转自:https://oldpan.me/archives/the-first-step-towards-tvm-1 深表感谢
前言
这是一个TVM教程系列,计划从TVM的使用说明,再到TVM的内部源码,为大家大致解析一下TVM的基本工作原理。因为TVM的中文资料比较少,也希望贡献一下自己的力量,如有描述方面的错误,请及时指出。
那啥是TVM?
《一步一步解读神经网络编译器TVM(一)——一个简单的例子》
简单来说,TVM可以称为许多工具集的集合,其中这些工具可以组合起来使用,来实现我们的一些神经网络的加速和部署功能。这也是为什么叫做TVM Stack了。TVM的使用途径很广,几乎可以支持市面上大部分的神经网络权重框架(ONNX、TF、Caffe2等),也几乎可以部署在任何的平台,例如Windows、Linux、Mac、ARM等等。
以下面一张图来形容一下,这张图来源于(https://tvm.ai/about):
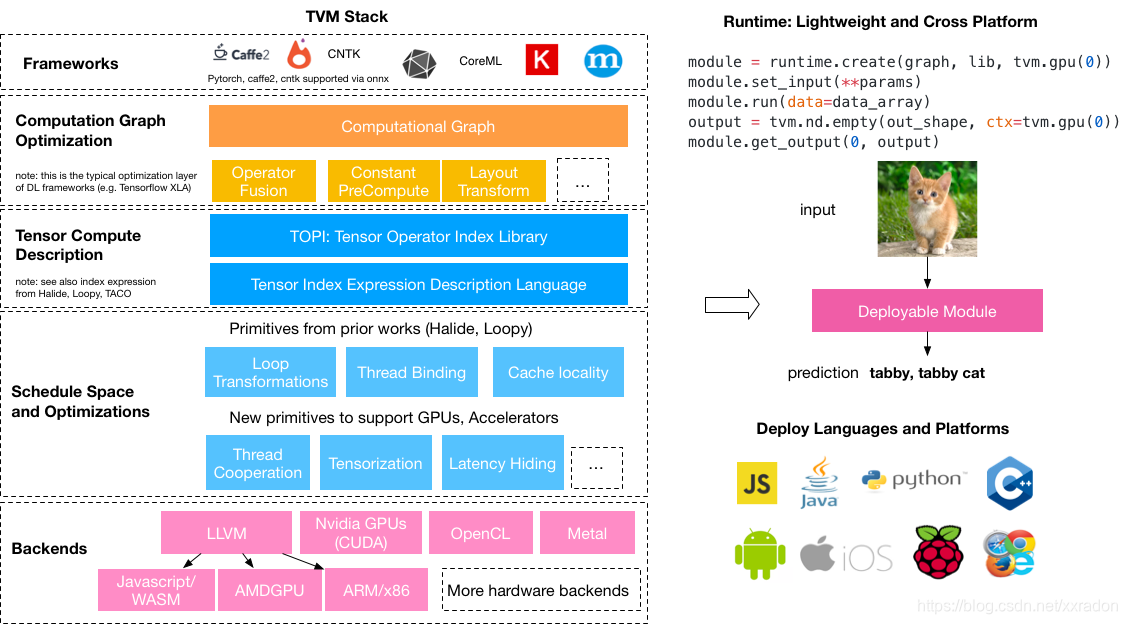
《一步一步解读神经网络编译器TVM(一)——一个简单的例子》
乍看这么多感觉非常地复杂,但我们只需要知道TVM的核心功能就可以:TVM可以优化的训练好的模型,并将你的模型打包好,然后你可以将这个优化好的模型放在任何平台去运行,可以说是与落地应用息息相关。
TVM包含的东西和知识概念都有很多,不仅有神经网络优化量化op融合等一系列步骤,还有其他更多细节技术的支持(Halide、LLVM),从而使TVM拥有很强大的功能…好了废话不说了,再说就憋不出来了,如果想多了解TVM的可以在知乎上直接搜索TVM关键字,那些大佬有很多关于TVM的介绍文章,大家可以去看看。
其实做模型优化这一步骤的库已经出现很多了,不论是Nvidia自家的TensorRT还是Pytorch自家的torch.jit模块,都在做一些模型优化的工作,这里就不多说了,感兴趣的可以看看以下文章:
利用Pytorch的C++前端(libtorch)读取预训练权重并进行预测
利用TensorRT实现神经网络提速(读取ONNX模型并运行)
利用TensorRT对深度学习进行加速
开始使用
说到这里了,感觉有必要说下:我们为什么要使用TVM?
