前言
偶然间在群里看到有人发了这个比赛,查了一下才知道这是京东举行的第三届JDATA算法大赛,可我从来没有听说过,有种被时代抛弃的感觉?。我自从2016年参加了阿里天池的几个比赛之后就没有关注过这方面,一是工作比较忙,二是自己变懒了,唉。听说腾讯每年也举办什么广告算法大赛,感兴趣的同学可以参加一下,此外还有kaggle等等。这次比赛也只是打了个酱油,毕竟工作了,没有上学时那么多时间,而且现在的同学都太厉害了?。虽然成绩不怎么样(89/1401),但我觉得这个流程还是值得记录和分享一下的。需注意的是,特征工程决定上限,而其余步骤只是逼近这个上限。最后,期待大佬们的分享~
赛题介绍
赛题:https://jdata.jd.com/html/detail.html?id=8
数据:https://download.csdn.net/download/dr_guo/11207507

赛题背景
京东零售集团坚持“以信赖为基础、以客户为中心的价值创造”这一经营理念,在不同的消费场景和连接终端上,在正确的时间、正确的地点为3亿多活跃用户提供最适合的产品和服务。目前,京东零售集团第三方平台签约商家超过21万个,实现了全品类覆盖,为维持商家生态繁荣、多样和有序,全面满足消费者一站式购物需求,需要对用户购买行为进行更精准地分析和预测。基于此,本赛题提供来自用户、商家、商品等多方面数据信息,包括商家和商品自身的内容信息、评论信息以及用户与之丰富的互动行为。参赛队伍需要通过数据挖掘技术和机器学习算法,构建用户购买商家中相关品类的预测模型,输出用户和店铺、品类的匹配结果,为精准营销提供高质量的目标群体。同时,希望参赛队伍通过本次比赛,挖掘数据背后潜在的意义,为电商生态平台的商家、用户提供多方共赢的智能解决方案。
01 /评分
参赛者提交的结果文件中包含对所有用户购买意向的预测结果。对每一个用户的预测结果包括两方面:
(1)该用户2018-04-16到2018-04-22是否对品类有购买,提交的结果文件中仅包含预测为下单的用户和品类(预测为未下单的用户和品类无须在结果中出现)。评测时将对提交结果中重复的“用户-品类”做排重处理,若预测正确,则评测算法中置label=1,不正确label=0。
(2)如果用户对品类有购买,还需要预测对该品类下哪个店铺有购买,若店铺预测正确,则评测算法中置pred=1,不正确pred=0。
对于参赛者提交的结果文件,按如下公式计算得分:score=0.4F11+0.6F12
此处的F1值定义为:

其中:Precise为准确率,Recall为召回率; F11 是label=1或0的F1值,F12 是pred=1或0的F1值。
02 /赛题数据
2.1 训练数据
提供2018-02-01到2018-04-15用户集合U中的用户,对商品集合S中部分商品的行为、评价、用户数据。
2.2 预测数据
提供 2018-04-16 到 2018-04-22 预测用户U对哪些品类和店铺有购买,用户对品类下的店铺只会购买一次。
2.3 数据表说明

1)行为数据(jdata_action)
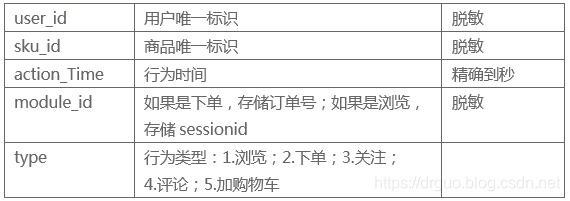
2)评论数据(jdata_comment)
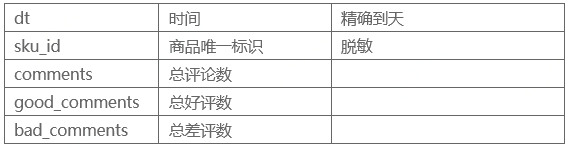
3)商品数据(jdata_product)
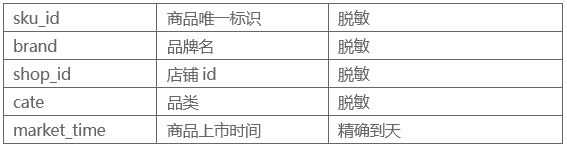
4)商家店铺数据(jdata_shop)
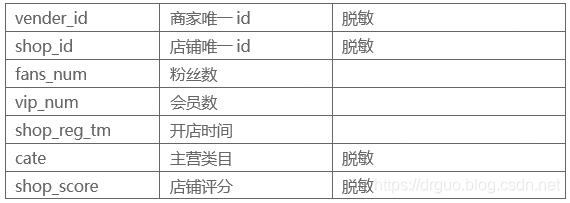
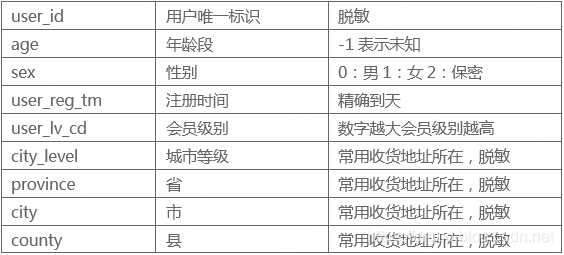
5)用户数据(jdata_user)
03 /任务描述及作品要求
3.1 任务描述
对于训练集中出现的每一个用户,参赛者的模型需要预测该用户在未来7天内对某个目标品类下某个店铺的购买意向。
3.2 作品要求
提交的CSV文件要求如下:
- UTF-8无BOM格式编码;
- 第一行为字段名,即:user_id,cate,shop_id(数据使用英文逗号分隔)
其中:user_id:用户表(jdata_user)中用户ID;cate:商品表(jdata_product)中商品sku_id对应的品类cate ;shop_id:商家表(jdata_shop)中店铺ID; - 结果不存在重复的记录行数,否则无效;
对于预测出没有购买意向的用户,在提交的CSV文件中不要包含该用户的信息。
提交结果示例如下图:

步骤汇总
这是我自己总结的流程,如有不对,欢迎交流指正。
1.查看分析数据
略
2.数据清洗
略
3.构造数据集(特征工程)
开始自己选的特征连0.03都上不去,后来看到Cookly 洪鹏飞开源的baseline,我基于他写的删了很多特征又加了一点特征,分数可能都没有他的baseline高,但没办法,笔记本跑不动。我测试了一下我的笔记本最高只能处理300维,说到这我要吐槽一下京东了,能不能跟阿里一样提供开发环境,我好多想法受限于硬件无法实现。
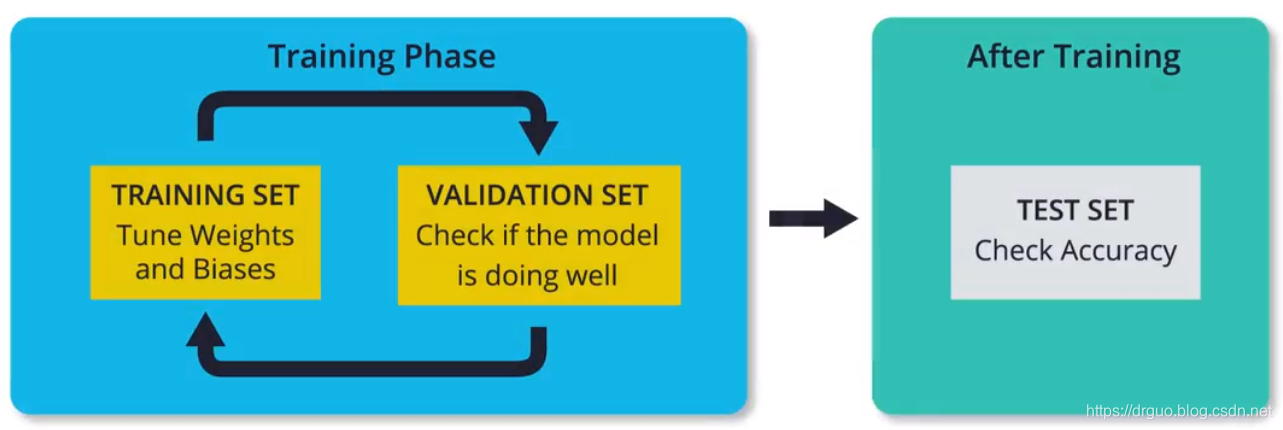
下面是代码,需要注意的是,我构造了三个数据集,分别是训练集、测试集和预测集。预测集这个大家可能没有听说过,因为往往都叫测试集,但我觉得这样叫有点乱,所以给它起了个名叫预测集,专门用来预测最终结果。测试集也有点不一样,测试集应与训练集完全不相关,用来评估模型的表现,而且用的次数不能太多。理论上讲,模型在测试集的表现与在预测集上的表现应该是差不多的。此外,训练集也可以划分为训练集和验证集,但是很多时候都没有真正的测试集,而是把训练集划分为训练集和测试集或是划分为训练集、验证集和测试集。是不是感觉有点乱,我说的也不一定对,但只需记住一点,我们只用测试集去评估模型的表现,并不会去调整优化模型,慢慢体会吧。
import pandas as pd
import os
import pickle
import datetime
import re
import numpy as np
jdata_action_file_dir = "../../jdata/jdata_action.csv"
