团队介绍
团队来自深圳市威富视界有限公司、中国科学院半导体研究所,队长为宁欣副研究员,成员分别为石园、刘江宽、支金林、王镇、荣倩倩,排名不分先后。

珠港澳人工智能算法赛题介绍
以检测和识别为核心的各项计算机视觉分析任务,例如行人检测,异常检测,属性识别等,在过去的几年中引起了人们的极大兴趣,并且应用到各种场景中。
本比赛主要聚集城市发展管理的核心领域,由珠海市香洲区人民政府为指导单位,珠海市香洲区科技创新促进中心主办, 腾讯云启创新中心(珠海)、深圳极视角科技有限公司承办,暨南大学智能科学与工程学院/人工智能产业学院提供学术支持,极市平台、腾讯云提供技术支持。并且提供了海量数据集和免费算力。
任务介绍
赛道1——短袖短裤识别
这项任务是基于现代化工厂的智能化需求,识别工厂安全隐患在工业安防中已成为典型需求之一。系统对通过短袖短裤识别算法的开发,赋能工厂更好的在监控区域及时警示安全隐患,提升工厂管理效率,减少工厂安全事故发生频率。
挑战赛的参与者首先需要检测出行人,给出可见身体范围框,然后根据行人着衣情况给出对应的类别信息,其类别为l_sleeve(长袖)、trousers(长裤)、s_sleeve(短袖)、shorts(短裤)、unsure(不确定)其中的一种或多种。数据由摄像头采集完成,训练数据集包含10537张,测试数据集有4517张。
赛道2——小摊贩占道识别
今年地摊经济对拉动经济发展、增加就业起到了积极促进作用,如何避免"一管就死,一放就乱"现象是当前城市管理非常重要的问题,因此如何有序管理小摊贩摆设成为智慧城管一大需求。本赛题系统通过小摊贩占道识别算法的开发,使得城市管理能更加智能高效,降低城市管理成本,减少城市小摊贩占道情况的发生。
挑战赛的参与者首先需要检测出占道的小摊贩,给出目标框和对应的类别信息,其类别为vendors。数据由摄像头采集完成,训练数据集包含7592张,测试数据集有3255张。
评价指标
本比赛最终得分采用准确度、算法性能绝对值的综合得分形式,具体形式如下:

说明:
(1) 算法精度的赛道标准值是指本赛道参赛者算法精度值的最高分;算法性能指的赛道标准值是 100 FPS, 如果所得性能值FPS≥赛道标准值FPS,则算法性能值得分=1;
(2) 本题规定predicted bounding box和ground truth bounding box的IoU(交叉比)作为结果目标匹配的依据,其中IoU值>Threshold且目标类别标签相匹配的目标视为正确结果,其它视为错误,赛道一Threshold为0.7,赛道二中Threshold为0.75;
