趁着这次春节呆在家的日子整理一下CSDN。感谢19年JDATA比赛中李哥,曹哥的带领,以及和俞兄,室友共同努力下取得不错的成绩(虽然本人后期因为有实习任务只是打打辅助了)。这也是笔者第一次体验面向业务的数据挖掘流程,学习如何结合业务去做数据分析和建模,感觉和在实验室跑UCI数据集区别挺大的。写这篇文章好好复盘一下比赛的经历,为感兴趣的小伙伴提供一些参考,也是对自己的一个总结。文章主要包括赛题解读,数据探索(为了保证能让读者更加清楚了解数据特点,数据探索部分有引用了其他队伍的比较具有参考价值的数据图并给出了引用链接),数据集划分,特征构建,解题方案,模型设计和赛后总结
注:赛题方要求不能公开代码,关于代码部分其实参考现有的几个top10的开源方案已经足够,这个比赛的得分点是在数据集构建方式和一些强特征的挖掘,然后模型CV集成会影响到模型稳定性和泛化性能,这些点是更加核心的部分,当然文末也会给出一些不错的工具,比如特征筛选,调参工具
比赛链接:https://jdata.jd.com/html/detail.html?id=8
赛题解读:
目标
提供 2018-02-01 到 2018-04-15 用户行为数据。需要对 2018-04-16 到 2018-04-22 用户对品类下店铺的购买进行预测。以 user_id, cate 和 user_id(用户id), cate(商品种类), shop_id(店铺id) F-SCORE 的加权组合作为最终评分。
评估指标

F11是对user_id, cate组合进行评估,F12是对user_id, cate,shop_id组合进行评估
业务场景及其几种解决方案
根据赛题描述和业务场景可推测,在目标区间购买的行为应该由两部分组成:一部分为复购行为,一部分为即时性购买。
解题思路有如下几种:
1. 直接对 user_id, cate, shop_id, sku_id 进行建模得到 user_id, cate, shop_id 组合。
2. 直接对 user_id, cate, shop_id 建模。
3. 对 user_id, cate 进行建模,也对 user_id,cate,shop_id 进行建模,组合两个结果得到最后的结果。
4. 先对 user_id, cate 组合建模进行召回再对 user_id, cate, shop_id 建模。
在后续过程中会介绍模型选择的思路并给出我们选择方案4的理由
数据探索
用户行为序列分析(1浏览,2下单,3关注,4加购,5评论)