jdata_comment_file_dir = "../../jdata/jdata_comment.csv"
jdata_product_file_dir = "../../jdata/jdata_product.csv"
jdata_shop_file_dir = "../../jdata/jdata_shop.csv"
jdata_user_file_dir = "../../jdata/jdata_user.csv"
# 减少内存使用
def reduce_mem_usage(df, verbose=True):
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
start_mem = df.memory_usage().sum() / 1024 ** 2
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024 ** 2
if verbose:
print('Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)'.format(end_mem, 100 * (start_mem - end_mem) / start_mem))
return df
# 行为数据
jdata_action = reduce_mem_usage(pd.read_csv(jdata_action_file_dir))
jdata_action.drop_duplicates(inplace=True)
del jdata_action['module_id']
# 视B榜数据而定,是否删除购物车记录(A榜数据只有8号后的购物车记录)
jdata_action = jdata_action[-jdata_action['type'].isin([5])]
# 评论数据
# jdata_comment = reduce_mem_usage(pd.read_csv(jdata_comment_file_dir))
# 商品数据
jdata_product = reduce_mem_usage(pd.read_csv(jdata_product_file_dir))
# 商家店铺数据
jdata_shop = reduce_mem_usage(pd.read_csv(jdata_shop_file_dir))
# 用户数据
jdata_user = reduce_mem_usage(pd.read_csv(jdata_user_file_dir))
Mem. usage decreased to 745.30 Mb (47.5% reduction)
Mem. usage decreased to 5.72 Mb (57.5% reduction)
Mem. usage decreased to 0.24 Mb (57.1% reduction)
Mem. usage decreased to 38.35 Mb (65.3% reduction)
def go_split(s, symbol='-: '):
# 拼接正则表达式
symbol = "[" + symbol + "]+"
# 一次性分割字符串
result = re.split(symbol, s)
# 去除空字符
return [x for x in result if x]
def get_hour(start, end):
d = datetime.datetime(*[int(float(i)) for i in go_split(start)]) - datetime.datetime(*[int(float(i)) for i in go_split(end)])
n = int(d.days*24 + d.seconds/60/60)
return n
def get_first_hour_gap(x):
return get_hour(end_day, min(x))
def get_last_hour_gap(x):
return get_hour(end_day, max(x))
def get_act_days(x):
return len(set([i[:10] for i in x]))
构造训练集-特征1天-用户品类店铺候选集7天-label7天(预测7天)
- ‘2018-03-29’-‘2018-04-04’
def get_train_set(end_day):
# 合并数据
jdata_data = jdata_action.merge(jdata_product, on=['sku_id'])
# 候选集 7天
# '2018-03-29'-'2018-04-04'
train_set = jdata_data[(jdata_data['action_time'] >= '2018-03-29 00:00:00')
& (jdata_data['action_time'] <= '2018-04-04 23:59:59')][
['user_id', 'cate', 'shop_id']].drop_duplicates()
# label 7天
# '2018-04-05'-'2018-04-11'
train_buy = jdata_data[(jdata_data['action_time'] >= '2018-04-05 00:00:00')
& (jdata_data['action_time'] <= '2018-04-11 23:59:59')
& (jdata_data['type'] == 2)][['user_id', 'cate', 'shop_id']].drop_duplicates()
train_buy['label'] = 1
train_set = train_set.merge(train_buy, on=['user_id', 'cate', 'shop_id'], how='left').fillna(0)
print('标签准备完毕!')
