原创文章,转载请说明来自《老饼讲解-BP神经网络》:bp.bbbdata.com
关于《老饼讲解-BP神经网络》:
本网结构化讲解神经网络的知识,原理和代码。
重现matlab神经网络工具箱的算法,是学习神经网络的好助手。
目录
感知机(perceptron)由Rosenblatt在1957提出,只解决二分类问题,
它的输出为-1或1,是神经网络与支持向量基的基础。
本文先讲述感知机的原理、算法流程及代码实现,
然后讲解matlab中单层感知机神经网络的原理和代码实现(非调包)。
最后讲解matlab如何通过工具箱使用感知机神经网络。
一、初识感知机
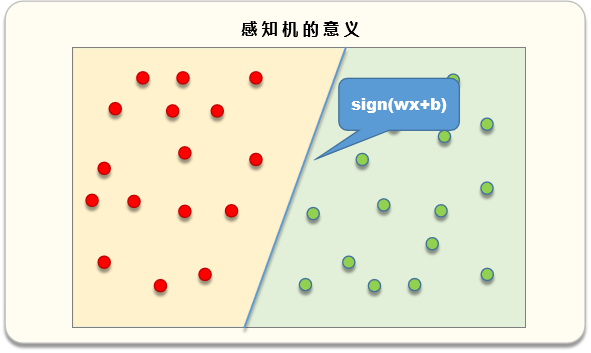
01.感知机的思想
在输入为二维的时候,
单层感知机就相当于找出一条直线(在多维的时候,就是平面或超平面),
将平面一分为二,一边为正样本,另一边为负样本
02.简单Demo
通过matlab工具箱实现一个简单Demo
matlab工具箱使用感知机神经网络的Demo代码(2014b版matlab实测已跑通):
% 训练数据
X = [0 0 1 1; 0 1 0 1];
y = [0 1 1 1;];
%训练
net = newp(X,y); % 建立网络
[net,tr] = train(net,X,y); % 训练网络
%预测
py = sim(net,X) %使用网络进行预测
二、感知机原理与自实现感知机
01.模型数学表达式
感知机的模型数学表达式为:
其中,
02.感知机的训练目标与损失函数
训练目标
感知机的误差评估函数为误分类的占比
其中,,即感知机对第i个样本的预测值。
感知机的训练目标就是找出一组w,b,使E最小化。
损失函数
感知机的训练可以使用梯度下降法,
但由于误差评估函数,不方便求导,
所以先构造一个与误差评估函数相关的损失函数,
然后用损失函数的梯度来引导w,b的调整。
可以用以下函数作为损失函数,来引导w,b的迭代方向。
上式的意义如下:
预测正确时,为正,
预测错误时,
即,网络越正确,L(w,b)越小,网络越错误,L(w,b)越大。
则我们要令L更小,只要往w和b的负梯度方向调整即可。
03.损失函数的梯度
可算得损失函数L中 w 和 b 的梯度如下:
(1) w的梯度
(2) b的梯度
单样本时w,b的梯度
感知机一般用单样本训练,
由上可算得对于单个样本
训练时,w,b的梯度为:
04.算法流程
感知机采用逐样本训练方法,
具体训练流程如下:
1、初始化
将w和b的元素全部初始化为0。
2、逐样本训练
逐个样本训练 w,b:
------如果训练样本的预测值与真实值不一致,则往负梯度方向更新w,b( 其中,lr为学习率):
----------
----------
3、检测是否终止训练
如果总体预测误差达到目标,或达到最大训练步数,则终止训练,否则重复2
误差的评估:
4、输出结果
输出w,b和网络最终的预测误差
已被证明,在样本点可分的情况下,算法经过有限次迭代,感知机肯定能将样本完全分开。
证明可参考 李航-《统计学习方法》2.3.2节。
05.实现代码
下面是根据以上算法流程,自己编写的一个感知机的实现Demo
% 本代码展示一个感知机模型的训练DEMO
% ----------训练数据-------------------
X = [0 0 0.2 1 1 0.8; 0 1 0.5 0 1 0.3];
y = [-1 -1 -1 1 1 1 ];
%----------参数设置与常量计算-----------------
[in,sn] = size(X); % 输入个数与样本个数
goal = 0; % 训练目标
lr = 0.1; % 学习率
epochs = 100; % 最大训练步数
% --------初始化权重---------------
w = zeros(1,in); % 初始化权重
b = 0; % 初始化阈值
% ----------感知机训练---------------------
for i = 1:epochs
% 逐样本训练
for j = 1:sn
cur_x = X(:,j); % 当前训练样本
cur_y = y(:,j);
py = 2*((w*cur_x+b)>=0)-1; % 当前训练样本的预测值
if(py~=cur_y)
w = w + lr*cur_y*cur_x';
b = b + lr * cur_y;
end
end
% 如果误差达到目标,则退出训练
e = sum(( 2*((w*X+b)>=0)-1 )~=y)/sn; % 计算误差
if e<=goal
break;
end
end
% -------------绘制结果----------------------
x_line = [min(X(1,:)),max(X(1,:))];
y_line =(-w(1)*x_line-b)/w(2);
plot(x_line,y_line)
hold on