如果你想将你的训练模型移植到Window端、ARM端(树莓派、其他一系列使用该内核的板卡)或者其他的一些平台,利用其中的CPU或者GPU来运行,并且希望可以通过优化模型来使模型在该平台运算的速度更快(这里与模型本身的算法设计无关),实现落地应用研究,那么TVM就是你的不二之选。另外TVM源码是由C++和Pythoh共同搭建,阅读相关源码也有利于我们程序编写方面的提升。
安装
安装其实没什么多说的,官方的例子说明的很详细。大家移步到那里按照官方的步骤一步一步来即可。

不过有两点需要注意下:
- 建议安装LLVM,虽然LLVM对于TVM是可选项,但是如果我们想要部署到CPU端,那么llvm几乎是必须的
- 因为TVM是python和C++一起的工程,python可以说是C++的前端,安装官方教程编译好C++端后,这里建议选择官方中的Method 1来进行python端的设置,这样我们就可以随意修改源代码,再重新编译,而Python端就不需要进行任何修改就可以直接使用了。
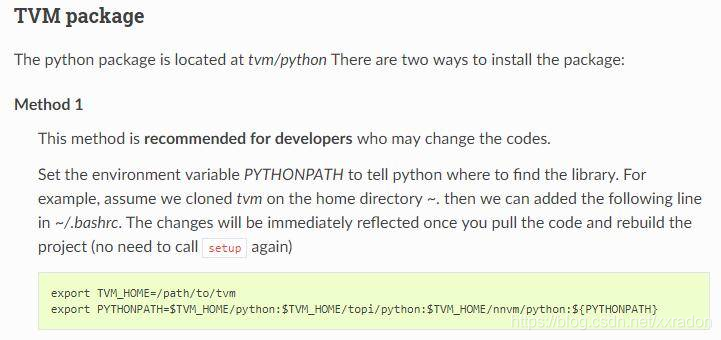
(官方建议使用Method 1)
利用Pytorch导出Onnx模型
说了这么多,演示一个例子才能更好地理解TVM到底是做什么的,所以我们这里以一个简单的例子来演示一下TVM是怎么使用的。
首先我们要做的是,得到一个已经训练好的模型,这里我选择这个github仓库中的mobilenet-v2,model代码和在ImageNet上训练好的权重都已经提供。好,我们将github中的模型代码移植到本地,然后调用并加载已经训练好的权重:
import torch
import time
from models.MobileNetv2 import mobilenetv2
model = mobilenetv2(pretrained=True)
example = torch.rand(1, 3, 224, 224) # 假想输入
with torch.no_grad():
model.eval()
since = time.time()
for i in range(10000):
model(example)
time_elapsed = time.time() - since
print('Time elapsed is {:.0f}m {:.0f}s'.