(3)获奖评审标准:参赛者需要获得算法精度和算法性能值的成绩,且算法精度≥0.7,算法性能值FPS≥5,才能进入获奖评选;
威富视界&中国科学院半导体研究所两只团队荣获两项第一
赛道一:
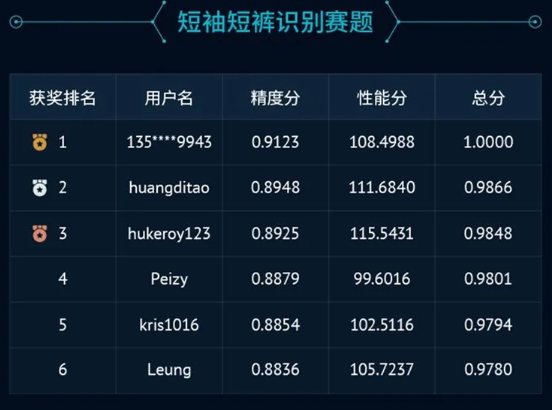
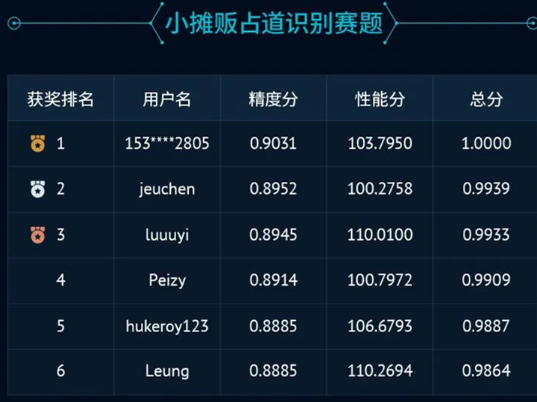
赛道二:
赛题特点
图像尺寸不一、近景和远景目标尺度差异大。
无论是赛道一的数据集还是赛道二的数据集,图片尺寸不一,相差较大。一方面,由于计算资源和算法性能的限制,大尺寸的图像不能作为网络的输入,而单纯将原图像缩放到小图会使得目标丢失大量信息,特别是赛道一中行人。另一方面,图像中近景和远景的目标尺度差异大,对于检测器来说,是个巨大的挑战。
目标在图像中分布密集,并且遮挡严重。
数据集均是利用摄像头从真实场景采集,部分数据的目标密集度较大。无论是赛道一中的行人还是赛道二中的小摊贩都出现了频繁出现遮挡现象,目标的漏检情况相对严重。
主要工作
主体框架选择:
目前,基于深度学习的目标检测技术包括anchor-based和anchor-free两大类。首先我们先是分析两者的优缺点:
anchor-based:
1)优点: 加入了先验知识,模型训练相对稳定;密集的anchor box可有效提高召回率,对于小目标检测来说提升非常明显。
2)缺点: 对于多类别目标检测,超参数scale和aspect ratio相对难设计;冗余box非常多,可能会造成正负样本失衡;在进行目标类别分类时,超参IOU阈值需根据任务情况调整。
anchor-free:
1)优点: 计算量减少;可灵活使用。
2)缺点: 存在正负样本严重不平衡;两个目标中心重叠的情况下,造成语义模糊性;检测结果相对不稳定。
我们又考虑到比赛任务情况:
1)短袖短裤识别是行人检测,小摊位占道识别是小摊位检测,都属于单类别检测,目标的scale和aspect ratio都在一定范围之内,属可控因素。
2)比赛数据中存在很多目标遮挡情况,这有可能会造成目标中心重新,如果采用anchor-free,会造成语义模糊性;
3)scale和aspect ratio可控,那么超参IOU调整相对简单;
4)大赛对模型部署没有特殊要求,因此,部署方案相对较多,模型性能有很大改进。
