一、序言
开局划重点,本程序更新于2020/02/27,之后大众点评估计如果又出了什么新的反爬技术了,本文可能就不适用了。
很久之前就听过爬虫,但都没有自己亲手去写过,前几天有朋友突然来问我会不会爬虫,并想要我帮他爬点东西,我也就趁此机会来尝试一下,便接下这个任务,实操一下爬虫这个东西。
任务:
抓取大众点评某个商户的所有评论
众所周知,程序员写代码的第一步就是打开某大型同性交友网站,我也先百度查了一些已有的文章了解一下,发现写这个爬虫主要的难点在于:
- IP被封
- 评论的内容被加密
- 时不时跳出来的验证码
对于封IP来讲,在IP被封之前,可以设置每抓取一个页面之后延迟一些时间,我设置了延时10-25秒,这个设置其实已经可以很大程度上避免IP被封了,假如IP还是不幸被封,那只能去找代理(一般要花钱,有钱就能为所欲为)。
对于评论的内容被加密,这个是这篇文章讲的重点内容,后面详述。
对于时不时跳出来的验证码,大众点评的验证码不止一种,但是都是类似于滑块这一类的,涉及坐标计算之类的,我没有详细了解(以后有空再搞这个 )。更恶心的是对滑动速度还有要求,我在手动划的时候划的太快也不给通过,嘤嘤嘤。
二、网页分析
打开大众点评的评论页面之后,看着页面十分正常,于是一如既往开局就是一个F12,发现大众点评的程序员太实诚了:

这注释感觉有点瞧不起我们爬虫的(虽然你们确实牛× )。。。
定位到评论所在元素之后,开始懵逼 就看到评论内容是这样子的!
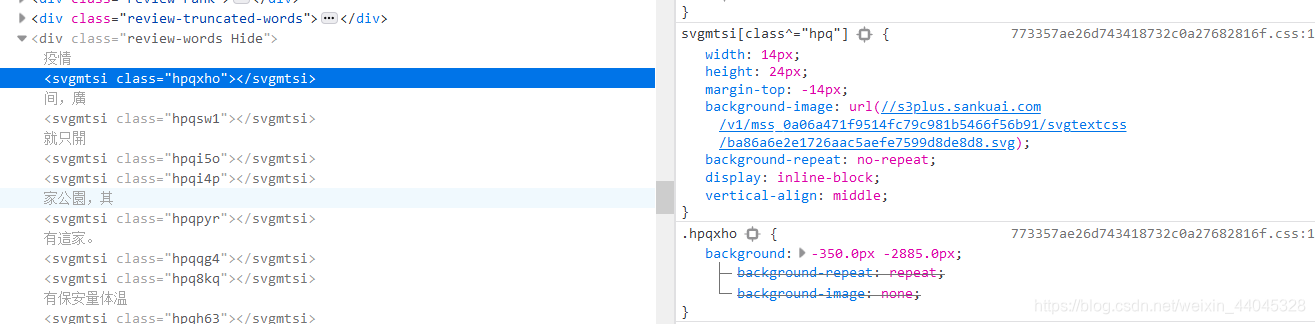
仔细观察就可以发现一个svgmtsi标签实际上就是对应着一个字,与这个标签唯一有关的也就只有一个class,于是查看这个标签的CSS,发现这个标签实际上就是一张图,图片来源于一个链接://s3plus.sankuai.com/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/ba86a6e2e1726aac5aefe7599d8de8d8.svg,当然就需要打开这个链接看一看呀!

