KMP算法
背景介绍
在文本编辑中,我们经常要在一段文本中某个特定的位置找出某个特定的字符或模式。再比如,在HTTP协议里的字节流,有各种关键的字节流字段,对HTTP数据进行解释就需要用到模式匹配算法。由此,便产生了字符串的匹配问题。
KMP算法是由Knuth,Morris,Pratt三人共同提出的模式匹配算法,
其对于任何模式和目标序列,都可以在线性时间(n+m)内完成匹配查找,
而不会发生退化,是一个非常优秀的模式匹配算法。
问题:求一个字符串T是否在S中出现过。
朴素匹配算法
咱们先来看朴素匹配算法。
- 假设现在原始串S串匹配到 i 位置,模式串T串匹配到 j 位置
- 如果当前字符匹配成功,即S[i+j] == T[j]
- i 不变,j++,继续匹配下一个字符
- 如果失配,即S[i+j] != T[j]
- 令i++,j = 0,即每次匹配失败时,模式串T相对于原始串S向右移动一位。
换言之,只要模式串匹配失败,那就往右边移动一位,简单直接,也干脆暴力。
假定原始串S串为“acaabc”,模式串T 串为“aab”,
那么模式串去匹配原始串的整个过程如下图所示:

那KMP做了什么改进呢?KMP其实是在一步步往后匹配的过程中,后面的匹配会设法利用前面的匹配信息,从而减少不必要的匹配。
KMP算法
咱们首先给出KMP算法的结论:
- 假设现在原始串S串匹配到 i 位置,模式串T串匹配到 j 位置
- 如果当前字符匹配成功,即S[i] == T[j]
- 令i++,j++,继续匹配下一个字符;
- 如果失配,即S[i] != T[j]
- 令i不变,j = next[j],(next[j] <= j - 1),即模式串T相对于原始串S向右移动了至少1位。
换言之,当匹配失败时,模式串向右移动的位数为:
失配字符所在位置 - 失配字符对应的next 值,即移动的实际位数:j - next[j]> =1
举例:
有这样一个字符串:
BBC ABCDAB ABCDABCDABDE
我想知道里面是否包含另一个字符串:
ABCDABD
首先,字符串"BBC ABCDAB ABCDABCDABDE"的第一个字符与搜索词 "ABCDABD"的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。

字符串"BBC ABCDAB ABCDABCDABDE"的第二个字符与搜索词 "ABCDABD"的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。

接着比较,直到主串的字符与搜索词的第一个字符相同为止。
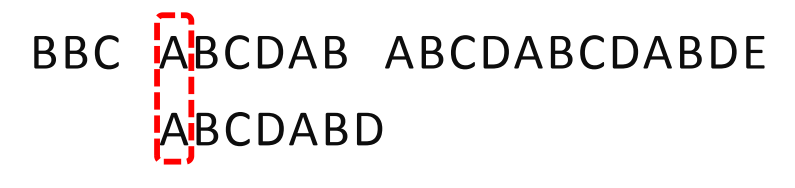
还是相同。

直到主串有一个字符,与搜索词对应的字符不相同为止。
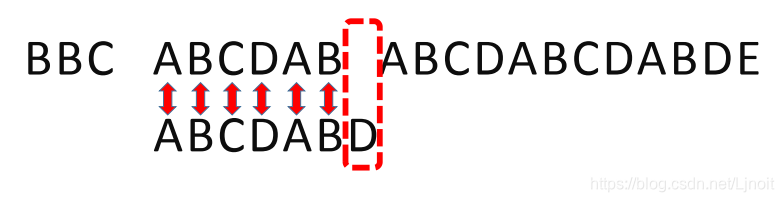
这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。
这样做虽然可行,但是效率很差,因为你要把"搜索位置"移到已经比较过的位置,重比一遍。