# 提取特征 2018-04-04 1天
start_day = '2018-04-04 00:00:00'
for gb_c in [['user_id'], # 用户
['cate'], # 品类
['shop_id'], # 店铺
['user_id', 'cate'], # 用户-品类
['user_id', 'shop_id'], # 用户-店铺
['cate', 'shop_id'], # 品类-店铺
['user_id', 'cate', 'shop_id']]: # 用户-品类-店铺
print(gb_c)
action_temp = jdata_data[(jdata_data['action_time'] >= start_day)
& (jdata_data['action_time'] <= end_day)]
# 特征函数
features_dict = {
'sku_id': [np.size, lambda x: len(set(x))],
'type': lambda x: len(set(x)),
'brand': lambda x: len(set(x)),
'shop_id': lambda x: len(set(x)),
'cate': lambda x: len(set(x)),
'action_time': [
get_first_hour_gap, # first_hour_gap
get_last_hour_gap, # last_hour_gap
get_act_days # act_days
]
}
features_columns = [c +'_' + '_'.join(gb_c)
for c in ['sku_cnt', 'sku_nq', 'type_nq', 'brand_nq', 'shop_nq', 'cate_nq', 'first_hour_gap', 'last_hour_gap', 'act_days']]
f_temp = action_temp.groupby(gb_c).agg(features_dict).reset_index()
# print(f_temp.columns)
f_temp.columns = gb_c + features_columns
# print(f_temp.columns)
train_set = train_set.merge(f_temp, on=gb_c, how='left')
for type_ in [1, 2, 3, 4, 5]: # 1:浏览 2:下单 3:关注 4:评论 5:加购物车
action_temp = jdata_data[(jdata_data['action_time'] >= start_day)
& (jdata_data['action_time'] <= end_day)
& (jdata_data['type'] == type_)]
features_dict = {
'sku_id': [np.size, lambda x: len(set(x))],
'type': lambda x: len(set(x)),
'brand': lambda x: len(set(x)),
'shop_id': lambda x: len(set(x)),
'cate': lambda x: len(set(x)),
'action_time': [
get_first_hour_gap, # first_hour_gap
get_last_hour_gap, # last_hour_gap
get_act_days # act_days
]
}
features_columns = [c +'_' + '_'.join(gb_c) + '_type_' + str(type_)
for c in ['sku_cnt', 'sku_nq', 'type_nq', 'brand_nq', 'shop_nq', 'cate_nq', 'first_hour_gap', 'last_hour_gap', 'act_days']]
f_temp = action_temp.groupby(gb_c).agg(features_dict).reset_index()
if len(f_temp) == 0:
continue
f_temp.columns = gb_c + features_columns
train_set = train_set.merge(f_temp, on=gb_c, how='left')
# 浏览、关注、评论购买比,加购物车特征很重要,视B榜数据而定
train_set['buybro_ratio_' + '_'.join(gb_c)] = train_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(2)]/train_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(1)]
train_set['buyfocus_ratio_' + '_'.join(gb_c)] = train_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(2)]/train_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(3)]
train_set['buycom_ratio_' + '_'.join(gb_c)] = train_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(2)]/train_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(4)]
# train_set['buycart_ratio_' + '_'.join(gb_c)] = train_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(2)]/train_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(5)]
# 用户特征
uid_info_col = ['user_id', 'age', 'sex', 'user_lv_cd', 'city_level', 'province', 'city', 'county']
train_set = train_set.merge(jdata_user[uid_info_col], on=['user_id'], how='left')
print('用户特征准备完毕!')
# 店铺特征
shop_info_col = ['shop_id', 'fans_num', 'vip_num', 'shop_score']
train_set = train_set.merge(jdata_shop[shop_info_col], on=['shop_id'], how='left')
print('店铺特征准备完毕!')
return train_set
end_day = '2018-04-04 23:59:59'
train_set = get_train_set(end_day)
train_set.to_hdf('datasets/train_set.h5', key='train_set', mode='w')
print(train_set.shape) # (1560852, 350)
# print(list(train_set.columns))
del train_set
标签准备完毕!
['user_id']
['cate']
['shop_id']
['user_id', 'cate']
['user_id', 'shop_id']
['cate', 'shop_id']
['user_id', 'cate', 'shop_id']
用户特征准备完毕!
店铺特征准备完毕!
(1560852, 350)
from collections import Counter
train_set = pd.read_hdf('datasets/train_set.h5', key='train_set')
y_train = train_set['label'].values
c = Counter(y_train)
del train_set, y_train
print(c)
Counter({0.0: 1546311, 1.0: 14541})
构造测试集-特征1天-用户品类店铺候选集7天-label7天(预测7天)
- ‘2018-04-02’-‘2018-04-08’
- 因为0327-28两天浏览数据严重缺失,训练集从0329开始到0404,与测试集重了三天,理论上训练集与测试集应完全不相关
def get_test_set(end_day):
# 合并数据
jdata_data = jdata_action.merge(jdata_product, on=['sku_id'])
# 候选集 7天
# '2018-04-02'-'2018-04-08'
test_set = jdata_data[(jdata_data['action_time'] >= '2018-04-02 00:00:00')
& (jdata_data['action_time'] <= '2018-04-08 23:59:59')][
['user_id', 'cate', 'shop_id']].drop_duplicates()
# label 7天
# '2018-04-09'-'2018-04-15'
test_buy = jdata_data[(jdata_data['action_time'] >= '2018-04-09 00:00:00')
& (jdata_data['action_time'] <= '2018-04-15 23:59:59')
& (jdata_data['type'] == 2)][['user_id', 'cate', 'shop_id']].drop_duplicates()
test_buy['label'] = 1
test_set = test_set.merge(test_buy, on=['user_id', 'cate', 'shop_id'], how='left').fillna(0)
print('标签准备完毕!')
