CriteoLabs 2014年7月份在kaggle上发起了一次关于展示广告点击率的预估比赛。获得比赛第一名的是号称”3 Idiots”的三个台湾人,最近研究了一下他们的开源的比赛代码,在此分享一下他们的思路。这个代码非常适合机器学习初学者研究一下,尤其对于跨行想做机器学习,但是这之前又没有做过相关的项目。从数据的处理到模型算法的选择,都非常的详细。读完这个代码,大家一定会对机器学习在工业上的应用稍有了解。
在此,我们从数据集开始一步一步的分析整个算法的流程,中间会结合着代码进行解读!
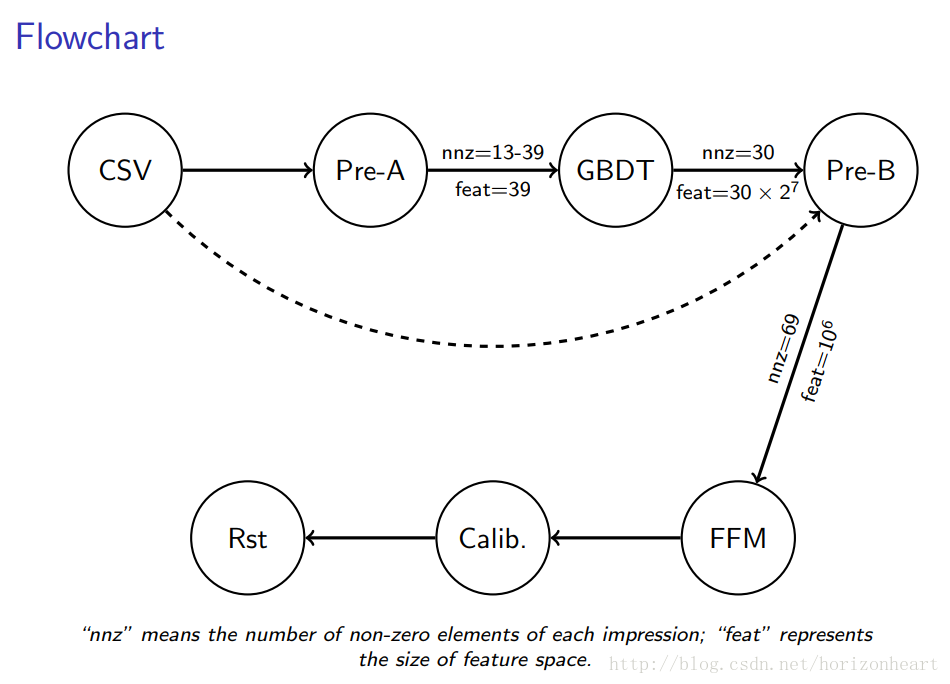
1–数据集
| Id | Label | I1 | I2 | I3 | I4 | I5 | I6 | I7 | I8 | I9 | I10 | I11 | I12 | I13 | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | C11 | C12 | C13 | C14 | C15 | C16 | C17 | C18 | C19 | C20 | C21 | C22 | C23 | C24 | C25 | C26 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10000000 | 0 | 1 | 1 | 5 | 0 | 1382 | 4 | 15 | 2 | 181 | 1 | 2 | 2 | 68fd1e64 | 80e26c9b | fb936136 | 7b4723c4 | 25c83c98 | 7e0ccccf | de7995b8 | 1f89b562 | a73ee510 | a8cd5504 | b2cb9c98 | 37c9c164 | 2824a5f6 | 1adce6ef | 8ba8b39a | 891b62e7 | e5ba7672 | f54016b9 | 21ddcdc9 | b1252a9d | 07b5194c | 3a171ecb | c5c50484 | e8b83407 | 9727dd16 | ||
| 10000001 | 0 | 2 | 0 | 44 | 1 | 102 | 8 | 2 | 2 | 4 | 1 | 1 | 4 | 68fd1e64 | f0cf0024 | 6f67f7e5 | 41274cd7 | 25c83c98 | fe6b92e5 | 922afcc0 | 0b153874 | a73ee510 | 2b53e5fb | 4f1b46f3 | 623049e6 | d7020589 | b28479f6 | e6c5b5cd | c92f3b61 | 07c540c4 | b04e4670 | 21ddcdc9 | 5840adea | 60f6221e | 3a171ecb | 43f13e8b | e8b83407 | 731c3655 | ||
| 10000002 | 0 | 2 | 0 | 1 | 14 | 767 | 89 | 4 | 2 | 245 | 1 | 3 | 3 | 45 | 287e684f | 0a519c5c | 02cf9876 | c18be181 | 25c83c98 | 7e0ccccf | c78204a1 | 0b153874 | a73ee510 | 3b08e48b | 5f5e6091 | 8fe001f4 | aa655a2f | 07d13a8f | 6dc710ed | 36103458 | 8efede7f | 3412118d | e587c466 | ad3062eb | 3a171ecb | 3b183c5c | ||||
| 10000003 | 0 | 893 | 4392 | 0 | 0 | 0 | 0 | 68fd1e64 | 2c16a946 | a9a87e68 | 2e17d6f6 | 25c83c98 | fe6b92e5 | 2e8a689b | 0b153874 | a73ee510 | efea433b | e51ddf94 | a30567ca | 3516f6e6 | 07d13a8f | 18231224 | 52b8680f | 1e88c74f | 74ef3502 | 6b3a5ca6 | 3a171ecb | 9117a34a | ||||||||||||
| 10000004 | 0 | 3 | -1 | 0 | 2 | 0 | 3 | 0 | 0 | 1 | 1 | 0 | 8cf07265 | ae46a29d | c81688bb | f922efad | 25c83c98 | 13718bbd | ad9fa255 | 0b153874 | a73ee510 | 5282c137 | e5d8af57 | 66a76a26 | f06c53ac | 1adce6ef | 8ff4b403 | 01adbab4 | 1e88c74f | 26b3c7a7 | 21c9516a | 32c7478e | b34f3128 | |||||||