因此,在anchor-based和anchor-free两者中,我们偏向于选择基于anchor-based的算法。
众所周知,YOLO系列性能在目标检测算法一直引人瞩目,特别是最近的YOLOv5在速度上更是令人惊讶。从下图可以看出,YOLOv5在模型大小方面选择灵活,训练周期相对较短。另外,在保证速度的同时,模型精度也是可观。因此,我们选用YOLOv5作为baseline,然后依据两个赛道的任务情况在此基础上进行改进。


赛道一 短袖短裤识别
首先根据训练数据集进行分析,在10537张训练图像中,总共有12个组合类别、15个场景、18304个目标框。存在以下三种情况:
(1)样本不平衡,12个组合中,仅长袖-长裤组合占总数据的76.45%;
(2)场景样本不均衡,商场、工厂和街拍等五个场景中占比86.18%;
(3)多种状态行人,例如重叠、残缺、和占比小且遮挡。
另外,要权衡检测分类的精度和模型运行的速度,因此我们决定选用检测分类精度较好的目标检测框架,同时使用模型压缩和模型加速方法完成加速。其主体思路为:
(1) 目标检测框架:基于YOLOv5的one-stage检测框架;
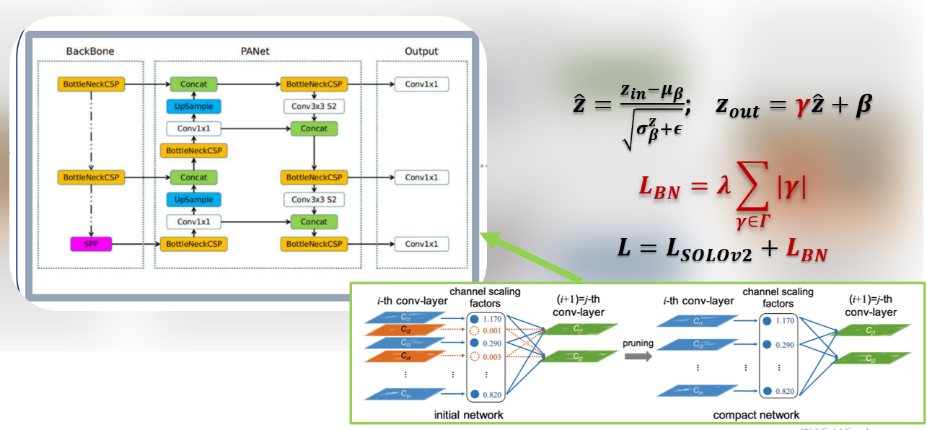
(2) 模型压缩:基于BN放缩因子修剪主干网络;
(3) 模型加速:TensorRT封装部署。
根据上述问题,采取以下策略:
(1) 预训练模型
本地从WiderPerson和COCO公开数据集中挑选并标注3000张行人数据,约1万个正样本(涵盖了商场、街拍、工厂等场景),以该数据集训练的模型作为预训练模型,一方面可加快平台上模型训练,另一方面可提高精度。
(2) 数增强策略
使用albumentations完成数据增强,例如裁剪拼接、翻转等。

(3) 网络框架设计
起初,我们将分类分为12类,即不确定-短裤、不确定-长裤、长袖-不确定、长袖-长裤、长袖-短裤、短袖-不确定、短袖-短裤、长裤、短裤、长袖、短袖。但是模型效果不佳,召回率较低。我们就思考,若将数据先分为两大类,即上衣和下衣,然后再分别将这两类分为四类,即上衣分为长袖、短袖、不确定、无;下衣分为长裤、短裤、不确定、无。从理论层面分析,上述方法可有效改善数据失衡问题,提高模型的召回率。
于是,我们就在网络的分类层做了实验,尝试了这两种不同策略的分类情况,通过实验证实8类别分类器确实优于12类别分类器,其原因在于8分类场景下训练样本的类别分布更优。

