目录
引言
众所周知,深度学习自 AlexNet 时代到来之后,在 GPU 算力及大规模数据的增长背景下,提出了一个又一个新颖的网络模型。这些模型的背后都有一个共同的特点,那便是——SOTA,以至于在 CV 圈盛行了这样一句名言"Idea is cheap, show me the SOTA!"。所以说这年头,你要发个Paper如果不是SOTA,你都不好意思去投稿了,真是哭笑不得。作为一个曾经有幸投中过几篇顶会的种子没落选手,深知 SOTA 这个词汇对于 Paper 最终能不能被接收是至关重要的,至少对大部分平凡如我的普通人来说是这样的。如若不然,xxx reviewer 大概率会亲切的问候你一句:“你为什么没有和 xxx 方法对比,毕竟它是 xxx 领域的 SOTA 模型!”,仿佛就在昭告世人说“我看过的 SOTA 模型比你吃过的盐还多。”

然而,现实情况下,SOTA 模型在实际应用中真的是 state of the art 吗?这个问题对于投身于工业界的同学应该都深有体会,大部分所谓的 SOTA 模型在实际应用的效果说白了简直就是 Bullshit,无效不说,很多还给你整成负优化,懂的都懂。当然,对于学术界而言,大多数人仅需要针对某个特定的公开数据集,去设计相应的网络结构和方法,最后再结合一堆 tricks 和细致的调参去过拟合数据集便完事了。
回到今天这个话题,我们知道,深度学习模型通常是基于封闭世界在训练和测试数据是从同一分布中独立同分布(i.i.d)抽取的隐含假设下开发和测试的。忽视分布外 (OOD) 的图像可能会导致在看不见或不利的观看条件下性能不佳,这在现实场景中尤其常见。也就是说,当大家辛辛苦苦优(调)化(参)出来的模型如果应用现实世界的任务中去使用的话,大概率会导致模型性能急剧下降,毕竟这个假设已经不成立了,直接 GG。
以安防领域为例,给定一个城市,通常会先按照某一个片区来进行布点。这时候我们便会集中收集一个片区内机枪的所有数据然后去更新优化并提测一版模型,一般来说这时候上线之后那效果就真的很哇塞了,领导看了都得点赞。这时候你的心情大概率是这样子滴:
但是!人生总是事与愿违,就好比阿甘告诉我们:"Life is like a box of chocolates, you never know what you’re going to get."的道理一样,当现场的同事遵照领导的指示布局完新的点位之后,同样的模型便会碰到一系列各种莫名其妙、匪夷所思的问题:
-
Wocao!这 TM 都能给老子识别错了?
-
NMD,这怎么就检测不出来?
这时候,屏幕前狼狈的你,大概便是这样子:

而你的老板听完你的解释之后可能是这样子:

最终,你终于活成了自己最讨厌的模样:

这个惨痛经历告诉我们,解决 OOD 问题是何等重要的一件大事啊!
Out of Distribution
Out of Distribution, OOD 已经成为开放世界中安全可靠部署机器学习模型的一个核心挑战。其实,不仅在安防领域,在工业检测、自动驾驶等许多领域同样存在这样的问题,即遇到一个新场景的数据集我们的模型是否能 hold 得住。一种自然而然的简单解决方案当然是收集新场景的数据重新加入到模型中进行训练,但这显然不是我们今天讨论的主题。今天主要为大家介绍的是 ECCV 2022 举办的一个竞赛,该竞赛旨在解决 OOD 图像上的典型计算机视觉任务(即多类分类、目标检测等),这些图像遵循与训练图像不同的分布。首先,我们先简单了解下 OOD 的场景有哪些典型案例:

可以看出,OOD 图像的六种情况分别是:
- Shape:即目标的形状和尺寸等发生较大的变化;
- 3D Pose:即目标的姿态和方位等发生较大的变化;
- Texture:即目标的整个纹理发生明显的变化;
- Context:即目标所处的上下文环境发生明显的变化,例如开在海底隧道的列车;
- Weather:即不同天气和气候对目标的影响,例如春夏秋冬或者雨雪尘暴霾等;
- Occlusion:即不同程度的遮挡本身也会在一定程度上改变目标的语义;
好了,下面将分别解读下本次大赛中图像分类和目标检测赛道的冠军方案。
Image Classification Track