format(time_elapsed // 60, time_elapsed % 60)) # 打印出来时间
这里我们加载训练好的模型权重,并设定了输入,在python端连续运行了10000次,这里我们所花的时间为:6m2s。
然后我们将Pytorch模型导出为ONNX模型:
import torch
from models.MobileNetv2 import mobilenetv2
model = mobilenetv2(pretrained=True)
example = torch.rand(1, 3, 224, 224) # 假想输入
torch_out = torch.onnx.export(model,
example,
"mobilenetv2.onnx",
verbose=True,
export_params=True # 带参数输出
)
这样我们就得到了mobilenetv2.onnx这个onnx格式的模型权重。注意这里我们要带参数输出,因为我们之后要直接读取ONNX模型进行预测。
导出来之后,建议使用Netron来查看我们模型的结构,可以看到这个模型由Pytorch-1.0.1导出,共有152个op,以及输入id和输入格式等等信息,我们可以拖动鼠标查看到更详细的信息:
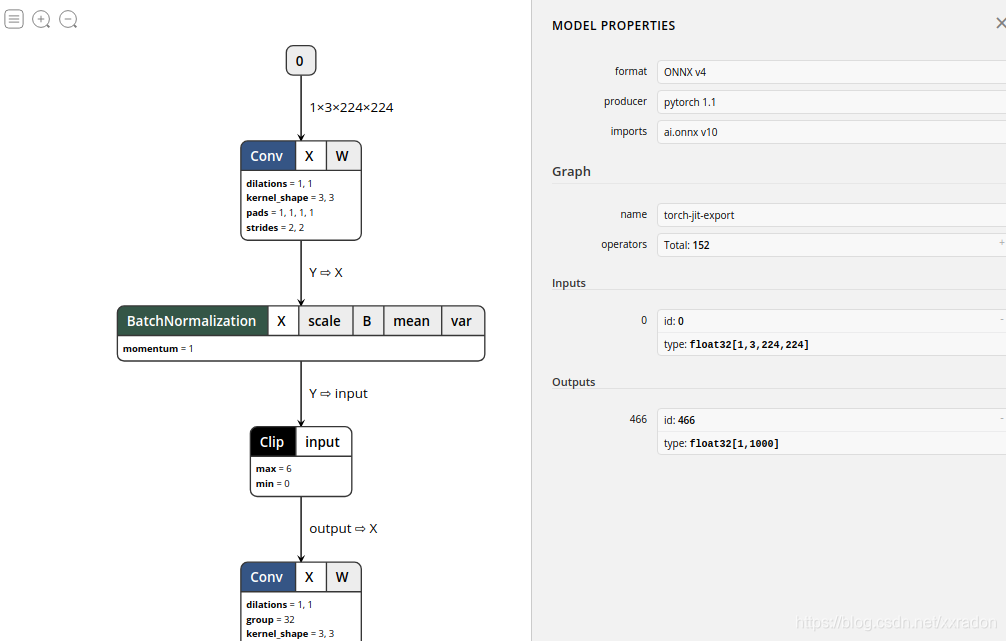
好了,至此我们的mobilenet-v2模型已经顺利导出了。
利用TVM读取并预测ONNX模型
在我们成功编译并且可以在Python端正常引用TVM后,我们首先导入我们的onnx格式的模型。这里我们准备了一张飞机的图像:

这个图像在ImageNet分类中属于404: ‘airliner’,也就是航空客机。
下面我们将利用TVM部署onnx模型并对这张图像进行预测。
import onnx
import time
import tvm
import numpy as np
import tvm.relay as relay
from PIL import Image
onnx_model = onnx.load('mobilenetv2.onnx') # 导入模型
mean = [123., 117., 104.] # 在ImageNet上训练数据集的mean和std
std = [58.395, 57.12, 57.375]
def transform_image(image): # 定义转化函数,将PIL格式的图像转化为格式维度的numpy格式数组
image = image - np.array(mean)
image /= np.array(std)
image = np.array(image).transpose((2, 0, 1))
image = image[np.newaxis, :].astype('float32')
return image
img = Image.open('../datasets/images/plane.jpg').resize((224, 224)) # 这里我们将图像resize为特定大小
x = transform_image(img)
这样我们得到的x为[1,3,224,224]维度的ndarray。这个符合NCHW格式标准,也是我们通用的张量格式。
接下来我们设置目标端口llvm,也就是部署到CPU端,而这里我们使用的是TVM中的Relay IR,这个IR简单来说就是可以读取我们的模型并按照模型的顺序搭建出一个可以执行的计算图出来,当然,我们可以对这个计算图进行一系列优化。(现在TVM主推Relay而不是NNVM,Relay可以称为二代NNVM)。
target = 'llvm'
input_name = '0' # 注意这里为之前导出onnx模型中的模型的输入id,这里为0
shape_dict = {input_name: x.shape}
利用Relay中的onnx前端读取我们导出的onnx模型
sym, params = relay.frontend.from_onnx(onnx_model, shape_dict)
上述代码中导出的sym和params是我们接下来要使用的核心的东西,其中params就是导出模型中的权重信息,在python中用dic表示:
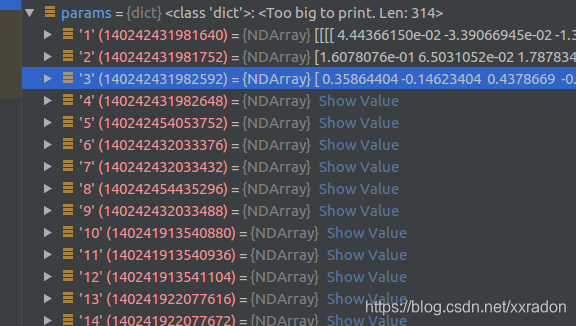
而sym就是表示计算图结构的功能函数,这个函数中包含了计算图的流动过程,以及一些计算中需要的各种参数信息,Relay IR之后对网络进行优化就是主要对这个sym进行优化的过程:
fn (%v0: Tensor[(1, 3, 224, 224), float32],
%v1: Tensor[(32, 3, 3, 3), float32],
%v2: Tensor[(32,), float32],
%v3: Tensor[(32,), float32],
%v4: Tensor[(32,), float32],
%v5: Tensor[(32,), float32],
...