| 10000005 | 0 | -1 | 12824 | 0 | 0 | 6 | 0 | 05db9164 | 6c9c9cf3 | 2730ec9c | 5400db8b | 43b19349 | 6f6d9be8 | 53b5f978 | 0b153874 | a73ee510 | 3b08e48b | 91e8fc27 | be45b877 | 9ff13f22 | 07d13a8f | 06969a20 | 9bc7fff5 | 776ce399 | 92555263 | 242bb710 | 8ec974f4 | be7c41b4 | 72c78f11 | |||||||||||
| 10000006 | 0 | 1 | 2 | 3168 | 0 | 1 | 2 | 0 | 439a44a4 | ad4527a2 | c02372d0 | d34ebbaa | 43b19349 | fe6b92e5 | 4bc6ffea | 0b153874 | a73ee510 | 3b08e48b | a4609aab | 14d63538 | 772a00d7 | 07d13a8f | f9d1382e | b00d3dc9 | 776ce399 | cdfa8259 | 20062612 | 93bad2c0 | 1b256e61 | |||||||||||
| 10000007 | 1 | 1 | 4 | 2 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 68fd1e64 | 2c16a946 | 503b9dbc | e4dbea90 | f3474129 | 13718bbd | 38eb9cf4 | 1f89b562 | a73ee510 | 547c0ffe | bc8c9f21 | 60ab2f07 | 46f42a63 | 07d13a8f | 18231224 | e6b6bdc7 | e5ba7672 | 74ef3502 | 5316a17f | 32c7478e | 9117a34a | ||||||
| 10000008 | 0 | 44 | 4 | 8 | 19010 | 249 | 28 | 31 | 141 | 1 | 8 | 05db9164 | d833535f | d032c263 | c18be181 | 25c83c98 | 7e0ccccf | d5b6acf2 | 0b153874 | a73ee510 | 2acdcf4e | 086ac2d2 | dfbb09fb | 41a6ae00 | b28479f6 | e2502ec9 | 84898b2a | e5ba7672 | 42a2edb9 | 0014c32a | 32c7478e | 3b183c5c | ||||||||
| 10000009 | 0 | 35 | 1 | 33737 | 21 | 1 | 2 | 3 | 1 | 1 | 05db9164 | 510b40a5 | d03e7c24 | eb1fd928 | 25c83c98 | 52283d1c | 0b153874 | a73ee510 | 015ac893 | e51ddf94 | 951fe4a9 | 3516f6e6 | 07d13a8f | 2ae4121c | 8ec71479 | d4bb7bd8 | 70d0f5f9 | 0e63fca0 | 32c7478e | 0e8fe315 | ||||||||||
| 10000010 | 0 | 2 | 632 | 0 | 56770 | 0 | 5 | 65 | 0 | 2 | 05db9164 | 0468d672 | 7ae80d0f | 80d8555a | 25c83c98 | 7e0ccccf | 04277bf9 | 0b153874 | 7cc72ec2 | 3b08e48b | 7e2c5c15 | cfc86806 | 91a1b611 | b28479f6 | 58251aab | 146a70fd | 776ce399 | 0b331314 | 21ddcdc9 | 5840adea | cbec39db | 3a171ecb | cedad179 | ea9a246c | 9a556cfc |
Label - 1和0分别代表了广告是否被点击了
I1-I13 - 这13列代表的是数值型的特征.