从表中可以看出12个类别中前3个类别占比太高,如果直接使用12类别分类器训练,模型会被引导至更利于检测长袖-长裤、短袖-长裤、短袖短裤等占比较多地类别上,对于剩余的占比较低的类别检出率会很低,最终导致模型测试的召回率很不理想。但是在8类别的分类器上,将前4个用于分类上衣,后4个值用于分类下衣,这样就会改善样本占比较少的类别的劣势。举例来说,长袖-长裤的样本占比较高,会引导模型更好地检出长裤,短袖-短裤样本同样会引导模型更好地检出短裤,短裤的特征参数和长袖的特征参数已经通过两个样本较多的类别训练完成,对于样本数量较少的长袖-短裤样本依旧会有较好的检出率。
上述两种方案的网络结构图如下:

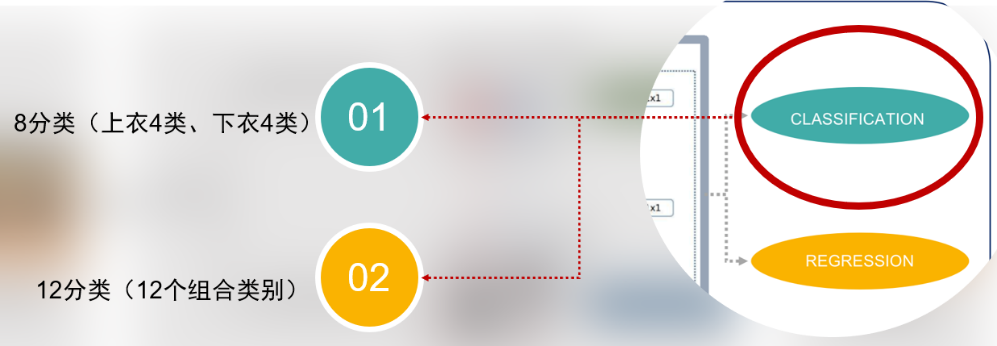
上述是两种分类方式,最终选用的是基于上衣和下衣的8分类方式,具体好处改善样本不均衡带来的分类偏差,从而提高召回率。
(4) 模型加速
由于大赛对模型部署没有特殊要求,按照我们以往的经验,我们优先了一下两种方式:1)剪枝加速策略,模型可提高1.3倍左右;
2) TensorRT加速策略,模型可提高约为1.3倍。两者可同时使用。
剪枝加速:
在许多现实应用中,深度神经网络的部署由于其高额的计算成本变得很困难。Slimming利用通道稀疏化的方法可以达到1)减少模型大小;2)减少运行时内存占用;3)在不影响精度的同时,降低计算操作数。
Slimming主要原理:
1)利用batch_norm中的缩放因子γ作为重要因子,即γ越小,所对应的通道不太重要,就可剪枝;
2)为约束γ的大小,在目标方程中增加一个关于γ的正则项,这样可以做到在训练中自动剪枝,而以往模型压缩不具备。
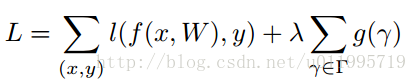
TensorRT加速:
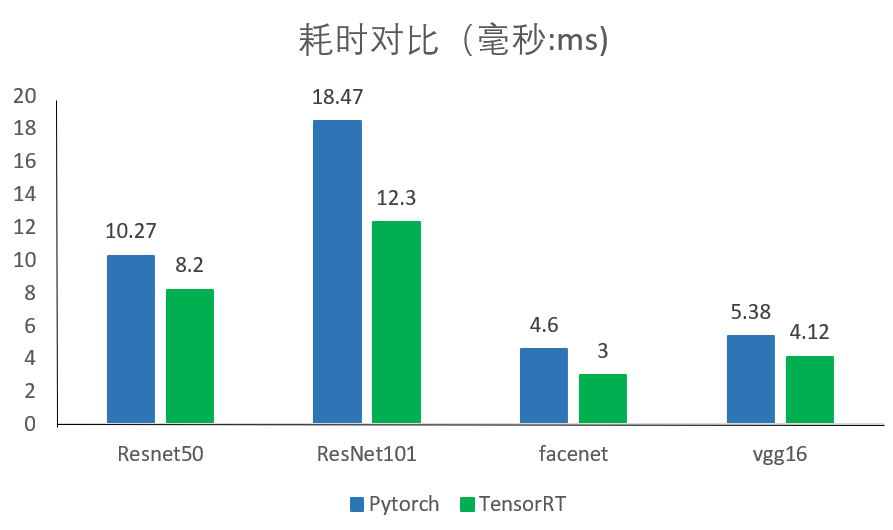
相对于python部署模型,c++封装部署模型速度更快。目标检测任务相对人脸识别这种任务特征精度要求相对较低,所以在确保精度相对不变的情况下,采用FP16比FP32速度可提升1.5倍左右。另外,TensorRT是一个高性能的深度学习推理优化器,可以为深度学习应用提供低延迟、高吞吐的部署推理。大赛对于模型部署没有特殊要求,因此我们选用了TensorRT进行部署模型。下图是python与TensorRT的模型部署的对比结果。