# 提取特征 2018-04-08 1天
start_day = '2018-04-08 00:00:00'
for gb_c in [['user_id'], # 用户
['cate'], # 品类
['shop_id'], # 店铺
['user_id', 'cate'], # 用户-品类
['user_id', 'shop_id'], # 用户-店铺
['cate', 'shop_id'], # 品类-店铺
['user_id', 'cate', 'shop_id']]: # 用户-品类-店铺
print(gb_c)
action_temp = jdata_data[(jdata_data['action_time'] >= start_day)
& (jdata_data['action_time'] <= end_day)]
# 特征函数
features_dict = {
'sku_id': [np.size, lambda x: len(set(x))],
'type': lambda x: len(set(x)),
'brand': lambda x: len(set(x)),
'shop_id': lambda x: len(set(x)),
'cate': lambda x: len(set(x)),
'action_time': [
get_first_hour_gap, # first_hour_gap
get_last_hour_gap, # last_hour_gap
get_act_days # act_days
]
}
features_columns = [c +'_' + '_'.join(gb_c)
for c in ['sku_cnt', 'sku_nq', 'type_nq', 'brand_nq', 'shop_nq', 'cate_nq', 'first_hour_gap', 'last_hour_gap', 'act_days']]
f_temp = action_temp.groupby(gb_c).agg(features_dict).reset_index()
# print(f_temp.columns)
f_temp.columns = gb_c + features_columns
# print(f_temp.columns)
test_set = test_set.merge(f_temp, on=gb_c, how='left')
for type_ in [1, 2, 3, 4, 5]: # 1:浏览 2:下单 3:关注 4:评论 5:加购物车
action_temp = jdata_data[(jdata_data['action_time'] >= start_day)
& (jdata_data['action_time'] <= end_day)
& (jdata_data['type'] == type_)]
features_dict = {
'sku_id': [np.size, lambda x: len(set(x))],
'type': lambda x: len(set(x)),
'brand': lambda x: len(set(x)),
'shop_id': lambda x: len(set(x)),
'cate': lambda x: len(set(x)),
'action_time': [
get_first_hour_gap, # first_hour_gap
get_last_hour_gap, # last_hour_gap
get_act_days # act_days
]
}
features_columns = [c +'_' + '_'.join(gb_c) + '_type_' + str(type_)
for c in ['sku_cnt', 'sku_nq', 'type_nq', 'brand_nq', 'shop_nq', 'cate_nq', 'first_hour_gap', 'last_hour_gap', 'act_days']]
f_temp = action_temp.groupby(gb_c).agg(features_dict).reset_index()
if len(f_temp) == 0:
continue
f_temp.columns = gb_c + features_columns
test_set = test_set.merge(f_temp, on=gb_c, how='left')
# 浏览、关注、评论购买比,加购物车特征很重要,视B榜数据而定
test_set['buybro_ratio_' + '_'.join(gb_c)] = test_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(2)]/test_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(1)]
test_set['buyfocus_ratio_' + '_'.join(gb_c)] = test_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(2)]/test_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(3)]
test_set['buycom_ratio_' + '_'.join(gb_c)] = test_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(2)]/test_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(4)]
# test_set['buycart_ratio_' + '_'.join(gb_c)] = test_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(2)]/test_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(5)]
# 用户特征
uid_info_col = ['user_id', 'age', 'sex', 'user_lv_cd', 'city_level', 'province', 'city', 'county']
test_set = test_set.merge(jdata_user[uid_info_col], on=['user_id'], how='left')
print('用户特征准备完毕!')
# 店铺特征
shop_info_col = ['shop_id', 'fans_num', 'vip_num', 'shop_score']
test_set = test_set.merge(jdata_shop[shop_info_col], on=['shop_id'], how='left')
print('店铺特征准备完毕!')
return test_set
end_day = '2018-04-08 23:59:59'
test_set = get_test_set(end_day)
test_set.to_hdf('datasets/test_set.h5', key='test_set', mode='w')
print(test_set.shape) # (1560848, 350)
del test_set
标签准备完毕!
['user_id']
['cate']
['shop_id']
['user_id', 'cate']
['user_id', 'shop_id']
['cate', 'shop_id']
['user_id', 'cate', 'shop_id']
用户特征准备完毕!
店铺特征准备完毕!
(1560848, 350)
from collections import Counter
test_set = pd.read_hdf('datasets/test_set.h5', key='test_set')
y_train = test_set['label'].values
c = Counter(y_train)
del test_set, y_train
print(c)
Counter({0.0: 1545471, 1.0: 15377})
构造预测集-特征1天-用户品类店铺候选集7天
- ‘2018-04-09’-‘2018-04-15’
def get_pre_set(end_day):
# 合并数据
jdata_data = jdata_action.merge(jdata_product, on=['sku_id'])
# 预测集 7天
# '2018-04-09'-'2018-04-15'
pre_set = jdata_data[(jdata_data['action_time'] >= '2018-04-09 00:00:00')
& (jdata_data['action_time'] <= '2018-04-15 23:59:59')][
['user_id', 'cate', 'shop_id']].drop_duplicates()
# 提取特征 2018-04-15 1天
start_day = '2018-04-15 00:00:00'
for gb_c in [['user_id'], # 用户
['cate'], # 品类
['shop_id'], # 店铺
['user_id', 'cate'], # 用户-品类
['user_id', 'shop_id'], # 用户-店铺
['cate', 'shop_id'], # 品类-店铺
['user_id', 'cate', 'shop_id']]: # 用户-品类-店铺
print(gb_c)
action_temp = jdata_data[(jdata_data['action_time'] >= start_day)
& (jdata_data['action_time'] <= end_day)]
# 特征函数
features_dict = {
'sku_id': [np.size, lambda x: len(set(x))],
'type': lambda x: len(set(x)),
'brand': lambda x: len(set(x)),
'shop_id': lambda x: len(set(x)),
'cate': lambda x: len(set(x)),