C1-C26 - categorical型特征,这些特征已经加密,隐藏了原始的含义。
2–数据清洗处理
2.1- 统计训练数据中categorical类型特征数目,将出现次数大于十次(这个次数是可以自己设定的)以上的特征记录下来,执行的脚本如下:
cmd = ‘./utils/count.py tr.csv > fc.trva.t10.txt’
count.py的内容如下:
#统计categorical特征的数量
import argparse, csv, sys, collections
from common import *
if len(sys.argv) == 1:
sys.argv.append('-h')
parser = argparse.ArgumentParser()
parser.add_argument('csv_path', type=str)
args = vars(parser.parse_args())
counts = collections.defaultdict(lambda : [0, 0, 0]) #括号里面的参数代表当map中的键为空的时候,返回括号里面的函数值
for i, row in enumerate(csv.DictReader(open(args['csv_path'])), start=1):#start代表开始的索引从1开始,即i的值从1开始计数
label = row['Label']
for j in range(1, 27):
field = 'C{0}'.format(j)
value = row[field]
if label == '0':
counts[field+','+value][0] += 1
else:
counts[field+','+value][1] += 1
counts[field+','+value][2] += 1
if i % 1000000 == 0:
sys.stderr.write('{0}m\n'.format(int(i/1000000)))
print('Field,Value,Neg,Pos,Total,Ratio')
#按照字段的总个数排序
for key, (neg, pos, total) in sorted(counts.items(), key=lambda x: x[1][2]): #map.items()将map中的键值组成一个元组放在列表中[('r1', [3, 0, 0])]
if total < 10:
continue
ratio = round(float(pos)/total, 5)
print(key+','+str(neg)+','+str(pos)+','+str(total)+','+str(ratio))
执行的完上述的脚本, fc.trva.t10.txt中记录了统计的结果:
| Field | Value | Neg | Pos | Total | Ratio |
|---|---|---|---|---|---|
| C7 | fe4dce68 | 6 | 4 | 10 | 0.4 |
| C16 | d37efe8c | 9 | 1 | 10 | 0.1 |
| C15 | 943169c2 | 9 | 1 | 10 | 0.1 |
| C11 | 434d6c13 | 7 | 3 | 10 | 0.3 |
| C3 | 6f67f7e5 | 8 | 2 | 10 | 0.2 |
| C26 | b13f4ade | 9 | 1 | 10 | 0.1 |
2.2- 将训练数据集中数值型的特征(即I1-I13)和categorical特征(C1-C26)分别生成两个文件,下一步作为GBDT程序的输入。在这里面会利用多线程进行处理,数值型特征会生成稠密型的数据,即每一行记录label和对应的特征的value,对于缺失型的数据,作者默认赋值为-10(为什么是这个数字不是很清楚)。对于categorical特征,进行one-hot编码,只将出现次数在百万以上的特征进行记录(我猜作者是在前期对这个进行了统计,只是没有在代码中给出,直接给出了使用哪些特征)。将执行的脚本如下:
cmd = ‘converters/parallelizer-a.py -s {nr_thread} converters/pre-a.py tr.csv tr.gbdt.dense tr.gbdt.sparse’.format(nr_thread=NR_THREAD)
#parallelizer-a.py文件
import argparse, sys
from common import *
def parse_args():
if len(sys.argv) == 1:
sys.argv.append('-h')
parser = argparse.ArgumentParser()
parser.add_argument('-s', dest='nr_thread', default=12, type=int)
parser.add_argument('cvt_path')
parser.add_argument('src_path')
parser.add_argument('dst1_path')
parser.add_argument('dst2_path')
args = vars(parser.parse_args())
return args
def main():
args = parse_args()
nr_thread = args['nr_thread']
#将原始文件分割成小文件
split(args['src_path'], nr_thread, True)
#分割gbdt的文件
parallel_convert(args['cvt_path'], [args['src_path'], args['dst1_path'], args['dst2_path']], nr_thread)
cat(args['dst1_path'], nr_thread)
cat(args['dst2_path'], nr_thread)
delete(args['src_path'], nr_thread)
delete(args['dst1_path'], nr_thread)
delete(args['dst2_path'], nr_thread)
main()
#pre-a.py文件
import argparse, csv, sys
from common import *
if len(sys.argv) == 1:
sys.argv.append('-h')
parser = argparse.ArgumentParser()
parser.add_argument('csv_path', type=str)
parser.add_argument('dense_path', type=str)
parser.add_argument('sparse_path', type=str)
