BF算法
提到字符串匹配,最先想到的就是模式串与主串一个字符一个字符的进行匹配,当遇到不匹配的字符时,模式串则往后移动一位,继续从模式串的第一位开始匹配,这种匹配算法也被称为 BF算法,即“暴力匹配算法”。时间复杂度为O(n*m),其中n、m表示主串与模式串的长度。

BM算法、KMP算法都是在BF算法的基础之上进行优化,即在匹配的过程中,希望跳过更多的字符。
KMP算法思路
既然字符串在比对失败的时候,我们已经知道读过哪些字符了,有没有可能避免“跳回下一个字符再重新匹配”的步骤呢?

KMP算法的基本思路就是当遇到一个不匹配的字符时,利用已经遍历过的模式串,来避免暴力算法中的“回退(backup)”的步骤。换句话说就是不希望递减主串的指针,让其永远向前移动。
举个栗子:
在 主串-ABABABCAA 中 匹配 模式串-ABABC

当匹配时,发现子串的末尾字符与主串对应字符并不匹配,但主串的后缀与子串的前缀相匹配,则可以跳过两个字符,将子串往后移动两位,继续匹配。

那我们怎么知道当每次遇到不匹配字符时该跳过多少个字符呢?
这里就要用到KMP算法中定义的next数组了。
举个栗子:

这里我们先不管next数组时如何生成的,先来看看他的功能和用途。
KMP算法当遇到字符不匹配的情况时, 会去看最后一个匹配的字符它所对应的next数值。

在这个例子中,最后一个匹配的字符对应的next数值为2,于是我们则将子串向后移动两位,使其在主串中跳过两个字符,就可以继续往后匹配。
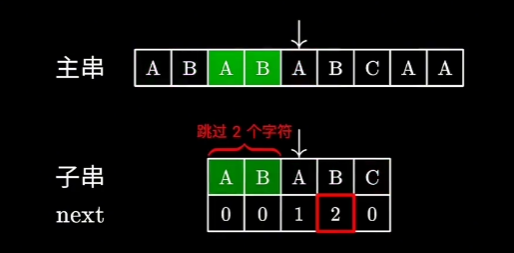
next数组元素的数值,则代表子串可以“跳过匹配”的字符个数。
由于可以不用回退指针,只需要一次主串的遍历就可以完成匹配,效率自然会比暴力算法高很多。
public int kmpSearch(char[] txt, char[] patt){ // txt代表主串,patt代表模式串
int[] next =buider_nexts(patt); // 假设已经计算出了next数组
int i = 0; // 主串中的指针
int j = 0; // 子串中的指针
while (true){
if (i == txt.length) return -1;
if (txt[i] == patt[j]) { // 字符匹配,指针后移一位继续匹配
i++;
j++;
} else if (j > 0) { // 字符不匹配,则根据next数值跳过子串前几个字符的匹配
j = next[j-1];
}else { // 子串的第一个字符就不匹配,则直接后移一位
++i;
}
if (j == patt.length) return i-j; // 如果j已经达到子串末尾,则匹配成功,返回匹配的起始位置
}
}注意主串的指针 i 永不递减,这也是KMP算法的精髓。
next数组的生成
之前讲到,next数组中的数值代表在匹配失败的时候,子串中可以跳过的匹配的字符个数。但为什么可以这么做呢?
通过前面的例子可以发现,最后匹配的两个AB与跳过的最前面的两个AB是一样的。


换句话说,对于子串的前四个字符,它们拥有一个共同的前缀和后缀AB,长度为2。
next数组的本质就是寻找子串中“相同前后缀的长度”,并且一定是最长前后缀。
举个栗子:

在这个子串中,虽然前缀与后缀的A是相同的,但并不是最长的,而ABA才是最长的相同前后缀,因此next数值为3。
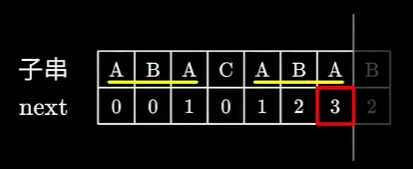
但是要注意,我们要找的前后缀不能是子串本身,如果跳过了子串本身长度的字符个数,则没有意义了。
next数组的计算
以子串ABABC为例,计算next数组。

- 对于第一个字符,显然不存在相同前后缀,next为0
- 对于前二个字符,没有相同前后缀,next为0
- 对于前三个字符,有相同前后缀A,next为1
- 对于前四个字符,有相同前后缀AB,next为2
- 对于前五个字符,没有相同的前后缀,next为0
但是算法该如何实现呢?
我们可以使用for循环暴力求解,但是效率太低。其实这里可以采用递推的方式快速求解next数组,它的巧妙之处是会不断利用已知信息来避免重复运算。
举个栗子:

假设已知当前共同前后缀,且长度为2,继续向下匹配则有两种情况。
1.如果下一个字符依然相同,则构成了一个更长的共同前后缀,且长度为之前的长度+1。

2.如果下一个字符不相同,则需要寻找是否存在更短的相同前后缀。

那如何找到更短的相同前后缀呢?
在前面的计算中已经知道在这个不匹配字符B的前面有一个长度为3的相同前后缀,我们则可以直接在左边寻找共同的前后缀,而左边的最长前后缀通过查表可以得到长度为1,则又回到了最初的步骤,检查下一个字符是否相同,如果相同则可以构建一个更长的前后缀,长度+1即可。

对比动画了解:

KMP算法next数组生成代码:
private static int[] buider_nexts(char[] patt) {
int[] next = new int[patt.length]; // next数组,且第一个元素为0
next[0] = 0;
int prefix_len = 0; // 当前公共前后缀的长度
int i = 1;
while (i < patt.length){
if (patt[prefix_len] == patt[i]){ // 字符匹配,则将prefix_len+1,存入对应next数组中
prefix_len++;
next[i] = prefix_len;
}else{
if (prefix_len == 0){ // 如果不存在相同前后缀则直接把next设为0
next[i] = 0;
i++;
}else{
prefix_len = next[prefix_len-1]; // 字符不匹配则直接查表看看存不存在更短的共同前后缀
}
}
}
return next;
}完整代码:
public int kmpSearch(char[] txt, char[] patt){
int[] next =buider_nexts(patt); // 假设已经计算出了next数组
int i = 0; // 主串中的指针
int j = 0; // 子串中的指针
while (true){
if (i == txt.length) return -1;
if (txt[i] == patt[j]) { // 字符匹配,指针后移一位继续匹配
i++;
j++;
} else if (j > 0) { // 字符不匹配,则根据next数值跳过子串前几个字符的匹配
j = next[j-1];
}else { // 子串的第一个字符就不匹配,则直接后移一位
++i;
}
if (j == patt.length) return i-j; // 如果j已经达到子串末尾,则匹配成功,返回匹配的起始位置
}
}
private int[] buider_nexts(char[] patt) {
int[] next = new int[patt.length]; // next数组,且第一个元素为0
next[0] = 0;
int prefix_len = 0; // 当前公共前后缀的长度
int i = 1;
while (i < patt.length){
if (patt[prefix_len] == patt[i]){ // 字符匹配,则将prefix_len+1,存入对应next数组中
prefix_len++;
next[i] = prefix_len;
i++;
}else{
if (prefix_len == 0){ // 如果不存在相同前后缀则直接把next设为0
next[i] = 0;
i++;
}else{
prefix_len = next[prefix_len-1]; // 字符不匹配则直接查表看看存不存在更短的共同前后缀
}
}
}
return next;
}