- 春节时段用户行为数据是有异常的(比如浏览,下单数减少,推测是用户春节聚会活动使用app时间减少,在春节前年货促销活动时已经完成了大部分购买等原因导致),出于分布一致性考虑,在后面建模中会避免使用到这段数据
- 3月27日和3月28日两天浏览数据异常低而购买量增加(推测浏览数据没有正常采集和有一波小促销活动),这一点在构建特征时需要特别考虑
- 用户行为中的type=5的情况(加入购物车)仅在4.08之后出现,这个是一个难点,影响到后面特征和数据集的构建
有交互行为用户占全部购买比(该图引用自 https://github.com/DuncanZhou/jdata2019)
蓝色表示每天的产生下单的购买数。B040?表示那天有行为的用户的每天的下单样本数,可以发现的是存在大量的用户是缺少历史行为的。召回率存在上限。注:就我们看来,在本次比赛中缺少历史交互的购买行为几乎是无法预测到的(如果有更多场景下的数据其实也可以考虑尝试协同过滤等基于相似度推荐的做法),我们的目的是尽可能地捕捉到到目标区间前发生交互行为的用户的购买可能性,而这个用户候选集的区间选择要结合购买趋势来分析,在A榜前期我们尝试了购买区间前1,3,5,7天等时间段的候选区间,将1天变为3天线上排名上升不少,但是继续增多反而下降,这其实就是关于precision和recall指标的一个权衡,增加候选集recall会升高但是precision会下降。当然区间覆盖度也会影响到模型的泛化性能,有候选时间区间比较小的队伍A榜在前10,B榜翻车了,所以一定要注意过拟合问题
物品复购率分析
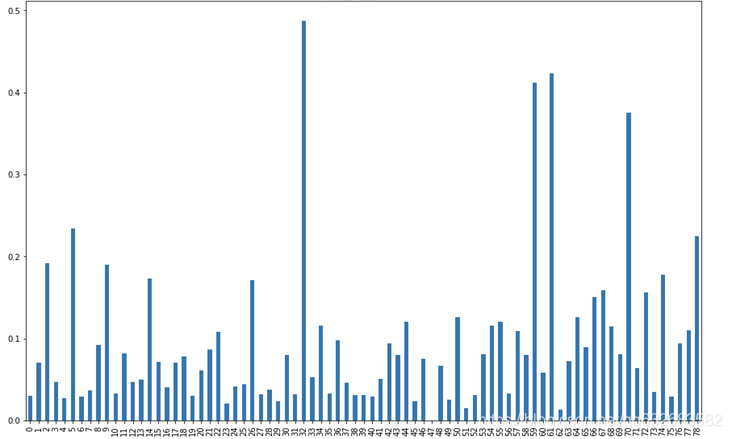
不同的类别在复购率上具有明显的差异,这验证了我们在上面对于业务场景的推测,即存在着即时购买(复购率低)和日用购买(复购率高)的行为。
用户购买累计分布图(同日购买同一商品超过2次按刷单用户过滤后统计得到)

大部分用户购买次数在4次以内,基本符合普通消费习惯。我们还发现一些特点,例如对于一个月内每天购买不多,但是总购买次数很多的用户可能是剁手党或者炒信用户,这种特征在建模的时候可以考虑进来。
用户平均商品复购的时间

用户平均复购时间为14天,这一点为候选区间的选择提供了一定的参考,候选区间不能设置太小,不然很多用户会覆盖不到
在目标区间购买样本在目标区间前的交互情况

- 在目标区间点购买由两部分组成一部分为复购,一部分为即时性购买并且即时性购买远多于复购行为。
- 复购和及时性购买增长不一致。从re_shop该曲线在目标区间10多天时已经达到0.6可得知及时性购买以近期的交互为主。
- user_id, cate 和 user_id, cate, shop_id 的增长情况非常一致,统计发现许多用户在目标类目选择了前面有交互的店铺进行购买,但是仍然存在换店铺购买的情况。
目标区间未交互的店铺购买分析


可以看到仍然有相当的品类,用户在购买前是没有过店铺交互行为,通过这个现象加上上面客户换店铺购买的可能性,我们在F12指标上提出了top店铺召回策略,正样本数量得到明显增加,并且该策略被证实是有效的。
异常数据分析

用户短时间内对一个产品重复下单,在type=2的数据中这种出现还比较多。我们对于这种情况复购率进行了统计,复购率在1.5%。考虑到这种情况的影响,一方面会影响到后续购买时间间隔和复购率的计算,另外如果时针对sku建模,那么这种复购很低的sku会使模型偏向于即时购买,接下来我们统计了cate和shop的复购率,在10%左右,根据这个情况,我们决定取消针对sku_id进行建模,把重点放在cate和shop上面,去掉sku_id后,cate直接变成了强特,模型线上性能有所提升。
数据集划分

关于时序数据,一定要注意好数据穿越数据泄露的问题,比如在比赛前期我们有对3,4月份的数据采用sklearn进行交叉验证,这使得训练集和验证集会同时包含3,4月份数据,线下效果不错,线上效果下降,这个原因可能就是4月份的数据穿越到了训练集导致过拟合问题,更加科学的做法是要训练集和验证集“分离”,比如训练用3月,验证用4月就不会出现上述问题。
特征构建