是一整页的字,到这里,好像开始有头绪了,html页面缺少的字,都是来自这个svg页面,就差个什么东西将这俩东西联系起来了。
没错,关键就在svgmtsi标签的类,我们找到相应的CSS文件,结果在那里面有重大收获:
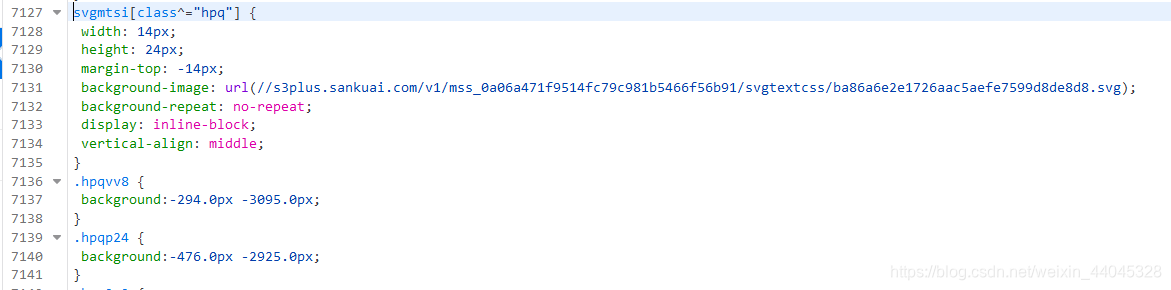
你看这URL它又细又长,是不是有点眼熟,这不就是满满一页字的那个链接嘛;而且还有超多的以hpq开头的class,里面对应一个坐标值,这么看来,一切都明朗了,大众点评评论的文字替换成图片的原理是这样子的:
1.把svg页面加载出来,这里可以把这个页面理解为一张图
2.当网页解析到svgmtsi标签的时候,根据类名(例如上面的hpqvv8)找到对应的属性和属性值,其中属性值实际上就是坐标,设为x和y(例如hpqvv8对应的坐标就是x=294和y=3095)
3.根据坐标值对svg页面进行移动即可显示相应的字
而我们要取得相应的字,第三步就会有所不一样,容我先用下面一张图来解释:

第一步:y的值和M0的值比较,找到对应的第几行,如图:当2948<y<2989时,则对应第73行。
第二步:找到对应的那一行。图凑合着看,就不截长图了。
第三步:x起作用了,x的值除以14(字号是14)就是对应的第几个字,例如图里的“饮”字,对应的x值就是42。
找到对应的字了,最后直接替换掉原本的标签就行了。
OK接下来上代码。
三、代码
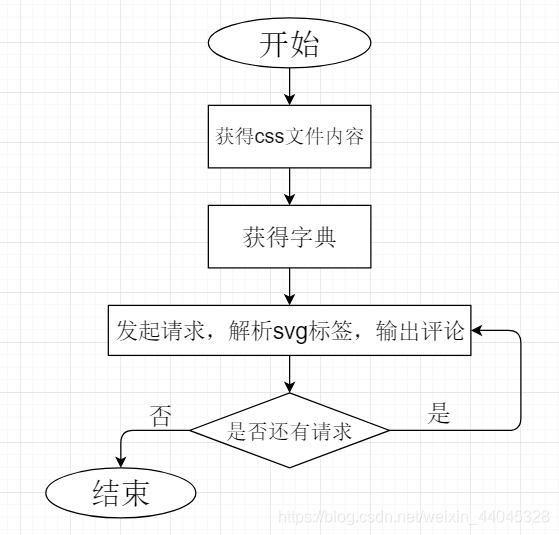
程序流程图:
关于获得CSS文件内容
def get_css_content(html, headers):
print('------begin to get css content------')
css_l = re.search(r'<link rel="stylesheet" type="text/css" href="(//s3plus.sankuai.com.*?.css)">', html)
css_link = 'http:' + css_l.group(1)
html_css = requests.get(css_link, headers).text
return html_css这里需要在html文件中找到CSS的链接,再发送请求获得CSS文件
PS.请求CSS文件其实可以不用自己做的headers,用Python默认的headers也是可以的
关于获得字典
def get_font_dic(css_content):
print('------begin to get font dictionary------')
# 获取svg链接和svg页面的html源码
svg_l = re.search(r'svgmtsi.*?(//s3plus.sankuai.com.*?svg)\);', css_content)
svg_link = 'http:' + svg_l.group(1)
svg_html = requests.get(svg_link).text
# 解析出字典
y_list = re.findall('d="M0 (.*?) H600"', svg_html) # y_list的元素为str
font_dic = {}
j = 0 # j为第j行
font_size = int(re.findall(r'font-size:(.*?)px;fill:#333;}', svg_html)[0])
for y in y_list:
font_l = re.findall(r'<textPath xlink:href="#' + str(j + 1) + '" textLength=".*?">(.*?)</textPath>', svg_html)
font_list = re.findall(r'.{1}', font_l[0])
for x in range(len(font_list)): # x为每一行第x个字
font_dic[str(x * font_size) + ',' + y] = font_list[x]
j += 1
return font_dic, y_list这里需要在CSS文件中解析出svg页面的链接,获得svg页面的内容并制作成字典。