'action_time': [
get_first_hour_gap, # first_hour_gap
get_last_hour_gap, # last_hour_gap
get_act_days # act_days
]
}
features_columns = [c +'_' + '_'.join(gb_c)
for c in ['sku_cnt', 'sku_nq', 'type_nq', 'brand_nq', 'shop_nq', 'cate_nq', 'first_hour_gap', 'last_hour_gap', 'act_days']]
f_temp = action_temp.groupby(gb_c).agg(features_dict).reset_index()
# print(f_temp.columns)
f_temp.columns = gb_c + features_columns
# print(f_temp.columns)
pre_set = pre_set.merge(f_temp, on=gb_c, how='left')
for type_ in [1, 2, 3, 4, 5]: # 1:浏览 2:下单 3:关注 4:评论 5:加购物车
action_temp = jdata_data[(jdata_data['action_time'] >= start_day)
& (jdata_data['action_time'] <= end_day)
& (jdata_data['type'] == type_)]
features_dict = {
'sku_id': [np.size, lambda x: len(set(x))],
'type': lambda x: len(set(x)),
'brand': lambda x: len(set(x)),
'shop_id': lambda x: len(set(x)),
'cate': lambda x: len(set(x)),
'action_time': [
get_first_hour_gap, # first_hour_gap
get_last_hour_gap, # last_hour_gap
get_act_days # act_days
]
}
features_columns = [c +'_' + '_'.join(gb_c) + '_type_' + str(type_)
for c in ['sku_cnt', 'sku_nq', 'type_nq', 'brand_nq', 'shop_nq', 'cate_nq', 'first_hour_gap', 'last_hour_gap', 'act_days']]
f_temp = action_temp.groupby(gb_c).agg(features_dict).reset_index()
if len(f_temp) == 0:
continue
f_temp.columns = gb_c + features_columns
pre_set = pre_set.merge(f_temp, on=gb_c, how='left')
# 浏览、关注、评论购买比,加购物车特征很重要,视B榜数据而定
pre_set['buybro_ratio_' + '_'.join(gb_c)] = pre_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(2)]/pre_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(1)]
pre_set['buyfocus_ratio_' + '_'.join(gb_c)] = pre_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(2)]/pre_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(3)]
pre_set['buycom_ratio_' + '_'.join(gb_c)] = pre_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(2)]/pre_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(4)]
# pre_set['buycart_ratio_' + '_'.join(gb_c)] = pre_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(2)]/pre_set['sku_cnt_' + '_'.join(gb_c) + '_type_' + str(5)]
# 用户特征
uid_info_col = ['user_id', 'age', 'sex', 'user_lv_cd', 'city_level', 'province', 'city', 'county']
pre_set = pre_set.merge(jdata_user[uid_info_col], on=['user_id'], how='left')
print('用户特征准备完毕!')
# 店铺特征
shop_info_col = ['shop_id', 'fans_num', 'vip_num', 'shop_score']
pre_set = pre_set.merge(jdata_shop[shop_info_col], on=['shop_id'], how='left')
print('店铺特征准备完毕!')
return pre_set
end_day = '2018-04-15 23:59:59'
pre_set = get_pre_set(end_day)
pre_set.to_hdf('datasets/pre_set.h5', key='pre_set', mode='w')
print(pre_set.shape)
print(list(pre_set.columns))
del pre_set
['user_id']
['cate']
['shop_id']
['user_id', 'cate']
['user_id', 'shop_id']
['cate', 'shop_id']
['user_id', 'cate', 'shop_id']
用户特征准备完毕!
店铺特征准备完毕!
(1569270, 349)
['user_id', 'cate', 'shop_id', 'sku_cnt_user_id', 'sku_nq_user_id', 'type_nq_user_id', 'brand_nq_user_id', 'shop_nq_user_id', 'cate_nq_user_id', 'first_hour_gap_user_id', 'last_hour_gap_user_id', 'act_days_user_id', 'sku_cnt_user_id_type_1', 'sku_nq_user_id_type_1', 'type_nq_user_id_type_1', 'brand_nq_user_id_type_1', 'shop_nq_user_id_type_1', 'cate_nq_user_id_type_1', 'first_hour_gap_user_id_type_1', 'last_hour_gap_user_id_type_1', 'act_days_user_id_type_1', 'sku_cnt_user_id_type_2', 'sku_nq_user_id_type_2', 'type_nq_user_id_type_2', 'brand_nq_user_id_type_2', 'shop_nq_user_id_type_2', 'cate_nq_user_id_type_2', 'first_hour_gap_user_id_type_2', 'last_hour_gap_user_id_type_2', 'act_days_user_id_type_2', 'sku_cnt_user_id_type_3', 'sku_nq_user_id_type_3', 'type_nq_user_id_type_3', 'brand_nq_user_id_type_3', 'shop_nq_user_id_type_3', 'cate_nq_user_id_type_3', 'first_hour_gap_user_id_type_3', 'last_hour_gap_user_id_type_3', 'act_days_user_id_type_3', 'sku_cnt_user_id_type_4', 'sku_nq_user_id_type_4', 'type_nq_user_id_type_4', 'brand_nq_user_id_type_4', 'shop_nq_user_id_type_4', 'cate_nq_user_id_type_4', 'first_hour_gap_user_id_type_4', 'last_hour_gap_user_id_type_4', 'act_days_user_id_type_4', 'buybro_ratio_user_id', 'buyfocus_ratio_user_id', 'buycom_ratio_user_id', 'sku_cnt_cate', 'sku_nq_cate', 'type_nq_cate', 'brand_nq_cate', 'shop_nq_cate', 'cate_nq_cate', 'first_hour_gap_cate', 'last_hour_gap_cate', 'act_days_cate', 'sku_cnt_cate_type_1', 'sku_nq_cate_type_1', 'type_nq_cate_type_1', 'brand_nq_cate_type_1', 'shop_nq_cate_type_1', 'cate_nq_cate_type_1', 'first_hour_gap_cate_type_1', 'last_hour_gap_cate_type_1', 'act_days_cate_type_1', 'sku_cnt_cate_type_2', 'sku_nq_cate_type_2', 'type_nq_cate_type_2', 'brand_nq_cate_type_2', 'shop_nq_cate_type_2', 