这里要说明的是,前期通过实验提取出来比较强的特征有用户评论,商品品类,涨粉速度这些,后期没有多余时间做特征筛选和交叉,应该也有比较大的提升空间。
解题方案

使用未交互的店铺进行召回这一策略受到评委老师的好评,因为相当于对目标区间未交互过的user,shop对提出了购买的推测,而且根据日常经验,会存在着人们浏览了一些店铺,然后过两天选另外的优质店铺购买的情况(对应于赛题场景就是用户在目标区间前没有互动过,但是在目标区间内购买了)
模型设计


模型融合

模型的融合就是图中的,采用了stakcing的方案,不过最后的权重没有足够的时间去优化,应该还有提升空间。
比赛总结
1.一定要构建合理的数据划分方式(考虑好分布差异,数据穿越,特征泄露等问题),模型稳定性很重要(CV调优,集成基本是必备),能做到线上线下的得分趋势一致(比赛中做的比较好的队伍甚至可以在提交前预测线上得分大概在多少)是一个很大的优势。
2.EDA很重要,不要凭主观臆测,比如比赛时有想过利用目标区间前更多的天数(不包括春节)来扩充训练集,但是效果不太好,经过分析后发现,和目标区间越接近的数据分布和目标区间越一致,所以并不是数据越多泛化性能越好,一定要保证分布的一致性。
3.分析好优化目标,对于预测变量组合(user,cate,shop),可以考虑拆分的做法(即先对user,cate召回,再预测user,cate,shop)有以下优点:a.从指标层面来说便于指标的优化,在实际比赛中,经常出现F11和F12此升彼降的情况,这其实可以从precision,recall的角度来解释,我们选择将F11优化到最高然后再对F12进行优化,这种做法可能不是最优的,因为这种做法有可能会限制F12的上限,但是在有限的时间和技术限制下,这是一种比稳妥的做法。 b.从训练层面,这种拆解的形式也有利于实验的优化,比如user,cate的召回过程可以大大降低样本不平衡比率,有利于模型学习)
4.善用指标曲线评估样本,例如利用precision,recall曲线来选择比较有把握的样本, 在尝试建立短期购车模型时,我们只选取方框中的结果加入到现有预测,不过受时间限制,没有调出很好的效果

5.小tricks
- 对lgb几个重要参数做一下扰动,训练多个模型然后取平均(比如学习率和迭代次数建立一个函数使得学习率大了迭代步数减少,然后扰动学习率)
- 因为比赛提交的结果是预测一周购买情况,我们统计了现有数据集用户的周平均购买数量,并且用来作为TOP-N对测试集结果进行过滤,在A榜取得了很好的效果,但是这种策略仅仅适合冲一下分,模型泛化性能得不到保证。
6.关于不同的场景需要制定不同的策略
比如在商品购买的场景,商品和类别很多,浏览记录很多,正负样本比例差距太大,所以需要采用召回的策略。而在别的场景,比如游戏道具购买的场景,采用的策略可能会有所不同,需要具体问题具体分析。
7.比赛中有一些想法但是没有时间做,在复盘时看到别的队友有这么做的而且有一定效果的,例如单独利用购物车信息建立模型(举个例子,我们现在手上只有8天的购物车记录,那么可以利用这8天数据建立一个有加购行为但是在当天没有购买的用户是否会在接下来x天内购买sku_id的短期模型,也可以按照赛季1的思路建立回归模型预测加购后的购买时间和现有结果融合),此外也有利用LSTM对时序行为提取特征的思路觉得很有想法(见https://github.com/DuncanZhou/jdata2019),关于模型融合的权值也有优化的空间
8.关注比赛群的信息和官方回复会有不少收获,比如老师在群里面会给出一些tips,例如对cate分开建模来防止类别干扰(比如有的cate是高奢,有的是日用,这样会使模型学不到正确的参数)
最后是工具推荐:
特征筛选:https://github.com/duxuhao/Feature-Selection
调参参考:https://blog.csdn.net/gdh756462786/article/details/79268685