那么我们想什么办法来解决这一问题呢?
一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是"ABCDAB"。KMP算法的想法是,设法利用这个已知信息,不要把"搜索位置"移回已经比较过的位置,继续把它向后移,这样就提高了效率。
怎么利用这个已知信息呢?
可以针对搜索词,算出一张《NEXT值表》,即失败指针。
这张表是如何产生的,等下再介绍,这里只要会用就可以了。
| 搜索词 | A | B | C | D | A | B | D |
|---|---|---|---|---|---|---|---|
| Next值 | -1 | 0 | 0 | 0 | 0 | 1 | 2 |
已知空格与D不匹配时,前面六个字符"ABCDAB"是匹配的。查表可知,字符D对应的“Next值"为2,因此按照下面的公式算出向后移动的位数:
移动位数=已匹配的字符数-对应的NEXT值
因为6-2等于4,所以将搜索词向后移动4位。
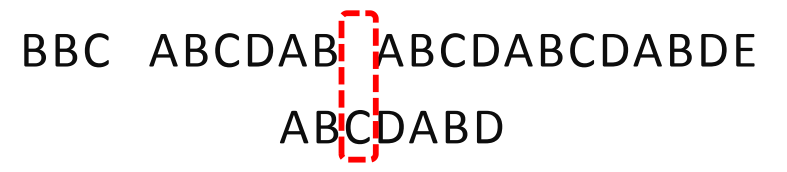
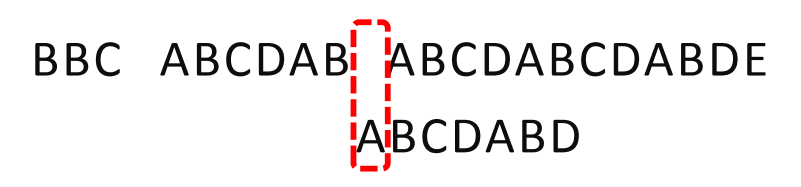
因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2 (“AB”) ,C对应的“NEXT值"为0。 所以,移动位数=2-0,结果为2,于是将搜索词向后移2位。
| 搜索词 | A | B | C | D | A | B | D |
|---|---|---|---|---|---|---|---|
| Next值 | -1 | 0 | 0 | 0 | 0 | 1 | 2 |
因为空格与A不匹配,0-(-1)=1, 所以继续后移一位。
逐位比较,直到发现C与D不匹配。于是,移动位数=6-2,继续将搜索词
向后移动4位。
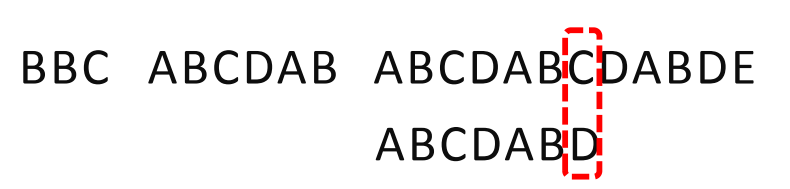
逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数=7-0,再将搜索词向后移动7位,这里就不再重复了。

下面介绍《NEXT值表》 是如何产生的。
| 搜索词 | A | B | C | D | A | B | D |
|---|---|---|---|---|---|---|---|
| Next值 | -1 | 0 | 0 | 0 | 0 | 1 | 2 |
第一位的next值必定为-1;
计算第n个字符的NEXT值:
1 查看第n-1个字符对应NEXT值,设为a;
2 判断a是否为-1,若为-1,则第n个字符next值 为0
3 若不为-1,将第n-1个字符与第a个字符比较
4 如果相同,第n个字符对应的NEXT值为a+1
5 如果不同,令a等于第a个字符的NEXT值,执行第第2步。
KMP算法代码实现
next[0]表示为-1的写法
void getnext(char *t,int *next){
int i=0,j=-1,lent=strlen(t);
next[0]=-1;
while(i<lent) {
if(j==-1 || t[i]==t[j]) {
i++;j++; next[i]=j;
} else j=next[j];
}
}
next[0]标记为0的写法
void getnext(char *t,int *next){
int lent=strlen(t);
next[0]=next[1]=0;
for(int i=1; i<lent; i++) {
int j=next[i];
while (j && t[i]!=t[j]) j=next[j];
next[i+1]=t[i]==t[j]? j+1:0;
}
}
匹配的写法next[0]=-1
void match(char *s,char *t){
int lens=strlen(s),lent=strlen(t);
int i=j=0;
while(i<lens) {
if(j==-1 || s[i]==t[j]) {
i++; j++;
} else j=next[j];
if (j==lent) break; //找到匹配了
}
}
匹配的写法next[0]=0
void match(char *s,char *t){
int lens=strlen(s),lent=strlen(t);
int j=0;
for(int i=0; i<lens; i++) {
while (j && s[i]!=t[j]) j=next[j];
if(s[i]==t[j]) j++;
if(j==lent) break;//找到了
}
}
例题1 Number Sequence
HDU-1711
链接:http://acm.hdu.edu.cn/showproblem.php?pid=1711
https://vjudge.net/problem/HDU-1711