'cate_nq_cate_type_2', 'first_hour_gap_cate_type_2', 'last_hour_gap_cate_type_2', 'act_days_cate_type_2', 'sku_cnt_cate_type_3', 'sku_nq_cate_type_3', 'type_nq_cate_type_3', 'brand_nq_cate_type_3', 'shop_nq_cate_type_3', 'cate_nq_cate_type_3', 'first_hour_gap_cate_type_3', 'last_hour_gap_cate_type_3', 'act_days_cate_type_3', 'sku_cnt_cate_type_4', 'sku_nq_cate_type_4', 'type_nq_cate_type_4', 'brand_nq_cate_type_4', 'shop_nq_cate_type_4', 'cate_nq_cate_type_4', 'first_hour_gap_cate_type_4', 'last_hour_gap_cate_type_4', 'act_days_cate_type_4', 'buybro_ratio_cate', 'buyfocus_ratio_cate', 'buycom_ratio_cate', 'sku_cnt_shop_id', 'sku_nq_shop_id', 'type_nq_shop_id', 'brand_nq_shop_id', 'shop_nq_shop_id', 'cate_nq_shop_id', 'first_hour_gap_shop_id', 'last_hour_gap_shop_id', 'act_days_shop_id', 'sku_cnt_shop_id_type_1', 'sku_nq_shop_id_type_1', 'type_nq_shop_id_type_1', 'brand_nq_shop_id_type_1', 'shop_nq_shop_id_type_1', 'cate_nq_shop_id_type_1', 'first_hour_gap_shop_id_type_1', 'last_hour_gap_shop_id_type_1', 'act_days_shop_id_type_1', 'sku_cnt_shop_id_type_2', 'sku_nq_shop_id_type_2', 'type_nq_shop_id_type_2', 'brand_nq_shop_id_type_2', 'shop_nq_shop_id_type_2', 'cate_nq_shop_id_type_2', 'first_hour_gap_shop_id_type_2', 'last_hour_gap_shop_id_type_2', 'act_days_shop_id_type_2', 'sku_cnt_shop_id_type_3', 'sku_nq_shop_id_type_3', 'type_nq_shop_id_type_3', 'brand_nq_shop_id_type_3', 'shop_nq_shop_id_type_3', 'cate_nq_shop_id_type_3', 'first_hour_gap_shop_id_type_3', 'last_hour_gap_shop_id_type_3', 'act_days_shop_id_type_3', 'sku_cnt_shop_id_type_4', 'sku_nq_shop_id_type_4', 'type_nq_shop_id_type_4', 'brand_nq_shop_id_type_4', 'shop_nq_shop_id_type_4', 'cate_nq_shop_id_type_4', 'first_hour_gap_shop_id_type_4', 'last_hour_gap_shop_id_type_4', 'act_days_shop_id_type_4', 'buybro_ratio_shop_id', 'buyfocus_ratio_shop_id', 'buycom_ratio_shop_id', 'sku_cnt_user_id_cate', 'sku_nq_user_id_cate', 'type_nq_user_id_cate', 'brand_nq_user_id_cate', 'shop_nq_user_id_cate', 'cate_nq_user_id_cate', 'first_hour_gap_user_id_cate', 'last_hour_gap_user_id_cate', 'act_days_user_id_cate', 'sku_cnt_user_id_cate_type_1', 'sku_nq_user_id_cate_type_1', 'type_nq_user_id_cate_type_1', 'brand_nq_user_id_cate_type_1', 'shop_nq_user_id_cate_type_1', 'cate_nq_user_id_cate_type_1', 'first_hour_gap_user_id_cate_type_1', 'last_hour_gap_user_id_cate_type_1', 'act_days_user_id_cate_type_1', 'sku_cnt_user_id_cate_type_2', 'sku_nq_user_id_cate_type_2', 'type_nq_user_id_cate_type_2', 'brand_nq_user_id_cate_type_2', 'shop_nq_user_id_cate_type_2', 'cate_nq_user_id_cate_type_2', 'first_hour_gap_user_id_cate_type_2', 'last_hour_gap_user_id_cate_type_2', 'act_days_user_id_cate_type_2', 'sku_cnt_user_id_cate_type_3', 'sku_nq_user_id_cate_type_3', 'type_nq_user_id_cate_type_3', 'brand_nq_user_id_cate_type_3', 'shop_nq_user_id_cate_type_3', 'cate_nq_user_id_cate_type_3', 'first_hour_gap_user_id_cate_type_3', 'last_hour_gap_user_id_cate_type_3', 'act_days_user_id_cate_type_3', 'sku_cnt_user_id_cate_type_4', 'sku_nq_user_id_cate_type_4', 'type_nq_user_id_cate_type_4', 'brand_nq_user_id_cate_type_4', 'shop_nq_user_id_cate_type_4', 'cate_nq_user_id_cate_type_4', 'first_hour_gap_user_id_cate_type_4', 'last_hour_gap_user_id_cate_type_4', 'act_days_user_id_cate_type_4', 'buybro_ratio_user_id_cate', 'buyfocus_ratio_user_id_cate', 'buycom_ratio_user_id_cate', 'sku_cnt_user_id_shop_id', 'sku_nq_user_id_shop_id', 'type_nq_user_id_shop_id', 'brand_nq_user_id_shop_id', 'shop_nq_user_id_shop_id', 'cate_nq_user_id_shop_id', 'first_hour_gap_user_id_shop_id', 'last_hour_gap_user_id_shop_id', 'act_days_user_id_shop_id', 'sku_cnt_user_id_shop_id_type_1', 'sku_nq_user_id_shop_id_type_1', 'type_nq_user_id_shop_id_type_1', 'brand_nq_user_id_shop_id_type_1', 'shop_nq_user_id_shop_id_type_1', 'cate_nq_user_id_shop_id_type_1', 'first_hour_gap_user_id_shop_id_type_1', 'last_hour_gap_user_id_shop_id_type_1', 'act_days_user_id_shop_id_type_1', 'sku_cnt_user_id_shop_id_type_2', 'sku_nq_user_id_shop_id_type_2', 'type_nq_user_id_shop_id_type_2', 'brand_nq_user_id_shop_id_type_2', 'shop_nq_user_id_shop_id_type_2', 'cate_nq_user_id_shop_id_type_2', 'first_hour_gap_user_id_shop_id_type_2', 'last_hour_gap_user_id_shop_id_type_2', 'act_days_user_id_shop_id_type_2', 'sku_cnt_user_id_shop_id_type_3', 'sku_nq_user_id_shop_id_type_3', 'type_nq_user_id_shop_id_type_3', 'brand_nq_user_id_shop_id_type_3', 'shop_nq_user_id_shop_id_type_3', 'cate_nq_user_id_shop_id_type_3', 'first_hour_gap_user_id_shop_id_type_3', 'last_hour_gap_user_id_shop_id_type_3', 'act_days_user_id_shop_id_type_3', 