args = vars(parser.parse_args())
#生成稠密和稀疏矩阵
#These features are dense enough (they appear in the dataset more than 4 million times), so we include them in GBDT
target_cat_feats = ['C9-a73ee510', 'C22-', 'C17-e5ba7672', 'C26-', 'C23-32c7478e', 'C6-7e0ccccf', 'C14-b28479f6', 'C19-21ddcdc9', 'C14-07d13a8f', 'C10-3b08e48b', 'C6-fbad5c96', 'C23-3a171ecb', 'C20-b1252a9d', 'C20-5840adea', 'C6-fe6b92e5', 'C20-a458ea53', 'C14-1adce6ef', 'C25-001f3601', 'C22-ad3062eb', 'C17-07c540c4', 'C6-', 'C23-423fab69', 'C17-d4bb7bd8', 'C2-38a947a1', 'C25-e8b83407', 'C9-7cc72ec2']
with open(args['dense_path'], 'w') as f_d, open(args['sparse_path'], 'w') as f_s:
for row in csv.DictReader(open(args['csv_path'])):
#处理数值特征
feats = []
for j in range(1, 14):
val = row['I{0}'.format(j)]
if val == '':
val = -10 # TODO 为啥缺失数据补值为-10
feats.append('{0}'.format(val))
f_d.write(row['Label'] + ' ' + ' '.join(feats) + '\n')
#处理categorical特征
cat_feats = set()
for j in range(1, 27):
field = 'C{0}'.format(j)
key = field + '-' + row[field]
cat_feats.add(key)
feats = []
for j, feat in enumerate(target_cat_feats, start=1):
if feat in cat_feats:
feats.append(str(j))
f_s.write(row['Label'] + ' ' + ' '.join(feats) + '\n')
这里面用到了一个common.py ,这是一个公共类,后面其他文件还会用到,在这先贴出来
import hashlib, csv, math, os, pickle, subprocess
HEADER="Id,Label,I1,I2,I3,I4,I5,I6,I7,I8,I9,I10,I11,I12,I13,C1,C2,C3,C4,C5,C6,C7,C8,C9,C10,C11,C12,C13,C14,C15,C16,C17,C18,C19,C20,C21,C22,C23,C24,C25,C26"
def open_with_first_line_skipped(path, skip=True):
f = open(path)
if not skip:
return f
next(f) #将文件向下读取一行
return f
#计算特征的MD5值
def hashstr(str, nr_bins):
return int(hashlib.md5(str.encode('utf8')).hexdigest(), 16)%(nr_bins-1)+1
#处理特征
#feat=['I1-SP1', 'I2-SP1', 'I3-2', 'I4-SP0', 'I5-52', 'I6-1', 'I7-7', 'I8-SP2', 'I9-27', 'I10-SP1',
# 'I11-SP2', 'I12-', 'I13-SP2', 'C1-68fd1e64', 'C2-80e26c9b', 'C3-fb936136', 'C4-7b4723c4', 'C5-25c83c98', 'C6-7e0ccccf', 'C7-de7995b8', 'C8-1f89b562', 'C9-a73ee510', 'C10-a8cd5504', 'C11-b2cb9c98', 'C12-37c9c164', 'C13-2824a5f6', 'C14-1adce6ef',
# 'C15-8ba8b39a', 'C16-891b62e7', 'C17-e5ba7672', 'C18-f54016b9', 'C19-21ddcdc9', 'C20-b1252a9d', 'C21-07b5194c', 'C22-', 'C23-3a171ecb', 'C24-c5c50484', 'C25-e8b83407', 'C26-9727dd16']
def gen_feats(row):
feats = []
for j in range(1, 14):
field = 'I{0}'.format(j)
value = row[field]
if value != '':
value = int(value)
if value > 2: #数值特征中,值大于2的进行对数处理
value = int(math.log(float(value))**2)
else:
value = 'SP'+str(value)
key = field + '-' + str(value)
feats.append(key)
for j in range(1, 27):
field = 'C{0}'.format(j)
value = row[field]
key = field + '-' + value
feats.append(key)
return feats
#计算经常出现的特征
def read_freqent_feats(threshold=10):
frequent_feats = set()
for row in csv.DictReader(open('fc.trva.t10.txt')):
if int(row['Total']) < threshold:
continue
frequent_feats.add(row['Field']+'-'+row['Value'])
return frequent_feats
###将文件根据线程的个数分割成小的文件
def split(path, nr_thread, has_header):
#将原始的文件切片分割成每个进程要读取的文件
def open_with_header_witten(path, idx, header):