因为CSS文件里实际上有不止一条svg链接,在获得svg页面链接这里,我看到有些博主是用类名前2或者3个字母(决定于大众点评的网页,有时候是2,有时候是3)来找,可是我发现只有正确那条链接的所对应的标签名才是svgmtsi,其他都是aa、bb的样子,因此我直接以标签名为查找的标准。
最后除了返回字典外,还多返回了y_list(实际上就是M0后面跟着的值),因为y_list在最后把标签替代成文字的时候还需要用到。
关于把svg标签替换成文字
def get_html_full_review(html, css_content, font_dic, y_list):
font_key_list = re.findall(r'<svgmtsi class="(.*?)"></svgmtsi>', html)
for font_key in font_key_list:
pos_key = re.findall(r'.' + font_key + '{background:-(.*?).0px -(.*?).0px;}', css_content)
pos_x = pos_key[0][0]
pos_y_original = pos_key[0][1]
for y in y_list:
if int(pos_y_original) < int(y):
pos_y = y
break
html = html.replace('<svgmtsi class="' + font_key + '"></svgmtsi>', font_dic[pos_x + ',' + pos_y])
return html计算出x和y的值,找到相应的字,替换掉svg标签(没错就是在强行吹水 )
关于输出保存到txt文件
def reviews_output(html_full_review):
print('------开始提取评论并写入文件------')
html = etree.HTML(html_full_review)
reviews_items = html.xpath("//div[@class='reviews-items']/ul/li")
for i in reviews_items:
].xpath('string(.)').strip()
r = i.xpath("./div/div[@class='review-words Hide']/text()")
for temp in r:
with open('reviews.txt', 'a+', encoding='UTF-8') as f:
f.write(temp)
f.close()
print('------写入完成,延迟10-25秒------')
time.sleep(10 + 15 * random.random())
这里推荐lxml库,对html文件的解析和解析DOM文件类似,好评,比re库来得专业
四、说明
- 详细代码见github
- 本程序主要解决大众点评里面CSS加密问题,对封IP问题采取了程序延迟10-25秒的措施,且没有解决验证码问题,但是验证码的问题可以手动验证,并修改相关代码,也可以爬完全部页面。
- 本程序只爬取了大众点评上指定一家店铺的所有评论。
- 直接在网页上看好评论的页数并填进代码,没有自动化获取评论页数。
- 大众点评需要cookie才能登录,需要抓取cookie填进headers。
- 本程序只抓取了评论,未保存昵称,ID,图片等信息。
- 抓取的评论还未进行排版。
- (想起来了再补充)
五、后记
其实代码还有很多需要完善的地方,但是至少跑得动,核心部分没有大问题,也没有客户就不去理表面的东西了。
一开始决定接下这个任务的时候没想到还是有点难的,但是这东西就像恋爱一样一陷入就难以自拔。由于我本身也只是个小菜鸡,一边学习一边写,一边写一边debug,也花了三天的时间,最后跑成功了还是比较开心的。
不过其实我这个爬虫因为限定的范围比较小,所以也比较容易,例如我不用找shopid,这就给URL的构造省了一点麻烦。
Last but not least:本文仅供交流学习,严禁用于商业或着任何违法用途