plot(X(1,y==1),X(2,y==1),'bo')
hold on
plot(X(1,y==-1),X(2,y==-1),'k*')
hold on
axis([min(X(1,:))-1 max(X(1,:))+1 min(X(2,:))-1 max(X(2,:))+1]) 结果如下
在结果中可以看到,感知机模型把两类样本点完美地分开。

三、matlab中的感知机神经网络
matlab中的感知机神经网络是由感知机演变而来,
它是一个两层的神经网络,只有输入层与输出层。
01.感知机神经网络的拓扑结构
这里举例说明,
一个2输入3输出的感知机神经网络拓扑图如下:

输出层的激活函数支持hardlim和hardlims,两者的区别如下:
当输出层的激活函数为hardlim每个输出的输出值是0或1,
而当输出层的激活函数为hardlims每个输出的输出值是-1或1。
mamtlab中默认激活函数为hradlim
02.感知机神经网络的数学表达式
激活函数为hardlim时:
激活函数为hardlims时:
由于matlab的默认激活函数为hardlim,
而hardlim和hardlims两者没有本质的区别,下面下我们只介绍hardlim。
03.辨识:与二分类感知机的区别
(1) 上篇感知机介绍的为二分类,只有一个输出,而这里的神经网络支持多输出。
(2) matlab感知机神经网络默认使用的激活函数为hardlim,而上篇的二分类感知机是hardlims
总的来说,matlab的感知机神经网络默认输出格式为one-hot编码,即[0 1 0 0]这类的格式。
04.训练目标与损失函数
重新强调,下面统一默认为hardlim激活函数,即输出为{0,1}。
感知机神经网络的训练目标-误差函数
感知机的误差评估函数为预测错误样本个数的占比:
其中,
m:输出个数
n:样本个数:第i个样本的第j个输出。
:网络对第i个样本第j个输出的预测值。
感知机的训练目标就是找出一组w,b,使E最小化。
损失函数
感知机神经网络的训练可以使用梯度下降法,
但由于误差评估函数,不方便求导,
所以先构造一个与误差评估函数相关的损失函数,
然后用损失函数的梯度来引导w,b的调整。
可以用以下函数作为损失函数,来引导w,b的迭代方向。
05.损失函数的梯度
可算得损失函数L中 w 和 b 的梯度如下:
(1) w的梯度
(2) b的梯度
单样本时w,b的梯度
感知机一般用单样本训练,
由上可算得对于单个样本x_i
训练时,w,b的梯度为:
上式也可以改写成如下形式:
其中,
是网络对
的预测值。
06.算法流程
感知机采用逐样本训练方法,具体训练流程如下:
1、初始化
将w和b的元素全部初始化为0。2、逐样本训练
逐个样本训练w,b:
其中,yi为当前训练样本的真实y值,pi为网络对当前训练样本的预测值
3、检测是否终止训练
如果总体预测误差达到目标,或达到最大训练步数,则终止训练,否则重复2
误差的评估:
4、输出结果
输出 网络参数w,b 和网络最终的预测误差
07.代码实现-自己实现newp
我们细扒matlab神经网络工具箱newp的源码后,
去除冗余代码,重现简版newp代码,代码与newp的结果完全一致。
通过本代码的学习,可以完全细节的了解感知机神经网络的实现逻辑。
function testPnet()
%本代码来自bp.bbbdata.com
%本代码模仿matlab神经网络工具箱的newp函数自写感知机神经网络,
%代码主旨用于教学,供大家学习理解newp函数的内部机制与感知机神经网络原理
%--------------------------------------------
% ----------训练数据-------------------
X = [0 0 1 1; 0 1 0 1];
y = [0 1 0 1;1 0 0 0;0 0 1 0];
%-----------参数设置-------------------
epochs = 100; % 迭代步数
%---------调用自写函数进行训练---------
%通过自己建立模型训练网络,获得w,b
rand('seed',70);
[w,b,e,Erc]=trainPnet(X,y,epochs);
py = predictPnet(w,b,X); %用训练好的感知机预测类别
% 自写函数的结果
w
b
% -----调用工具箱进行训练--------------
% 调用工具箱进行训练
rand('seed',70);
net = newp([0 1; -2 2],3);
net.trainParam.epochs = epochs;
[net,tr] = train(net,X,y);
% 工具箱的结果
tool_w=net.IW{1}
tool_b=net.b{1}
% -------自写方法与工具箱的差异-----------------
maxECompareNet = max([max(abs(w(:)-tool_w(:))),...