'sku_cnt_user_id_shop_id_type_4', 'sku_nq_user_id_shop_id_type_4', 'type_nq_user_id_shop_id_type_4', 'brand_nq_user_id_shop_id_type_4', 'shop_nq_user_id_shop_id_type_4', 'cate_nq_user_id_shop_id_type_4', 'first_hour_gap_user_id_shop_id_type_4', 'last_hour_gap_user_id_shop_id_type_4', 'act_days_user_id_shop_id_type_4', 'buybro_ratio_user_id_shop_id', 'buyfocus_ratio_user_id_shop_id', 'buycom_ratio_user_id_shop_id', 'sku_cnt_cate_shop_id', 'sku_nq_cate_shop_id', 'type_nq_cate_shop_id', 'brand_nq_cate_shop_id', 'shop_nq_cate_shop_id', 'cate_nq_cate_shop_id', 'first_hour_gap_cate_shop_id', 'last_hour_gap_cate_shop_id', 'act_days_cate_shop_id', 'sku_cnt_cate_shop_id_type_1', 'sku_nq_cate_shop_id_type_1', 'type_nq_cate_shop_id_type_1', 'brand_nq_cate_shop_id_type_1', 'shop_nq_cate_shop_id_type_1', 'cate_nq_cate_shop_id_type_1', 'first_hour_gap_cate_shop_id_type_1', 'last_hour_gap_cate_shop_id_type_1', 'act_days_cate_shop_id_type_1', 'sku_cnt_cate_shop_id_type_2', 'sku_nq_cate_shop_id_type_2', 'type_nq_cate_shop_id_type_2', 'brand_nq_cate_shop_id_type_2', 'shop_nq_cate_shop_id_type_2', 'cate_nq_cate_shop_id_type_2', 'first_hour_gap_cate_shop_id_type_2', 'last_hour_gap_cate_shop_id_type_2', 'act_days_cate_shop_id_type_2', 'sku_cnt_cate_shop_id_type_3', 'sku_nq_cate_shop_id_type_3', 'type_nq_cate_shop_id_type_3', 'brand_nq_cate_shop_id_type_3', 'shop_nq_cate_shop_id_type_3', 'cate_nq_cate_shop_id_type_3', 'first_hour_gap_cate_shop_id_type_3', 'last_hour_gap_cate_shop_id_type_3', 'act_days_cate_shop_id_type_3', 'sku_cnt_cate_shop_id_type_4', 'sku_nq_cate_shop_id_type_4', 'type_nq_cate_shop_id_type_4', 'brand_nq_cate_shop_id_type_4', 'shop_nq_cate_shop_id_type_4', 'cate_nq_cate_shop_id_type_4', 'first_hour_gap_cate_shop_id_type_4', 'last_hour_gap_cate_shop_id_type_4', 'act_days_cate_shop_id_type_4', 'buybro_ratio_cate_shop_id', 'buyfocus_ratio_cate_shop_id', 'buycom_ratio_cate_shop_id', 'sku_cnt_user_id_cate_shop_id', 'sku_nq_user_id_cate_shop_id', 'type_nq_user_id_cate_shop_id', 'brand_nq_user_id_cate_shop_id', 'shop_nq_user_id_cate_shop_id', 'cate_nq_user_id_cate_shop_id', 'first_hour_gap_user_id_cate_shop_id', 'last_hour_gap_user_id_cate_shop_id', 'act_days_user_id_cate_shop_id', 'sku_cnt_user_id_cate_shop_id_type_1', 'sku_nq_user_id_cate_shop_id_type_1', 'type_nq_user_id_cate_shop_id_type_1', 'brand_nq_user_id_cate_shop_id_type_1', 'shop_nq_user_id_cate_shop_id_type_1', 'cate_nq_user_id_cate_shop_id_type_1', 'first_hour_gap_user_id_cate_shop_id_type_1', 'last_hour_gap_user_id_cate_shop_id_type_1', 'act_days_user_id_cate_shop_id_type_1', 'sku_cnt_user_id_cate_shop_id_type_2', 'sku_nq_user_id_cate_shop_id_type_2', 'type_nq_user_id_cate_shop_id_type_2', 'brand_nq_user_id_cate_shop_id_type_2', 'shop_nq_user_id_cate_shop_id_type_2', 'cate_nq_user_id_cate_shop_id_type_2', 'first_hour_gap_user_id_cate_shop_id_type_2', 'last_hour_gap_user_id_cate_shop_id_type_2', 'act_days_user_id_cate_shop_id_type_2', 'sku_cnt_user_id_cate_shop_id_type_3', 'sku_nq_user_id_cate_shop_id_type_3', 'type_nq_user_id_cate_shop_id_type_3', 'brand_nq_user_id_cate_shop_id_type_3', 'shop_nq_user_id_cate_shop_id_type_3', 'cate_nq_user_id_cate_shop_id_type_3', 'first_hour_gap_user_id_cate_shop_id_type_3', 'last_hour_gap_user_id_cate_shop_id_type_3', 'act_days_user_id_cate_shop_id_type_3', 'sku_cnt_user_id_cate_shop_id_type_4', 'sku_nq_user_id_cate_shop_id_type_4', 'type_nq_user_id_cate_shop_id_type_4', 'brand_nq_user_id_cate_shop_id_type_4', 'shop_nq_user_id_cate_shop_id_type_4', 'cate_nq_user_id_cate_shop_id_type_4', 'first_hour_gap_user_id_cate_shop_id_type_4', 'last_hour_gap_user_id_cate_shop_id_type_4', 'act_days_user_id_cate_shop_id_type_4', 'buybro_ratio_user_id_cate_shop_id', 'buyfocus_ratio_user_id_cate_shop_id', 'buycom_ratio_user_id_cate_shop_id', 'age', 'sex', 'user_lv_cd', 'city_level', 'province', 'city', 'county', 'fans_num', 'vip_num', 'shop_score']
4.特征选择
特征选择使用随机森林,下面的代码输出特征重要度排名。
from model.feat_columns import *
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import numpy as np
from sklearn.preprocessing import Imputer
"""
使用随机森林进行特征选择
"""
train_set = pd.read_hdf('../datasets/test_set.h5', key='test_set')
# train_set = pd.read_hdf('../../datasets/train_set.h5', key='train_set')
X = train_set[feat_columns].values
print(X.shape) # 7day-1 (1560848, 349) (1560848, 328) 7day-7 (1560852, 349)
y = train_set['label'].values
# 如果用全量数据跑不动
seed = 3
test_size = 0.3
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=seed)
clf = RandomForestClassifier(random_state=seed)
# 缺失值填充
X_train = Imputer().fit_transform(X_train)
print('fit...')