Paper: https://arxiv.org/pdf/2301.04795.pdf
Code: https://github.com/hikvision-research/OOD-CV (404 Not Found)
Track: https://codalab.lisn.upsaclay.fr/competitions/6781#learn_the_details
OOD-CV 挑战是一种解决分布外泛化的任务。在这个挑战中,团队的核心解决方案可以概括为:
Noisy Label Learning Is A Strong Test-Time Domain Adaptation Optimizer
整体的 Pipeline 为一个 two-stage 的结构,即:
- A pre-training stage for domain generalization
- A test-time training stage for domain adaptation
需要注意的是,此处仅在预训练阶段利用标记过的原始数据,而在测试时间训练阶段利用的是未标记的目标数据。具体地,在预训练阶段,作者提出了一种简单而有效的 Mask-Level Copy-Paste 数据增强策略,以增强分布外泛化能力,以抵抗形状、姿势、上下文、纹理、遮挡和气候变化 这六大挑战(描述见上)。而在测试时间训练阶段,其使用预训练模型为未标记的目标数据分配噪声标签(Noisy Label),并提出一种用于噪声标签学习的 Label-Periodically-Updated DivideMix 方法。 在集成 TTA 和 Ensemble 策略后,海康威视团队的解决方案目前在 OOD-CV 挑战赛的图像分类排行榜上名列第一。
动机
继现有工作,例如用于图像分类任务的 SSNLL 和用于目标检测任务的 SFOD 之后,本文提出了一种基于噪声标签的学习方法,这是一种强大的基于测试时域自适应优化器的想法。
首先,在测试时间域自适应之前,预训练一个强大的基线模型是一个必要的先决条件,该模型可以很好地泛化到分布外的数据。一种本能的方法是在源数据上堆叠多种强数据增强策略,以抵抗多种域转移。为此,除了传统的数据增强外,作者还开发了一种新颖的 Mask-Level CopyPaste 数据增强方法。具体来说,给定图像级标签,其采用最先进的弱监督语义分割方法 MCTformer 来分割 ImageNet-1K 和 ROBIN 训练数据集上的前景对象。通过这种方式,我们可以获取到三种不同的方案:
- 针对形状、姿势和纹理域偏移,我们可以应用仿射变换和颜色抖动来增强前景对象;
- 针对与上下文域偏移,我们将与任务相关的前景对象粘贴到与任务无关的图像上;
- 针对遮挡域偏移,我们可以粘贴以任务无关的前景对象到任务相关的图像上。
其次,模型预训练后,我们可以利用预训练模型为目标数据集打上新的伪标签,这些伪标签可视为噪声标签。 在这种情况下,通常可采用现有的噪声标签学习方法,如 DivideMix 自然地用于测试时域自适应。因此,在这个挑战中,作者提出了一种 LabelPeriodically-Updated DivideMix,它可以及时纠正噪声标签,同时避免过拟合噪声标签。
最后,通过在将测试时增强(TTA)和模型集成(Model Ensemble)策略与各种超参数集成后,本文的解决方案最终在 OOD-CV 挑战赛的图像分类排行榜上排名第一。
方法
Mask-Level Copy-Paste

Mask-Level Copy-Paste 的提出主要是用于解决 OOD 的几大挑战性问题。具体的做法是通过利用 ImageNet-1K 和 ROBIN 训练数据集上的图像级标签来训练弱监督语义分割(WSSS)模型——MCTformer,随后通过这个模型分割出图像中的前景对象。笔者之前也为大家介绍了一种基于 YOLOv5 框架实现的弱监督目标检测方法,感兴趣的读者也可以翻阅公众号『CVHub』历史文章查看,谁说一定要掩码级的前景你说是吧?
此处,根据类别标签是否与本次挑战中的任务相关,前景对象可以分为两种:
- 与任务相关的部分(task-related)
- 与任务无关的部分(task-unrelated)
同样,来自 ImageNet-1K 和 ROBIN 训练数据集的图像也可以分为与任务相关和与任务无关的部分。如此一来,我们便可以采用上面提到过的三种不同的方案来缓解不同的域转移问题。最后,通过与其他数据增强策略叠加,包括 AutoAug、CutMix 和基于规则的天气模拟方法,我们可以获得具有强大领域泛化能力的预训练模型。
笔者推荐:本方案的数据增强策略同样也可以应用到大家的日常开发任务上,例如经常有同学在问如何模拟不同天气下的数据等。
Label-Periodically-Updated DivideMix
这里作者将测试时域适应视为一个带噪声的标签学习问题,具体的做法就是利用我们上一步介绍的预训练模型为测试集上的数据打上 Label,这些标签信息可视为噪声标签(毕竟模型也不可能百分百准确的嘛)。
紧接着,在在获得噪声标签后,将 DivideMix 修改为 label-periodically-updated 的标签,可以及时纠正噪声标签,同时避免过拟合噪声标签。此外,与原始的 DivideMix 不同,这里在 MixMatch 组件中采用了流行的强弱增强策略,它使用弱增强进行伪标记,使用强增强进行模型优化。具体 Pilepie 可参照下图:

