课程资源:
【小学生都会的Pytorch】九、运用你的模型做预测(1)_哔哩哔哩_bilibili
笔记:
pytorch进阶学习(四):使用不同分类模型进行数据训练(alexnet、resnet、vgg等)_好喜欢吃红柚子的博客-CSDN博客
目录

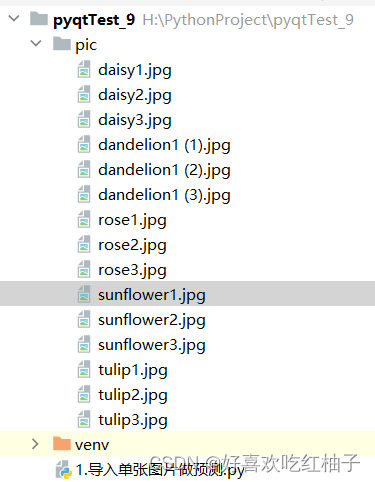
模型在经过前面几节的训练之后,传入自己的数据进行预测,流程和训练时差不多。项目目录如下所示,pic为预测时取的照片。
一、原理介绍
1. 加载模型与参数
模型骨架使用resnet18进行训练,使用预训练好的权重文件“model_resnet18_100.pth”来进行参数的加载。
# 如果显卡可用,则用显卡进行训练
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
'''
加载模型与参数
'''
# 加载模型
model = resnet18(pretrained=False, num_classes=5).to(device) # 43.6%
# 加载模型参数
if device == "cpu":
# 加载模型参数,权重文件传过来
model.load_state_dict(torch.load("model_resnet18_100.pth", map_location=torch.device('cpu')))
else:
model.load_state_dict(torch.load("model_resnet18_100.pth"))2. 读取图片
我们要预测的是sunflower1这张图片。
img_path = './pic/sunflower1.jpg' 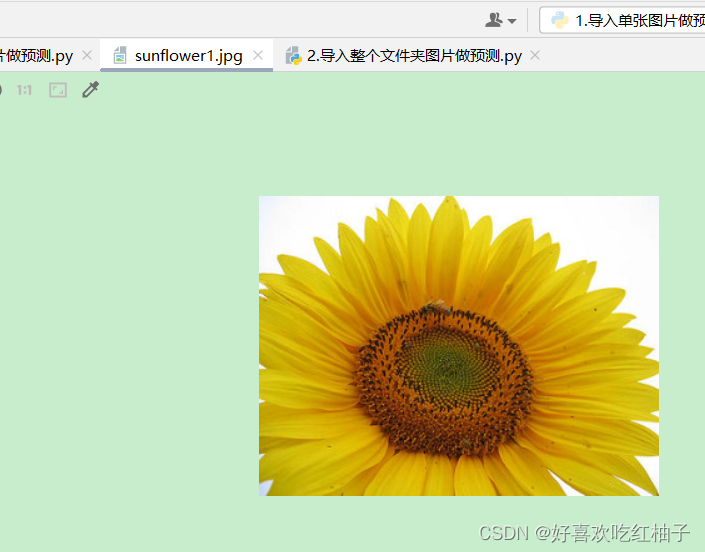
3. 图片预处理
Image.open打开图像,转换为RGB格式,padding_black进行图像的扩充
img = Image.open(img_path)#打开图片
img = img.convert('RGB')#转换为RGB 格式
# 扩充
img = padding_black(img)4. 把图片转换为tensor
val_tf = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transform_BZ # 标准化操作
])
# 图片转换为tensor
img_tensor = val_tf(img)5. 增加batch_size的维度
如果直接把图片传入模型会发生以下报错:

原因:
模型接收的是四维输入,但是我们图片的输入只有3维,要求的4维输入的第一维为batch_size,我们训练好的模型中batch_size=64,但是一张图片没有这个维度,所以需要给这张传入的图片再增加一个通道。
- dim=0代表在第一个维度增加维度
# 增加batch_size维度
img_tensor = Variable(torch.unsqueeze(img_tensor, dim=0).float(), requires_grad=False).to(device)
6. 模型验证
6.1 模型的初步输出
模型进行输出后可以看到如下结果,tensor中有5个数。
model.eval()
# 不进行梯度更新
with torch.no_grad():
output_tensor = model(img_tensor)
print(output_tensor)![]()
但是都不在0-1之间,不是我们需要的对每一个类的概率值,所以我们需要使用softmax进行归一化。使用softmax进行归一化。
# 将输出通过softmax变为概率值
output = torch.softmax(output_tensor,dim=1)
print(output)可以看到进行softmax运算后,出现的结果使用的是科学计数法,5个数加起来为1.

