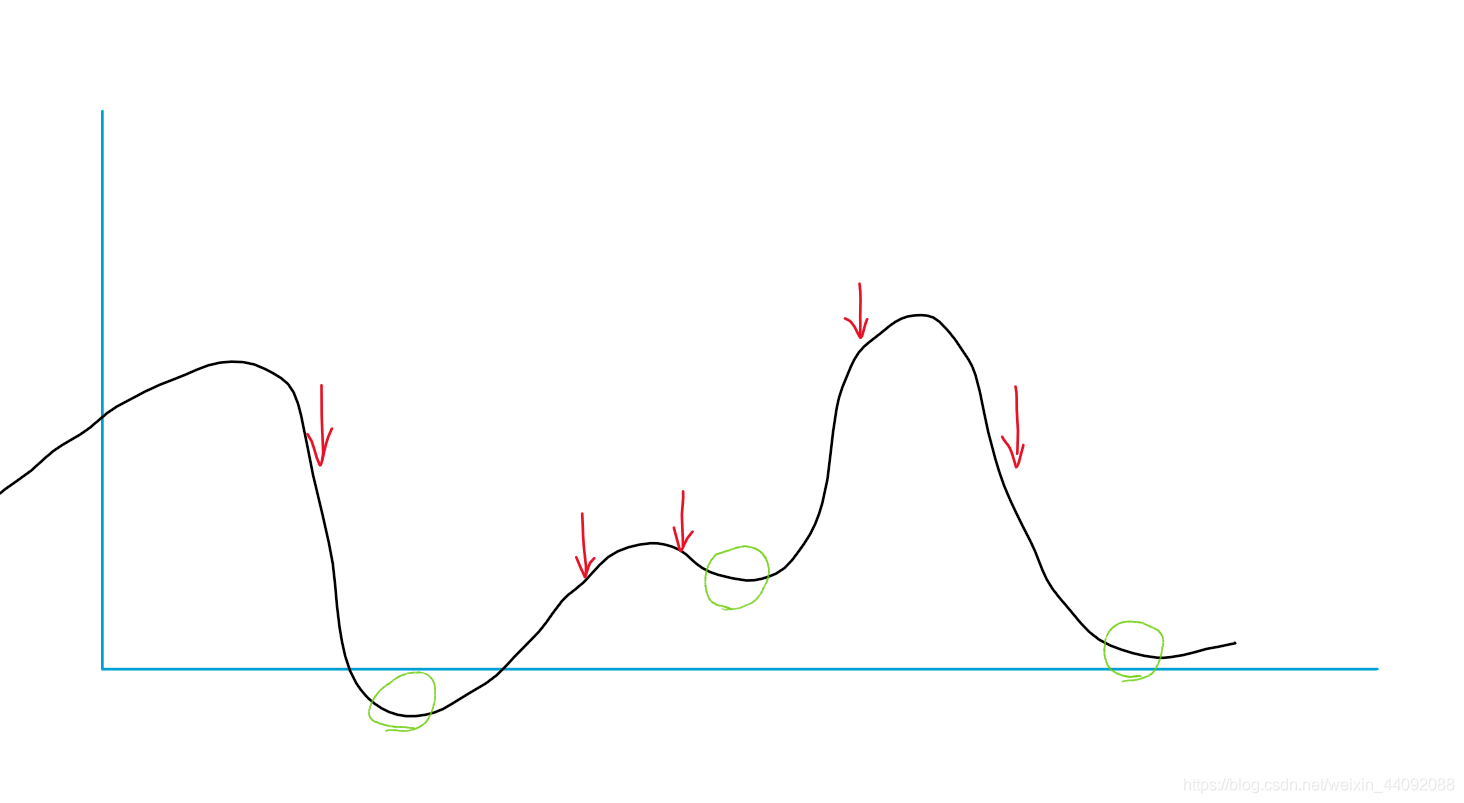
红色部分表示 batch 数据,这样就可以几乎踩到每一个局部最优(绿色),进而找到全局最优。
动量梯度下降法(gradient descent with momentum)优化器
随机性过大有个坏处,不是每次迭代都往好的方向走,会导致计算时间过长,这个时候可以引入参数 β,来引入惯性。
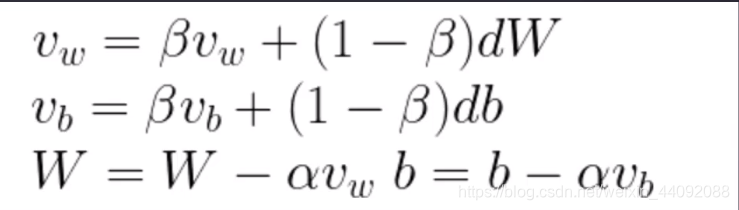
β越大,(1-β)越小,dW 对 v w v_w vw 的影响也就越小,相当于 v w v_w vw 惯性越大,越不易改变, v b v_b vb 也是如此。
RMSProp优化器
第一个式子是 dW2,和上一个优化器 d W dW dW 不一样。
W 更新的时候,改变量除以根号 S w S_w Sw
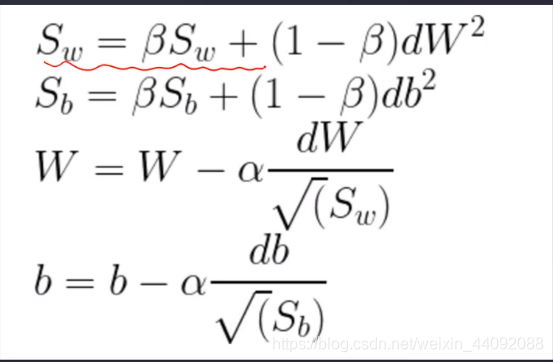