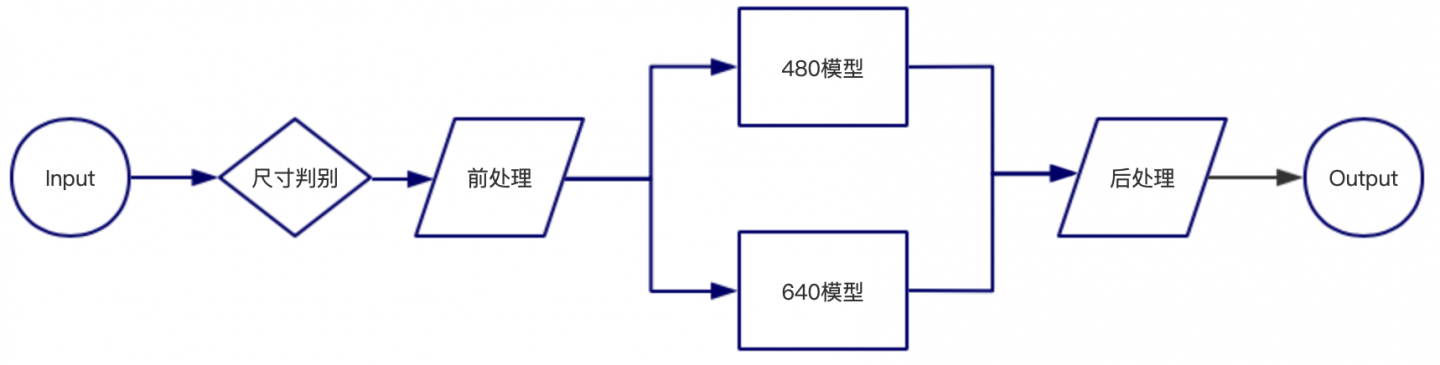
测试方案
通过实验发现街拍和商场数据的H:W=2:1的图像,使用输入大小为480的模型检测率更优,对于H:W=1:2的图像,使用输入大小为640的模型检测率更优。因此在测试时使用双模型检测,分析输入图像的尺寸择优选择模型完成预测。
实验结果

注:NMS阈值为0.5,正样本阈值为0.5
赛道二 小摊贩占道识别
和赛道一短袖短裤识别一样,小摊贩占道识别也属于目标检测任务。这里仅分析不同之处,相同技术参考赛道一。
起初考虑到算法性能因素,我们首先尝试YOLOv5s进行模型训练。经实验结果显示,模型预测存在大量的误检和漏检。这些漏检和无意义的检测结果大幅降低了模型的性能。我们将上述问题归纳为以下两个方面的原因:
1、YOLOv5s无论是网络宽度和网络深度都较小,学习能力相对较弱。小摊位占道和其他正常车辆十分相似,容易对分类器造成混淆,从而产生误检;
2、训练和测试时输入模型的图像尺度不合适。图像经过缩放后,目标的尺度也随之变小,导致远景中人的小摊贩等区域被大量遗漏;
根据上述问题,我们进行了一些尝试。
首先,从图像预处理方面,使用随机中心裁剪方式切图进行训练。随机窗口切图是一种常用的大图像处理方式,这样可以有效地保留图像的高分辨率信息,不同大小的目标,另一方面采用多尺度训练,这样使得网络获得的信息更加丰富。如果某个目标处于切图边界,根据目标框的与图片的大小比例来决定是否保留。另外,我们还采用了随机几何变换、颜色扰动、翻转、多尺度、mixup、GridMask、Mosaic等数据增广方式,都可提高模型的泛化能力和小目标检测率。
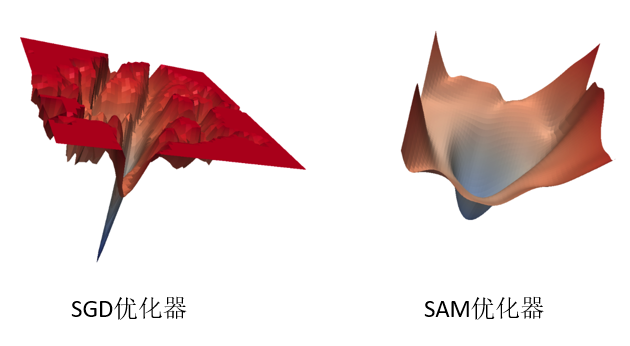
其次,从优化器层面来讲,我们尝试了优化器梯度归一化和SAM优化器。
优化器梯度归一化有三个好处:
(1)加速收敛;
(2)防止梯度爆炸;
(3)防止过拟合;

SAM优化器[4]可使损失值和损失锐度同时最小化,并可以改善各种基准数据集(例如CIFAR-f10、100g,ImageNet,微调任务)和模型的模型泛化能力,从而产生了多种最新性能。另外, SAM优化器具有固有的鲁棒性。
经实验对比,模型进行优化器梯度归一化和采用SAM优化器,约有0.003点的提升。