题目大意
给你一个长度为n的a串,长度为m的b串,m<=10000,n<=1000000,
找出b在中出现的第一个位置,如果没有,就输出-1。
思路
模板题,详细看上面。
代码
#pragma GCC optimize(3,"Ofast","inline")
#pragma G++ optimize(3,"Ofast","inline")
#include <iostream>
#include <cstdio>
#include <cmath>
#include <cstring>
#include <algorithm>
#define R register int
#define re(i,a,b) for(R i=a; i<=b; i++)
#define ms(i,a) memset(a,i,sizeof(a))
using namespace std;
typedef long long ll;
int const N=2000005;
int const M=100005;
int n,m;
int nt[M],s[N],t[M];
void getnext() {
nt[0]=nt[1]=0;
for(int i=1; i<m; i++) {
int j=nt[i];
while (j && t[i]!=t[j]) j=nt[j];
nt[i+1]=t[i]==t[j] ? j+1 : 0;
}
}
int kmp() {
int j=0;
for(int i=0; i<n; i++) {
while(j && s[i]!=t[j]) j=nt[j];
if(s[i]==t[j]) j++;
if(j==m) return i-m+2;
}
return -1;
}
int main(){
int T;
scanf("%d",&T);
while(T--) {
scanf("%d%d",&n,&m);
for(int i=0; i<n; i++) scanf("%d",&s[i]);
for(int i=0; i<m; i++) scanf("%d",&t[i]);
getnext();
printf("%d\n",kmp());
}
return 0;
}
例题2 Period
LA-3026 POJ-1961 HDU-1358 UVA-1328
链接:
LA: https://icpcarchive.ecs.baylor.edu/index.php?option=com_onlinejudge&Itemid=8&page=show_problem&problem=1027
UVA: https://onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem&problem=4074
POJ: http://poj.org/problem?id=1961
HDU: http://acm.hdu.edu.cn/showproblem.php?pid=1358
vjudge: https://vjudge.net/problem/HDU-1358

题目大意
给定一个长度为n的字符串s,求他的每个前缀的最短循环节。换句话说,对于每个i(2<=i<=n),求一个最大的整数k>1(如果k存在),使得s的前i个字符组成的前缀是某个字符串重复k次得到。输出所有存在的i和对应的k。
比如,对于字符串aabaabaabaab,只有当i=2,6,9,12时k存在,分别为2,2,3,4
输入:
输入有多组数据。每组数据第一行为正整数n(2<=n<=10^6),第二行为一个字符串S,输入结束标志为n=0。
输出:对于每组数组,按照从小到大的顺序输出每个i和对应的K,一对整数占一行。
思路
根据后缀函数的定义,“错位部分”长度为i-f[i] (f数组就是next数组)
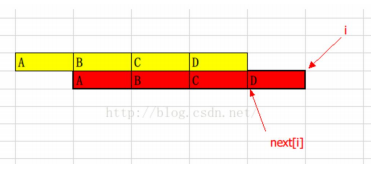
如果i刚好是i-f[i]的倍数,那么恰好就出现了循环节。
代码
#include <iostream>
#include <cstdio>
#include <cmath>
#include <cstring>
#include <algorithm>
using namespace std;
typedef long long ll;
int const N=1e6+5;
int n;
int f[N];
char s[N];
void getnt() {
f[0]=f[1]=0;
int j=0;
for(int i=1; i<n; i++) {
j=f[i];
while (j && s[i]!=s[j]) j=f[j];
f[i+1]=s[i]==s[j] ? j+1 : 0;
}
}
int main(){
int cas=0;
while(scanf("%d",&n)!=EOF && n) {
scanf("%s",s);
getnt();
printf("Test case #%d\n",++cas);
for(int i=2; i<=n; i++)
if(i%(i-f[i]) ==0 && f[i]>0)
printf("%d %d\n",i,i/(i-f[i]));
printf("\n");
}
return 0;
}
其他练习
-
HDU-3336 Count the string
链接:http://acm.hdu.edu.cn/showproblem.php?pid=3336
https://vjudge.net/problem/HDU-3336 -
HDU-2087 剪花布条
链接:http://acm.hdu.edu.cn/showproblem.php?pid=2087
https://vjudge.net/problem/HDU-2087 -
POJ-3461 Oulipo
链接:http://poj.org/problem?id=3461
https://vjudge.net/problem/POJ-3461 -
POJ-3080 Blue Jeans
链接:http://poj.org/problem?id=3080
https://vjudge.net/problem/POJ-3080 -
HDU-1867 A + B for you again
链接:http://acm.hdu.edu.cn/showproblem.php?pid=1867
https://vjudge.net/problem/HDU-1867 -
POJ-2185 Milking Grid
链接:http://poj.org/problem?id=2185
https://vjudge.net/problem/POJ-2185
附:其他算法的时间复杂度比较
令 m 为模式的长度, n 为要搜索的字符串长度, k为字母表长度。
| 算法 | 预处理时间 | 匹配时间 |
|---|---|---|
| 朴素算法 | 0 (无需预处理) | Θ(nm) |
| Rabin-Karp算法 | Θ(m) | 平均 Θ(n + m), 最差 Θ((n−m)m) |
| 基于有限状态机的搜索 | Θ(mk) | Θ(n) |
| 克努斯-莫里斯-普拉特算法(KMP算法) | Θ(m) | Θ(n) |
| Boyer-Moore字符串搜索算法 | Θ(m + k) | 最好Ω(n/m),最坏 O(n) |
| Bitap算法 | Θ(m + k) | Θ(nm) |