相比于上一个纯粹惯性,跌跌撞撞走向全局最优解,这一个优化器会更加平稳地走向全局最优解。
优点
较为平稳
自适应矩估计 Adam 优化器
可以简单理解为前面两个优化器的结合,引入参数
β 1 , β 2 , ε , t β_1, β_2, ε, t β1,β2,ε,t
β 1 β_1 β1经常取0.9, β 2 β_2 β2经常取0.999,
其中 ε ε ε,是一个很小的数,经常取 1e-8,1e-9,来防止该项爆炸。
t t t 为迭代次数,相当于考虑步伐 ,由下面式子可知,使得 v w v_w vw, v b v_b vb改变时,在初始时刻步伐较大,快速向全局最优解进发,在最后就小心谨慎一点,慢慢向全局最优解挪动。
此外参数并不一定是这些值,还需要大佬们仔细调整。
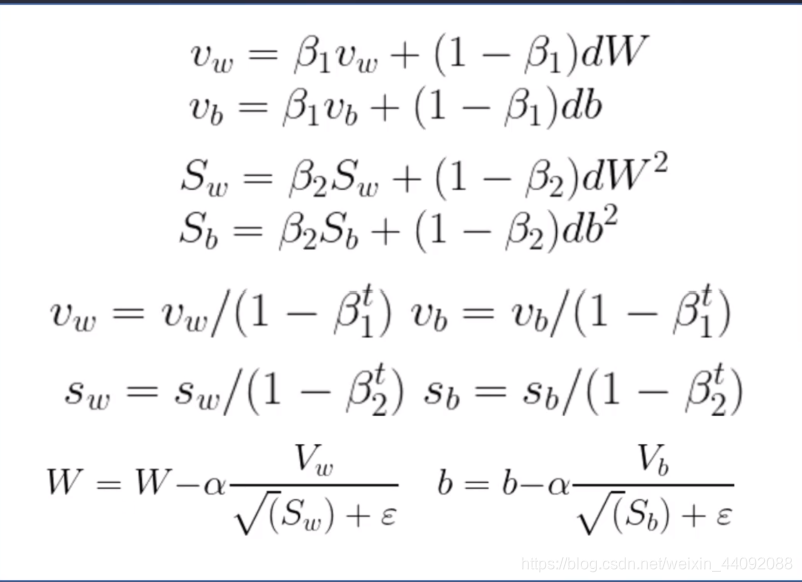
优点
适合大规模数据,还可以解决高噪音,稀疏梯度等问题。