f = open(path+'.__tmp__.{0}'.format(idx), 'w')
if not has_header:
return f
f.write(header)
return f
#计算每个进程计算的行数
def calc_nr_lines_per_thread(): #wc -l 统计文件的行数
nr_lines = int(list(subprocess.Popen('wc -l {0}'.format(path), shell=True,
stdout=subprocess.PIPE).stdout)[0].split()[0])
if not has_header:
nr_lines += 1
return math.ceil(float(nr_lines)/nr_thread)
header = open(path).readline()#读取表头
nr_lines_per_thread = calc_nr_lines_per_thread()
idx = 0
f = open_with_header_witten(path, idx, header)
#将原始文件分割成小文件
for i, line in enumerate(open_with_first_line_skipped(path, has_header), start=1):
if i%nr_lines_per_thread == 0:
f.close()
idx += 1
f = open_with_header_witten(path, idx, header)
f.write(line)
f.close()
#处理特征,将categorical特征进行one-hot编码
def parallel_convert(cvt_path, arg_paths, nr_thread):
workers = []
for i in range(nr_thread):
cmd = '{0}'.format(os.path.join('.', cvt_path)) #拼接路径
for path in arg_paths: #[args['src_path'], args['dst1_path'], args['dst2_path']]
cmd += ' {0}'.format(path+'.__tmp__.{0}'.format(i))
worker = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE)
workers.append(worker)
for worker in workers:
worker.communicate()
#将多线程生成的文件合并到一个文件中
def cat(path, nr_thread):
if os.path.exists(path):
os.remove(path)
for i in range(nr_thread):
cmd = 'cat {svm}.__tmp__.{idx} >> {svm}'.format(svm=path, idx=i)
p = subprocess.Popen(cmd, shell=True)
p.communicate()
#删除生成的中间临时文件
def delete(path, nr_thread):
for i in range(nr_thread):
os.remove('{0}.__tmp__.{1}'.format(path, i))
经过上面的处理,会得到tr.gbdt.dense和tr.gbdt.sparse两个文件,我们在这贴出其中一部分数据,方便大家的理解。
| tr.gbdt.dense |
|---|
| 0 1 1 5 0 1382 4 15 2 181 1 2 -10 2 |
| 0 2 0 44 1 102 8 2 2 4 1 1 -10 4 |
| 0 2 0 1 14 767 89 4 2 245 1 3 3 45 |
| 0 -10 893 -10 -10 4392 -10 0 0 0 -10 0 -10 -10 |
| 0 3 -1 -10 0 2 0 3 0 0 1 1 -10 0 |
| 0 -10 -1 -10 -10 12824 -10 0 0 6 -10 0 -10 -10 |
| 0 -10 1 2 -10 3168 -10 0 1 2 -10 0 -10 -10 |
| 1 1 4 2 0 0 0 1 0 0 1 1 -10 0 |
| 0 -10 44 4 8 19010 249 28 31 141 -10 1 -10 8 |
| 0 -10 35 -10 1 33737 21 1 2 3 -10 1 -10 1 |
| 0 -10 2 632 0 56770 -10 0 5 65 -10 0 -10 2 |
| 0 0 6 6 6 421 109 1 7 107 0 1 -10 6 |
| tr.gbdt.sparse |
|---|
| 0 1 2 3 6 8 12 13 17 25 |
| 0 1 2 7 8 12 14 15 20 25 |
| 0 1 4 6 9 10 12 19 |
| 0 1 2 4 9 12 15 |
| 0 1 2 4 5 17 |
| 0 1 4 9 10 |
| 0 1 2 4 9 10 15 |
| 1 1 2 3 4 5 9 |
2.3- 利用GBDT算法,进行特征扩维。通过构造30课深度为7的CART树,这样将特征空间扩充到
cmd = ‘./gbdt -t 30 -s {nr_thread} te.gbdt.dense te.gbdt.sparse tr.gbdt.dense tr.gbdt.sparse te.gbdt.out tr.gbdt.out’.format(nr_thread=NR_THREAD)
执行完的部分结果如下:
| -1 148 233 228 211 144 132 171 133 130 175 241 141 235 180 148 159 166 166 193 170 138 253 131 131 177 178 156 213 163 196 |
| -1 129 210 194 199 195 129 133 133 130 147 233 141 160 178 129 147 165 144 193 161 155 133 133 130 178 133 154 149 164 196 |
| -1 129 223 181 152 157 132 175 136 145 160 230 141 130 228 129 195 137 164 194 147 225 201 143 136 133 173 154 133 203 194 |
| -1 137 133 129 130 131 131 133 153 129 163 234 178 161 153 130 147 202 135 193 201 139 129 137 233 161 129 129 256 193 210 |