clf.fit(X_train, y_train)
print('done')
importance = clf.feature_importances_
indices = np.argsort(importance)[::-1]
features = train_set[feat_columns].columns
l = []
for i in range(X_train.shape[1]):
print(("%2d) %-*s %f" % (i + 1, 30, features[indices[i]], importance[indices[i]])))
l.append(features[indices[i]])
print(l)
5.模型选择
首先判断一下你要处理的问题属于哪一类,是分类、聚类还是回归等等。确定好类别后,再通过验证集来查看此类中各个算法的表现,从而选择合适的模型。因为目前比赛常用且效果最好的只有lightgbm和xgboost,所以我此次并没有进行模型选择,就用了这两个算法。大家可以查一下sklearn.model_selection包的相关文档。
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold,StratifiedKFold
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import LeaveOneOut
from sklearn.model_selection import cross_val_score
6.参数选择
import xgboost as xgb
from sklearn.model_selection import GridSearchCV
from collections import Counter
from model.feat_columns import *
train_set = pd.read_hdf('../../datasets/train_set.h5', key='train_set')
X_train = train_set[feat_columns].values
y_train = train_set['label'].values
c = Counter(y_train)
# n = c[0] / 16 / c[1] # 8
n = c[0] / c[1] # 129.56
print(n)
parameters = {
'max_depth': [5, 10, 15, 20, 25],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'n_estimators': [500, 1000, 2000, 3000, 5000],
'min_child_weight': [0, 2, 5, 10, 20],
'max_delta_step': [0, 0.2, 0.6, 1, 2],
'subsample': [0.6, 0.7, 0.8, 0.85, 0.95],
'colsample_bytree': [0.5, 0.6, 0.7, 0.8, 0.9],
'reg_alpha': [0, 0.25, 0.5, 0.75, 1],
'reg_lambda': [0.2, 0.4, 0.6, 0.8, 1],
'scale_pos_weight': [0.2, 0.4, 0.6, 0.8, 1, 8, n]
}
xlf = xgb.XGBClassifier(max_depth=10,
learning_rate=0.01,
n_estimators=2000,
silent=True,
objective='binary:logistic',
nthread=12,
gamma=0,
min_child_weight=1,
max_delta_step=0,
subsample=0.85,
colsample_bytree=0.7,
colsample_bylevel=1,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=1440,
missing=None)
gsearch = GridSearchCV(xlf, param_grid=parameters, scoring='accuracy', cv=3)
gsearch.fit(X_train, y_train)
print("Best score: %0.3f" % gsearch.best_score_)
print("Best parameters set:")
best_parameters = gsearch.best_estimator_.get_params()
for param_name in sorted(parameters.keys()):
print("\t%s: %r" % (param_name, best_parameters[param_name]))
7.模型训练与评估
选好特征、模型和参数后开始对模型进行训练和评估,最后再使用前面的测试集(不是这里训练集划分的测试集)查看模型效果。
import pickle
from collections import Counter
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
from model.feat_columns import *
threshold = 0.3
train_set = pd.read_hdf('../../datasets/train_set.h5', key='train_set')
'''
pos_sample = train_set[train_set['label'] == 1]
n = len(pos_sample)
print(n)
neg_sample = train_set[train_set['label'] == 0].sample(n=n, random_state=1)
del train_set
train_set = pos_sample.append(neg_sample)
'''
X = train_set[feat_columns].values
print(X.shape) # 7day (1560852, 349)
y = train_set['label'].values
c = Counter(y) # Counter({0.0: 1545471, 1.0: 15377})
print(c)
train_metrics = train_set[['user_id', 'cate', 'shop_id', 'label']]
del train_set
# split data into train and test sets
seed = 3
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=seed)
c = Counter(y_train)
print(c) # 7day Counter({0.0: 1035454, 1.0: 10314})
# c[0] / 16 / c[1] 8 | c[0] / c[1] 129.56
clf = XGBClassifier(max_depth=5, min_child_weight=6, scale_pos_weight=c[0] / 16 / c[1], n_estimators=100, nthread=12,
seed=0, subsample=0.5)
eval_set = [(X_test, y_test)]
clf.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True)
# make predictions for test data
y_pred = clf.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
y_train_predict = clf.predict_proba(X)[:, 1]
# y_train_predict = clf.predict(X)
# train_metrics['pre_label'] = y_train_predict
train_metrics['pred_prob'] = y_train_predict
# pred = train_metrics[train_metrics['pre_label'] == 1]
pred = train_metrics[train_metrics['pred_prob'] > threshold]
truth = train_metrics[train_metrics['label'] == 1]
print('X train pred num is:', len(pred))
print("训练集分数:")
get_final_score(pred, truth)
del train_metrics
pickle.dump(clf, open('../user_model/baseline.pkl', 'wb'))
# clf = pickle.load(open('../user_model/baseline.pkl', 'rb'))
8.模型融合
模型融合就是训练多个模型,然后按照一定的方法整合多个模型输出的结果,常用的有加权平均、投票、学习法等等,请自行百度。模型融合的结果往往优于单个模型,常用于最后的成绩提升。我此次只是对lightgbm和xgboost两个算法预测出的概率进行简单的加权求和,然后取了topN的结果进行提交。
参考链接:

 博客专家
博客专家