%v307: Tensor[(1280, 320, 1, 1), float32],
%v308: Tensor[(1280,), float32],
%v309: Tensor[(1280,), float32],
%v310: Tensor[(1280,), float32],
%v311: Tensor[(1280,), float32],
%v313: Tensor[(1000, 1280), float32],
%v314: Tensor[(1000,), float32]) {
%0 = nn.conv2d(%v0, %v1, strides=[2, 2], padding=[1, 1], kernel_size=[3, 3])
%1 = nn.batch_norm(%0, %v2, %v3, %v4, %v5, epsilon=1e-05)
%2 = %1.0
%3 = clip(%2, a_min=0, a_max=6)
%4 = nn.conv2d(%3, %v7, padding=[1, 1], groups=32, kernel_size=[3, 3])
...
%200 = clip(%199, a_min=0, a_max=6)
%201 = mean(%200, axis=[3])
%202 = mean(%201, axis=[2])
%203 = nn.batch_flatten(%202)
%204 = multiply(1f, %203)
%205 = nn.dense(%204, %v313, units=1000)
%206 = multiply(1f, %v314)
%207 = nn.bias_add(%205, %206)
%207
}
好了,接下来我们需要对这个计算图模型进行优化,这里我们选择优化的等级为3:
with relay.build_config(opt_level=3):
intrp = relay.build_module.create_executor('graph', sym, tvm.cpu(0), target)
dtype = 'float32'
func = intrp.evaluate(sym)
最后我们得到可以直接运行的func。
其中优化的等级分这几种:
OPT_PASS_LEVEL = {
"SimplifyInference": 0,
"OpFusion": 1,
"FoldConstant": 2,
"CombineParallelConv2D": 3,
"FoldScaleAxis": 3,
"AlterOpLayout": 3,
"CanonicalizeOps": 3,
}
最后,我们将之前已经转化格式后的图像x数组和模型的参数输入到这个func中,并且返回这个输出数组中的最大值
output = func(tvm.nd.array(x.astype(dtype)), **params).asnumpy()
print(output.argmax())
这里我们得到的输出为404,与前文描述图像在ImageNet中的分类标记一致,说明我们的TVM正确读取onnx模型并将其应用于预测阶段。
我们另外单独测试一下模型优化后运行的速度和之前直接利用pytorch运行速度之间比较一下,可以发现最后的运行时间为:3m20s,相较之前的6m2s快了将近一倍。
since = time.time()
for i in range(10000):
output = func(tvm.nd.array(x.astype(dtype)), **params).asnumpy()
time_elapsed = time.time() - since
print('Time elapsed is {:.0f}m {:.0f}s'.
format(time_elapsed // 60, time_elapsed % 60)) # 打印出来时间
当然,这个比较并不是很规范,不过我们可以大概分析出TVM的一些可用之处了。
后记
这一篇仅仅是带大家了解一下什么是TVM以及一个简单例子的使用,在接下来的文章中会涉及到部分TVM设计结构和源码的解析。可能涉及到的知识点有:
- 简单编译器原理
- C++特殊语法以及模板元编程
- 神经网络模型优化过程
- 代码部署
等等,随时可能会进行变化。
人工智能已经开始进入嵌入式时代,各式各样的AI芯片即将初始,将复杂的网络模型运行在廉价低功耗的板子上可能也不再是遥不可及的幻想,不知道未来会是怎么样,但TVM这个框架已经开始走了一小步。
