假设小明是银行的一名客户研究员,他想利用银行客户的年龄(X1)与工资(X2)建立一个预测模型,预测不同客户存款数额(Y)的大小。
目前他手头已经有银行客户的历史数据表:X1列记录客户年龄、X2列记录客户工资、Y列记录客户存款数额。
最开始,他建立了最简单的预测方程:
(小明知道不同变量所占的权重是不一样的,方程中变量前的参数就代表权重)
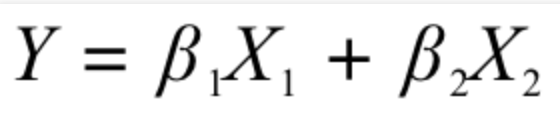
然后,他用手头的数据去训练该方程,发现该方程并不是能够拟合最多样本点的方程,于是他需要对方程进行上下微调,让方程线尽量通过更多的样本点:
(多加的截距项就是起到微调的作用,但重点还是在变量参数上)
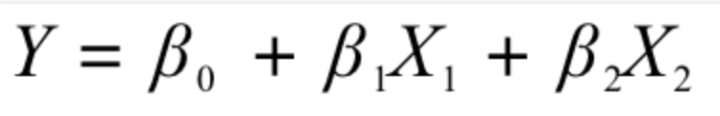
但是,他发现不管怎么微调方程,总有些样本点的预测值与真实值Y存在差异,所以需要在方程中体现出该差异才科学:
(预测方程中加入了误差项,真实值=预测值+误差)
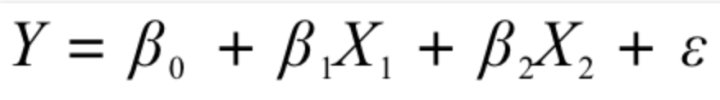
因为银行的数据都是数据表,相当于数学中的矩阵,为了方便计算,小明又在数据表中加入了一列值全部为1的X0列,相应的,方程规范为:
(这样方程就可以方便的放入矩阵计算了)
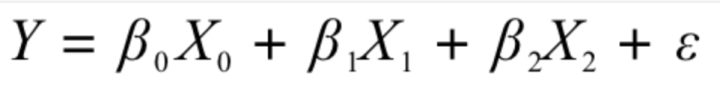
现在,较为标准科学的预测方程建好了,现在最关键的就是搞清X1,X2是如何影响Y的?影响程度如何?也就是要求变量的参数(正负和大小)
那该如何求变量的参数呢?
小明通过查资料发现,误差项可以作为突破点:
对于误差项的假设是:
- 独立:每个人来银行存款都是互不影响的,一个人不会因为他前面的人存款多,他就想着存少一点。
- 同分布:小明进行客户调研肯定是以自己银行的客户为样本,样本中不会有其他银行的客户信息。
- 服从均值是0,方差为西格玛方的高斯分布(正态分布):日常生活都是平衡稳定的。
既然误差项服从上述正态分布,那么它的概率密度函数就是1式:
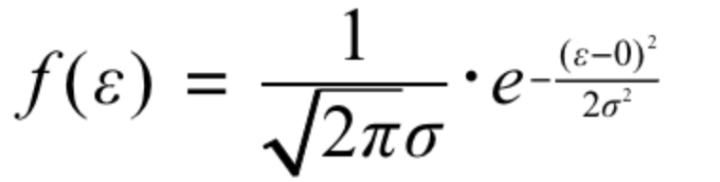
又因为误差项可以表示为2式:

所以将2式带入1式,等到关于Y、X、和参数的方程:
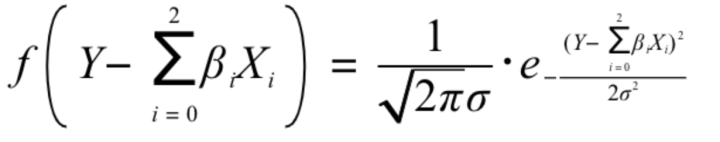
小明只要通过上式求出参数就好了,可是该如何求呢?
小明知道研究客户不能只研究一个,而是要研究许多的客户,每个客户都有其边缘概率密度函数。
又因为误差项是独立同分布的,所以联合概率密度函数=边缘概率密度函数之积。
这样,就自然而然地构造出了极大似然函数
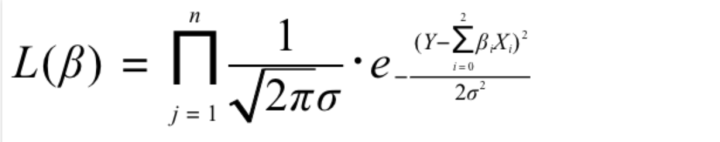
极大似然函数可以理解为:求解当参数为多少时,预测值接近真实值的概率最大
对极大似然函数去ln对数化简,得到:
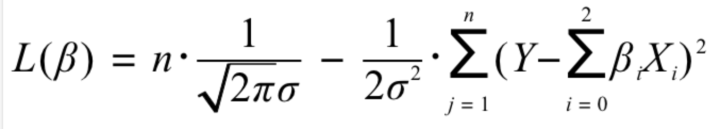
要求最大概率,需要对下式求最小值,使用的就是最小二乘法:

通过最小二乘法的计算(计算交给电脑就好),小明终于求出了各个参数,完成了预测方程(线性回归方程)的建立。