| -1 193 201 129 129 129 129 169 133 129 129 129 139 137 177 129 129 173 161 129 129 131 193 131 129 198 131 135 129 131 131 |
| -1 137 133 129 129 131 131 129 158 129 129 225 129 130 133 129 147 137 135 193 129 177 129 137 129 133 129 129 256 193 193 |
| -1 129 133 129 129 141 131 133 158 130 169 233 129 137 133 130 147 161 135 193 129 138 129 137 130 181 129 129 256 193 196 |
| 1 145 98 129 133 144 129 135 133 129 175 129 137 161 81 130 131 171 129 83 129 131 129 143 137 198 129 130 129 193 137 |
| -1 153 233 152 172 160 144 211 190 157 180 249 134 191 237 144 160 182 192 196 249 238 233 131 155 254 135 156 256 175 200 |
| -1 137 223 134 129 167 131 133 153 197 162 225 134 162 190 130 147 189 135 193 209 181 130 143 153 200 133 153 256 196 196 |
2.4- 生成FFM的特征,将原来每个impression的 13(numerical)+26(categorical)+30(GBDT)=69个特征生成FFM认识的数据格式,在处理feature的时候,作者没有使用手工编码,通过了hashcode编码解决了特征编码的问题,这个在代码里面可以清楚的看到。的脚本如下:
cmd = ‘converters/parallelizer-b.py -s {nr_thread} converters/pre-b.py tr.csv tr.gbdt.out tr.ffm’.format(nr_thread=NR_THREAD)
#parallelizer-b.py
import argparse, sys
from common import *
def parse_args():
if len(sys.argv) == 1:
sys.argv.append('-h')
parser = argparse.ArgumentParser()
parser.add_argument('-s', dest='nr_thread', default=12, type=int)
parser.add_argument('cvt_path')
parser.add_argument('src1_path') #tr.csv #{nr_thread} converters/pre-b.py tr.csv tr.gbdt.out tr.ffm
parser.add_argument('src2_path') # tr.gbdt.out
parser.add_argument('dst_path') #tr.ffm
args = vars(parser.parse_args())
return args
def main():
args = parse_args()
nr_thread = args['nr_thread']
split(args['src1_path'], nr_thread, True)
split(args['src2_path'], nr_thread, False)
parallel_convert(args['cvt_path'], [args['src1_path'], args['src2_path'], args['dst_path']], nr_thread)
cat(args['dst_path'], nr_thread)
delete(args['src1_path'], nr_thread)
delete(args['src2_path'], nr_thread)
delete(args['dst_path'], nr_thread)
main()
#pre-b.py
import argparse, csv, sys
from common import *
if len(sys.argv) == 1:
sys.argv.append('-h')
from common import *
parser = argparse.ArgumentParser()
parser.add_argument('-n', '--nr_bins', type=int, default=int(1e+6))
parser.add_argument('-t', '--threshold', type=int, default=int(10))
parser.add_argument('csv_path', type=str)
parser.add_argument('gbdt_path', type=str)
parser.add_argument('out_path', type=str)
args = vars(parser.parse_args())
#################
#feats=['0:40189:1', '1:498397:1', '2:131438:1', '3:947702:1', '4:205745:1', '5:786172:1',
# '6:754008:1', '7:514500:1', '8:735727:1', '9:255381:1', '10:756430:1', '11:832677:1',
# '12:120252:1', '13:172672:1', '14:398230:1', '15:98079:1', '16:550602:1', '17:397270:1',
# '18:182671:1', '19:760878:1', '20:241196:1', '21:198788:1', '22:538959:1', '23:295561:1',
# '24:540660:1', '25:391696:1', '26:78061:1', '27:462176:1', '28:433710:1', '29:166818:1',
# '30:755327:1', '31:765122:1', '32:382381:1', '33:758475:1', '34:541960:1', '35:979212:1',
# '36:345058:1', '37:396665:1', '38:254077:1', '39:578185:1', '40:319016:1', '41:394038:1',