最后,在网络大小选择方面,由于我们可采用c++、tensorRT部署,所以我们可选择相对较大的网络,即YOLOv5m。这样可以模型的学习能力会增强。部署时不同方案的性能对比情况如下:

测试方案
通过测试发现,3255张测试集中1080*1920尺寸的图像与其他尺寸的图像比例约为7:3。于是我们TensorRT部署时,模型使用输入大小为384*640比640*640检测率更优。因为1080*1920直接resize为640*640,一方面会到值目标变形,另一面,目标变得更小。另外,使用TensrRT推理时,构造函数中采用warmup,提高算法性能指标。
注:由于时间关系该赛道仅使用了TensorRT,没有采用slimming剪枝加速。
实验结果:
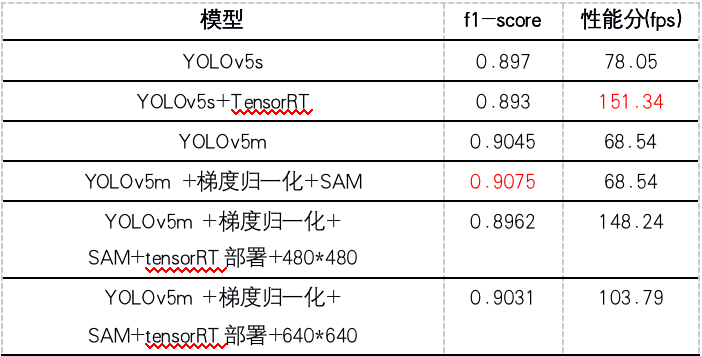
注:NMS阈值为0.5,正样本阈值为0.5
讨论与总结
本文针对2020首届珠港澳人工智能算法大赛两个赛道任务进行了总结与归纳。相关结论可以归纳为以下几点:
1、 数据分析对于训练模型至关重要。数据不平衡、图像尺寸和目标大小不一、目标密集和遮挡等问题,应选用对应的baseline和应对策略。例如,数据不平衡可尝试过采样、focal loss、数据增强等策略;图像尺寸和目标大小不一可采用多尺度、数据裁剪等方法。
2、 针对算法精度和性能两者取舍来说,可先实验网络大小和输入图片大小对模型结果的影响,不同任务和不同数据情况,两者相差较大。所以不能一味为了提高速度,单纯压缩网络大小;
3、 针对性能要求时,可采用TensorRT等方式部署模型,也可采用模型压缩等方式,这样可在保证速度的前提下,使用较大网络,提升模型精度。
参考文献
1. Zhuang L, Li J, Shen Z, et al. Learning Efficient Convolutional Networks through Network Slimming[ 2017]
2. https://github.com/ultralytics/yolov5.git
3. http://www.cbsr.ia.ac.cn/users/sfzhang/WiderPerson/
4. https://cocodataset.org/
5. Pierre F, Ariel K, Hossein M, Behnam N; Sharpness-Aware Minimization for Efficiently Improving Generalization[2020]