max(abs(b(:)-tool_b(:))),max(abs(Erc(:)-tr.perf(:)))]);
disp(['自写代码与工具箱权重阈值的最大差异:',num2str(maxECompareNet)])
end
% ----感知机训练函数-----
function [w,b,e,Erc]=trainPnet(X,y,epochs)
%----------参数设置与常量计算-----------------
[in,sn]=size(X); % 输入个数与样本个数
on = size(y,1); %输出个数
goal =0; %训练目标
% ---------网络权重与相关变量初始化---------------
w = zeros(on,in); %初始化权重
b = zeros(on,1); %初始化阈值
py = predictPnet(w,b,X); %预测训练样本
e= sum(sum(abs(y -py)))/length(py(:)); % 计算误差
Erc = [e]; %记录误差
% ----------网络权重训练---------------------
for i = 1:epochs
% 逐样本训练
for j = 1:sn
% 计算预测误差
cur_x = X(:,j); % 当前训练样本
py = predictPnet(w,b,cur_x); % 当前训练样本的预测值
e1 = y(:,j) - py; % 当前训练样本的误差
% 调整权重
w = w + e1*cur_x'; % 调整权重w
b = b+e1; % 调整阈值b
end
% 计算网络误差并记录
py = predictPnet(w,b,X); % 网络的预测值
e = sum(sum(abs( y -py)))/length(py(:)); % 网络的误差
Erc = [Erc,e]; % 记录本次误差
% 如果误差达到目标,则退出训练
if e<=goal
break;
end
end
end
% ----感知机预测函数-----
function y = predictPnet(w,b,x)
y = (w*x+repmat(b,1,size(x,2)))>=0;
end运行结果共三部分
1. 自写代码求得的网络权重与阈值
2. 调用工具箱求得的网络权重与阈值
3. 自写代码与工具箱的结果对比
从运行结果可以看到,自写代码与工具箱的结果一样,说明扒出的逻辑与工具箱的一致。



四、matlab神经网络工具箱的感知机实现与说明
在实际使用中,我们更多时候是使用matlab自带的神经网络工具箱的newp来实现感知机神经网络,
下面我们学习工具箱的使用说明。
01. 简单Demo
matlab工具箱使用感知机神经网络的Demo代码(2014b版matlab实测已跑通):
%代码说明:newp的matlab工具箱使用Demo
%来自《老饼讲解神经网络》bp.bbbdata.com ,matlab版本:2014b
%-----------------------------------------------------
% 训练数据
X = [0 0 1 1; 0 1 0 1];
y = [0 1 1 1;];
%训练
net = newp(X,y); % 建立网络
[net,tr] = train(net,X,y); % 训练网络
%预测
py = sim(net,X) %使用网络进行预测
02. 工具箱说明
语法:
net = newp(p,t,tf,lf)描述:
感知机用于解决简单的(例如线性可分)分类问题。入参说明
P: 用于训练的输入数据。每列代表一个样本,有多少个样本,就有多少列。
T:用于训练的输出数据。每列代表一个样本,有多少个样本,就有多少列。
TF:传递函数,默认为'hardlim',支持hardlim和hardlims。
LF:学习函数,默认为'learnp',支持learnp和learnpn。备注:
感知机可以在有限步数内解决将线性可分的分类问题。如果输入变量较多,learnpn比learnp在训练速度上更加快。
相关文章