# '42:73083:1', '43:939002:1', '44:821103:1', '45:978607:1', '46:205991:1', '47:186960:1',
# '48:75897:1', '49:593404:1', '50:746562:1', '51:957901:1', '52:950467:1', '53:617299:1',
# '54:5494:1', '55:863412:1', '56:302059:1', '57:728712:1', '58:288818:1', '59:265710:1',
# '60:37395:1', '61:629862:1', '62:760652:1', '63:572728:1', '64:384118:1', '65:360730:1',
# '66:906348:1', '67:249369:1', '68:748254:1']
def gen_hashed_fm_feats(feats, nr_bins):
feats = ['{0}:{1}:1'.format(field-1, hashstr(feat, nr_bins)) for (field, feat) in feats]
return feats
frequent_feats = read_freqent_feats(args['threshold'])
with open(args['out_path'], 'w') as f:
for row, line_gbdt in zip(csv.DictReader(open(args['csv_path'])), open(args['gbdt_path'])):
feats = []
# feat=['I1-SP1', 'I2-SP1', 'I3-2', 'I4-SP0', 'I5-52', 'I6-1', 'I7-7', 'I8-SP2', 'I9-27', 'I10-SP1',
# 'I11-SP2', 'I12-', 'I13-SP2', 'C1-68fd1e64', 'C2-80e26c9b', 'C3-fb936136', 'C4-7b4723c4', 'C5-25c83c98', 'C6-7e0ccccf', 'C7-de7995b8', 'C8-1f89b562', 'C9-a73ee510', 'C10-a8cd5504', 'C11-b2cb9c98', 'C12-37c9c164', 'C13-2824a5f6', 'C14-1adce6ef',
# 'C15-8ba8b39a', 'C16-891b62e7', 'C17-e5ba7672', 'C18-f54016b9', 'C19-21ddcdc9', 'C20-b1252a9d', 'C21-07b5194c', 'C22-', 'C23-3a171ecb', 'C24-c5c50484', 'C25-e8b83407', 'C26-9727dd16']
for feat in gen_feats(row):
field = feat.split('-')[0]
type, field = field[0], int(field[1:])#type 为特征的类型I或C filed为索引1-39
if type == 'C' and feat not in frequent_feats:
feat = feat.split('-')[0]+'less'
if type == 'C':
field += 13
feats.append((field, feat)) #append的内容为元组,(特征的索引,特征对应的值)
for i, feat in enumerate(line_gbdt.strip().split()[1:], start=1):
field = i + 39
feats.append((field, str(i)+":"+feat))
feats = gen_hashed_fm_feats(feats, args['nr_bins'])
f.write(row['Label'] + ' ' + ' '.join(feats) + '\n')
编码完的结果如下:
| 0 0:40189:1 1:498397:1 2:131438:1 3:947702:1 4:205745:1 5:786172:1 6:754008:1 7:514500:1 8:735727:1 9:255381:1 10:756430:1 11:832677:1 12:120252:1 13:172672:1 14:398230:1 15:98079:1 16:550602:1 17:397270:1 18:182671:1 19:760878:1 20:241196:1 21:198788:1 22:538959:1 23:295561:1 24:540660:1 25:391696:1 26:78061:1 27:462176:1 28:433710:1 29:166818:1 30:755327:1 31:765122:1 32:382381:1 33:758475:1 34:541960:1 35:979212:1 36:345058:1 37:396665:1 38:254077:1 39:578185:1 40:319016:1 41:394038:1 42:73083:1 43:939002:1 44:821103:1 45:978607:1 46:205991:1 47:186960:1 48:75897:1 49:593404:1 50:746562:1 51:957901:1 52:950467:1 53:617299:1 54:5494:1 55:863412:1 56:302059:1 57:728712:1 58:288818:1 59:265710:1 60:37395:1 61:629862:1 62:760652:1 63:572728:1 64:384118:1 65:360730:1 66:906348:1 67:249369:1 68:748254:1 |