最后,具体的技术细节以及实验参数等设置,感兴趣的同学可以参考原文,此处不再详述,下同。
Object Detection Track

Paper: https://arxiv.org/pdf/2301.04796.pdf
Code: https://github.com/hikvision-research/OOD-CV (404 Not Found)
Track: https://codalab.lisn.upsaclay.fr/competitions/6784#learn_the_details
为了解决目标检测赛道中的 OOD 问题,本方案提出了一个简单而有效的 Generalize-then-Adapt (G&A) 框架,它包含两个部分:
- 两阶段的域泛化(
two-stage domain generalization) - 一阶段的域自适应(
one-stage domain adaptation)
其中,域泛化部分由使用源数据进行模型预热的监督模型预训练阶段和使用带有框级别标签的源数据和带有图像级的辅助数据(ImageNet-1K)的弱半监督模型预训练阶段实现性能提升的标签。而域自适应部分则实现为无源域自适应范式,仅使用预训练模型和未标记的目标数据以自监督训练方式进一步优化。
动机
为了提高模型在未知目标域中的鲁棒性,作者提出了一个简单而有效的 Generalize-then-Adapt (G&A) 框架来解决域转移下目标检测的模型退化问题。具体方案如下:
Supervised Model Pre-training
同分类赛道一样,此处针对域转移问题同样可以先训练处一个强大的 Baseline 模型,该基线可以利用具有各种强大数据增强策略的标记源数据来模拟潜在的分布外数据。
Weakly Semi-Supervised Model Pretraining
先前的工作表明,使用额外的辅助训练可以进一步增强分布外泛化能力。因此,我们可以将 ImageNet-1K 视为一种只有图像级标签的辅助训练数据。如此样一来,第一阶段的预训练目标检测器便可以在标记源数据(Robin training set with box-level label)和弱标记源数据(ImageNet-1K with image-level label)上进一步优化,这便是弱半监督目标检测。
Source-Free Domain Adaptation
这个是用于 Test-Time Training,通过仅利用源预训练目标检测器和未标记的目标数据来使模型适应目标域,而无需访问源数据。在该挑战中,它被简单地实现为基于 Mean-Teacher 的自训练机制。
最终,在集成 TTA 和 Model Ensemble 之后,整体的方案图如下所示:

方法
与联合训练源数据和目标数据的传统域自适应方法相比,本文所提出的 G&A 框架在现实场景中更加实用,它将联合训练范式解耦为下图所示:
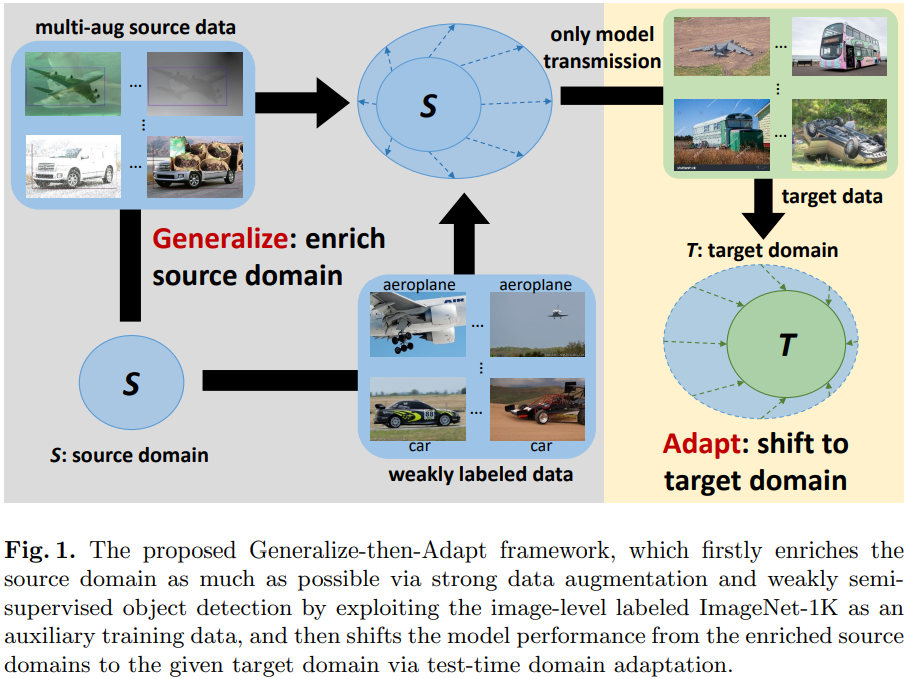
可以看出,其中域泛化阶段仅利用源数据,而测试时域适应阶段仅利用目标数据。为了避免以下两个问题:
- data expansive transmission
- data privacy leakage
G&A 框架只允许预训练模型传输而无需交换源数据。泛化步骤通常在服务器端进行,而适配步骤通常在客户端进行,以实现模型的自我进化(self-evolution)。
实际上,上述两个步骤可以看作是上、下游的操作。然而,OOD 社区中的现有工作通常侧重于域泛化步骤或测试时域自适应步骤,而没有将这两个步骤统一起来。因此,作者希望在本次挑战赛排行榜上表现出色的解决方案能够激发社区关注如何整合这两个步骤,以进一步抵制域转移下的模型退化问题,非常值得大家借鉴。
注:对 OOD 感兴趣的同学也可以多阅读下这方面的相关文献,例如 ECCV 2022 发表的这篇 OOD-CV.
总结
本文开头通过一个形象生动的案例为大家介绍了 OOD 任务的重要性,继而引申出今天的主角——关于计算机视觉中的域外分布泛化性问题。同时,也很荣幸的为大家简单讲解了本次 ECCV 2022 关于 OOD-CV 挑战赛中图像分类和目标检测赛道的冠军解决方案,希望对大家能有所启发。

如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!欢迎添加小编微信号: cv_huber,备注"CSDN",加入 CVHub 官方学术&技术交流群,一起探讨更多有趣的话题!