6.2 输出预测值概率最大的值和位置
# 输出可能性最大的那位
pred_value, pred_index = torch.max(output, 1)
print(pred_value)
print(pred_index)输出可以看到输出概率为1,即100%,位置下标为3,即第四类,sunflower类。

6.3 把tensor转为numpy
在上一步输出时的数据为tensor格式,所以我们需要把数字先转换为numpy,再进行后续标签下标到标签类的转换。
# 将数据从cuda转回cpu
pred_value = pred_value.detach().cpu().numpy()
pred_index = pred_index.detach().cpu().numpy()
print(pred_value)
print(pred_index)打印结果可以看到已经成功转换到了numpy类,没有了tensor标志

6.4 预测类别
写出类别的中文列表,一定要与test训练集标签中的顺序对应起来。
classes = ["daisy", "dandelion", "rose", "sunflower", "tulip"]
print("预测类别为: ",classes[pred_index[0]]," 可能性为: ",pred_value[0]*100,"%")打印输出可以看到预测正确,准确率高 。
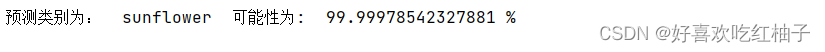
二、代码
1. 对单张图片做预测
'''
功能:按着路径,导入单张图片做预测
作者: Leo在这
'''
from torchvision.models import resnet18
import torch
from PIL import Image
import torchvision.transforms as transforms
from torch.autograd import Variable
# 如果显卡可用,则用显卡进行训练
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
'''
加载模型与参数
'''
# 加载模型
model = resnet18(weights=False, num_classes=5).to(device) # 43.6%
# 加载模型参数
if device == "cpu":
# 加载模型参数,权重文件传过来
model.load_state_dict(torch.load("model_resnet18_100.pth", map_location=torch.device('cpu')))
else:
model.load_state_dict(torch.load("model_resnet18_100.pth"))
'''
加载图片与格式转化
'''
img_path = './pic/sunflower1.jpg'
'''
图片进行预处理
'''
# 图片标准化
transform_BZ= transforms.Normalize(
mean=[0.5, 0.5, 0.5],# 取决于数据集
std=[0.5, 0.5, 0.5]
)
val_tf = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transform_BZ # 标准化操作
])
def padding_black(img): # 如果尺寸太小可以扩充
w, h = img.size
scale = 224. / max(w, h)
img_fg = img.resize([int(x) for x in [w * scale, h * scale]])
size_fg = img_fg.size
size_bg = 224
img_bg = Image.new("RGB", (size_bg, size_bg))
img_bg.paste(img_fg, ((size_bg - size_fg[0]) // 2,
(size_bg - size_fg[1]) // 2))
img = img_bg
return img
# 打开图片,转换为RGB
img = Image.open(img_path)#打开图片
img = img.convert('RGB')#转换为RGB 格式
# 扩充
img = padding_black(img)
# print(type(img))
# 图片转换为tensor
img_tensor = val_tf(img)
# print(type(img_tensor))
# 增加batch_size维度
img_tensor = Variable(torch.unsqueeze(img_tensor, dim=0).float(), requires_grad=False).to(device)
'''
数据输入与模型输出转换
'''
model.eval()
# 不进行梯度更新
with torch.no_grad():
output_tensor = model(img_tensor)
print(output_tensor)
#
# 将输出通过softmax变为概率值
output = torch.softmax(output_tensor,dim=1)
print(output)
# 输出可能性最大的那位
pred_value, pred_index = torch.max(output, 1)
print(pred_value)