| 0 0:348385:1 1:219069:1 2:697784:1 3:349331:1 4:752753:1 5:227350:1 6:80215:1 7:514500:1 8:678809:1 9:255381:1 10:813309:1 11:832677:1 12:790331:1 13:172672:1 14:529199:1 15:855548:1 16:935437:1 17:397270:1 18:848303:1 19:760878:1 20:50216:1 21:198788:1 22:538959:1 23:295561:1 24:485163:1 25:391696:1 26:229832:1 27:462176:1 28:628917:1 29:852586:1 30:182738:1 31:765122:1 32:594502:1 33:359748:1 34:541960:1 35:979212:1 36:323983:1 37:396665:1 38:627329:1 39:807416:1 40:45887:1 41:229060:1 42:232581:1 43:740214:1 44:865018:1 45:937123:1 46:205991:1 47:186960:1 48:981846:1 49:23570:1 50:746562:1 51:542440:1 52:565877:1 53:940594:1 54:13891:1 55:277916:1 56:75600:1 57:728712:1 58:649052:1 59:945900:1 60:301662:1 61:491360:1 62:860063:1 63:18581:1 64:665899:1 65:438521:1 66:132150:1 67:441991:1 68:748254:1 |
| 0 0:348385:1 1:219069:1 2:659433:1 3:100700:1 4:742683:1 5:891364:1 6:267315:1 7:514500:1 8:574200:1 9:255381:1 10:18932:1 11:200459:1 12:85805:1 13:862327:1 14:510235:1 15:508272:1 16:111695:1 17:397270:1 18:182671:1 19:760878:1 20:50216:1 21:198788:1 22:537652:1 23:295561:1 24:445394:1 25:391696:1 26:198506:1 27:462176:1 28:434432:1 29:43420:1 30:704811:1 31:998174:1 32:614600:1 33:332451:1 34:203287:1 35:979212:1 36:195932:1 37:335222:1 38:975766:1 39:807416:1 40:274779:1 41:261882:1 42:14305:1 43:411856:1 44:821103:1 45:940252:1 46:698579:1 47:656809:1 48:421765:1 49:655530:1 50:746562:1 51:876094:1 52:749690:1 53:940594:1 54:519110:1 55:794555:1 56:188220:1 57:375384:1 58:532089:1 59:313097:1 60:472361:1 61:55348:1 62:662265:1 63:825633:1 64:871422:1 65:438521:1 66:166821:1 67:739560:1 68:348081:1 |
| 0 0:194689:1 1:855620:1 2:790098:1 3:25173:1 4:26395:1 5:819010:1 6:287534:1 7:761173:1 8:452608:1 9:530364:1 10:124999:1 11:832677:1 12:130107:1 13:172672:1 14:896024:1 15:98079:1 16:550602:1 17:397270:1 18:848303:1 19:760878:1 20:50216:1 21:198788:1 22:258180:1 23:246723:1 24:540660:1 25:895736:1 26:198506:1 27:796384:1 28:433710:1 29:236365:1 30:119424:1 31:998174:1 32:614600:1 33:758475:1 34:541960:1 35:979212:1 36:748917:1 37:335222:1 38:975766:1 39:300066:1 40:421469:1 41:315527:1 42:938004:1 43:383277:1 44:10240:1 45:937123:1 46:404863:1 47:957277:1 48:278241:1 49:619706:1 50:685274:1 51:59021:1 52:771522:1 53:848308:1 54:13891:1 55:929318:1 56:776314:1 57:728712:1 58:182964:1 59:793371:1 60:774722:1 61:599346:1 62:415917:1 63:190397:1 64:532991:1 65:702835:1 66:319263:1 67:823093:1 68:392692:1 |
3–FFM训练
下面是官方文档对数据格式的解释,这样就不难理解作者为啥前期对数据做那样的处理。
It is important to understand the difference between field' andfeature’. For example, if we have a raw data like this:
Click Advertiser Publisher
===== ========== =========
0 Nike CNN
1 ESPN BBC
Here, we have
* 2 fields: Advertiser and Publisher
* 4 features: Advertiser-Nike, Advertiser-ESPN, Publisher-CNN, Publisher-BBC
Usually you will need to build two dictionares, one for field and one for features, like this:
DictField[Advertiser] -> 0
DictField[Publisher] -> 1
DictFeature[Advertiser-Nike] -> 0
DictFeature[Publisher-CNN] -> 1
DictFeature[Advertiser-ESPN] -> 2
DictFeature[Publisher-BBC] -> 3
Then, you can generate FFM format data:
0 0:0:1 1:1:1
1 0:2:1 1:3:1
Note that because these features are categorical, the values here are all ones.
关于FFM的训练可以使用官方提供的代码库。这个代码库有个很大的优点就是增量式训练,不需要将数据全部加载到内存中。关于FFM的代码分析阅读,将会在下次的博客中分享。博客中代码的完整注释可以在我GitHub上进行下载。