print(pred_index)
# 将数据从cuda转回cpu
pred_value = pred_value.detach().cpu().numpy()
pred_index = pred_index.detach().cpu().numpy()
print(pred_value)
print(pred_index)
# #
# 增加类别标签
classes = ["daisy", "dandelion", "rose", "sunflower", "tulip"]
print("预测类别为: ",classes[pred_index[0]]," 可能性为: ",pred_value[0]*100,"%")2. 对整个文件夹图片做预测
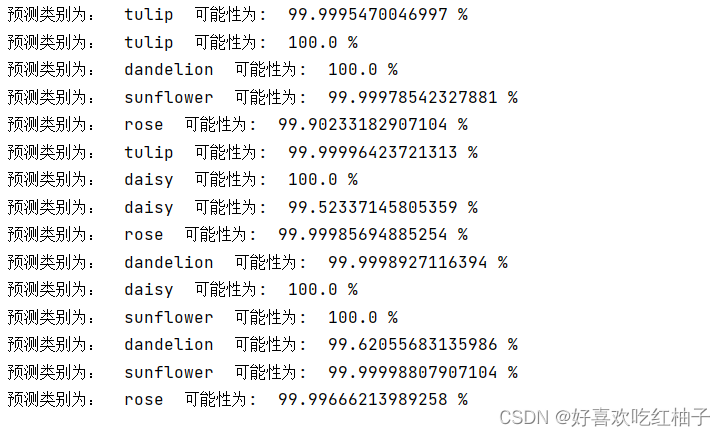
对根目录为pic的文件夹做图片预测,步骤和单张图片预测差不多,使用for循环遍历文件。
'''
功能:导入文件夹做预测
作者:Leo在这
'''
from torchvision.models import resnet18
import torch
from PIL import Image
import torchvision.transforms as transforms
from torch.autograd import Variable
import os
# 如果显卡可用,则用显卡进行训练
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
'''
加载模型与参数
'''
# 加载模型
model = resnet18(pretrained=False, num_classes=5).to(device) # 43.6%
if device == "cpu":
# 加载模型参数
model.load_state_dict(torch.load("model_resnet18_100.pth", map_location=torch.device('cpu')))
else:
model.load_state_dict(torch.load("model_resnet18_100.pth"))
'''
加载图片与格式转化
'''
# 图片标准化
transform_BZ= transforms.Normalize(
mean=[0.5, 0.5, 0.5],# 取决于数据集
std=[0.5, 0.5, 0.5]
)
val_tf = transforms.Compose([##简单把图片压缩了变成Tensor模式
transforms.Resize(224),
transforms.ToTensor(),
transform_BZ#标准化操作
])
def padding_black(img): # 如果尺寸太小可以扩充
w, h = img.size
scale = 224. / max(w, h)
img_fg = img.resize([int(x) for x in [w * scale, h * scale]])
size_fg = img_fg.size
size_bg = 224
img_bg = Image.new("RGB", (size_bg, size_bg))
img_bg.paste(img_fg, ((size_bg - size_fg[0]) // 2,
(size_bg - size_fg[1]) // 2))
img = img_bg
return img
dir_loc = r"./pic"
model.eval()
with torch.no_grad():
for a,b,c in os.walk(dir_loc):
for filei in c:
full_path = os.path.join(a,filei)
# print(full_path)
# img_path = './pic/sunflower3.jpg'
img = Image.open(full_path)#打开图片
img = img.convert('RGB')#转换为RGB 格式
img = padding_black(img)
# print(type(img))
img_tensor = val_tf(img)
# print(type(img_tensor))
# 增加batch_size维度
img_tensor = Variable(torch.unsqueeze(img_tensor, dim=0).float(), requires_grad=False).to(device)
'''
数据输入与模型输出转换
'''
output_tensor = model(img_tensor)
# 将输出通过softmax变为概率值
output = torch.softmax(output_tensor,dim=1)
# 输出可能性最大的那位
pred_value, pred_index = torch.max(output, 1)
pred_value = pred_value.detach().cpu().numpy()
pred_index = pred_index.detach().cpu().numpy()
# 增加类别标签
classes = ["daisy", "dandelion", "rose", "sunflower", "tulip"]
print("预测类别为: ",classes[pred_index[0]]," 可能性为: ",pred_value[0]*100,"%")结果如下所示: