Structured Streaming Programming Guide
官方文档 Structured Streaming Programming Guide
目录
- Overview
- Quick Example
- Programming Model
- Basic Concepts
- Handling Event-time and Late Data
- Fault Tolerance Semantics
- API using Datasets and DataFrames
- Creating streaming DataFrames and streaming Datasets
- Input Sources
- Schema inference and partition of streaming DataFrames/Datasets
- Operations on streaming DataFrames/Datasets
- Basic Operations - Selection, Projection, Aggregation
- Window Operations on Event Time
- Handling Late Data and Watermarking
- Join Operations
- Stream-static Joins
- Stream-stream Joins
- Inner Joins with optional Watermarking
- Outer Joins with Watermarking
- Support matrix for joins in streaming queries
- Streaming Deduplication
- Policy for handling multiple watermarks
- Arbitrary Stateful Operations
- Unsupported Operations
- Starting Streaming Queries
- Output Modes
- Output Sinks
- Using Foreach and ForeachBatch
- ForeachBatch
- Foreach
- Using Foreach and ForeachBatch
- Triggers
- Managing Streaming Queries
- Monitoring Streaming Queries
- Reading Metrics Interactively
- Reporting Metrics programmatically using Asynchronous APIs
- Reporting Metrics using Dropwizard
- Recovering from Failures with Checkpointing
- Recovery Semantics after Changes in a Streaming Query
- Creating streaming DataFrames and streaming Datasets
- Continuous Processing
- Additional Information
Overview
结构化流是一种基于 Spark SQL 引擎的可扩展且容错的流处理引擎。您可以像表达静态数据的批处理计算一样表达流式计算。 Spark SQL 引擎将负责逐步和连续地运行它,并在流数据继续到达时更新最终结果。您可以使用Scala,Java,Python 或 R 中的 Dataset/DataFrame API 来表示流聚合、事件时间窗口,流到批的 join 等。计算在相同的 Spark SQL 优化引擎上执行。最后,系统通过检查点和预写日志确保端到端的恰好一次性的容错保证。简而言之,Structured Streaming提供快速、可扩展、容错、端到端的精确一次性语义的流处理,而无需用户推理流式传输。
在内部,默认情况下,结构化流式查询使用微批处理引擎进行处理,该引擎将数据流作为一系列小批量作业处理,从而实现低至100毫秒的端到端延迟和完全一次的容错保证。但是,自 Spark 2.3 以来,我们引入了一种称为连续处理的新型低延迟处理模式,它可以实现低至1毫秒的端到端延迟,并且具有至少一次保证。无需更改查询中的 Dataset/DataFrame 操作,您就可以根据应用程序要求选择模式。
在本指南中,我们将引导您完成编程模型和 API。我们将主要使用默认的微批处理模型来解释这些概念,然后讨论连续处理模型。首先,让我们从一个结构化流式查询的简单示例开始 —— 一个流式单词计数。
Quick Example
假设您希望维护一个从 TCP 套接字的数据服务监听器接收的文本数据的运行单词计数。 让我们看看如何使用 Structured Streaming 表达这一点。 您可以在Scala / Java / Python / R 中看到完整的代码。 如果你下载 Spark,你可以直接运行这个例子。 在任何情况下,让我们一步一步地了解示例,并了解它是如何工作的。 首先,我们必须导入必要的类并创建一个本地 SparkSession,这是与Spark相关的所有功能的起点。
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder
.appName("StructuredNetworkWordCount")
.getOrCreate()
import spark.implicits._
接下来,让我们创建一个流式 DataFrame,它表示从侦听 localhost:9999 的服务器接收的文本数据,并转换 DataFrame 以计算字数。
// Create DataFrame representing the stream of input lines from connection to localhost:9999
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
// Split the lines into words
val words = lines.as[String].flatMap(_.split(" "))
// Generate running word count
val wordCounts = words.groupBy("value").count()
这行 DataFrame 表示包含流文本数据的无界表。此表包含一列名为 “value” 的字符串,并且流式文本数据中的每一行都成为表中的一行。请注意,由于我们只是设置转换,并且尚未启动它,因此目前没有接收任何数据。接下来,我们使用 .as [String] 将 DataFrame 转换为 String 类型的数据集,以便我们可以应用 flatMap 操作将每行拆分为多个单词。生成的单词Dataset 包含所有单词。最后,我们通过对 Dataset 的唯一值进行分组并对它们进行计数来定义 wordCounts DataFrame。请注意,这是一个流式 DataFrame,它表示流的运行字数。
我们现在已经设置了关于流数据的查询。剩下的就是实际开始接收数据并计算计数。为此,我们将其设置为每次更新时将完整的计数集(由 outputMode(“complete”) 指定)打印到控制台。然后使用start() 开始流式计算。
// Start running the query that prints the running counts to the console
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()
执行此代码后,流式计算将在后台启动。 查询对象是该活动流式查询的句柄,我们决定使用 awaitTermination() 等待查询终止,以防止进程在查询处于活动状态时退出。
要实际执行此示例代码,您可以在自己的 Spark 应用程序中编译代码,或者只需在下载Spark后运行该示例。 我们正在展示后者。 您首先需要使用 Netcat(在大多数类Unix系统中找到的小实用程序)作为数据服务器运行
$ nc -lk 9999
然后,在不同的终端中,您可以使用启动示例
$ ./bin/run-example org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount localhost 9999
# TERMINAL 1:
# Running Netcat
$ nc -lk 9999
apache spark
apache hadoop
# TERMINAL 2: RUNNING StructuredNetworkWordCount
$ ./bin/run-example org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount localhost 9999
-------------------------------------------
Batch: 0
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
|apache| 1|
| spark| 1|
+------+-----+
-------------------------------------------
Batch: 1
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
|apache| 2|
| spark| 1|
|hadoop| 1|
+------+-----+
...
Programming Model
结构化流中的关键思想是将实时数据流视为连续追加的表。 这导致新的流处理模型非常类似于批处理模型。 您将流式计算表示为静态表上的标准批处理查询,Spark 将其作为无界输入表上的增量查询运行。 让我们更详细地了解这个模型。
基本概念(Basic Concepts)
将输入数据流视为“输入的表”。 到达流的每个数据项都像一个新行被附加到输入表。
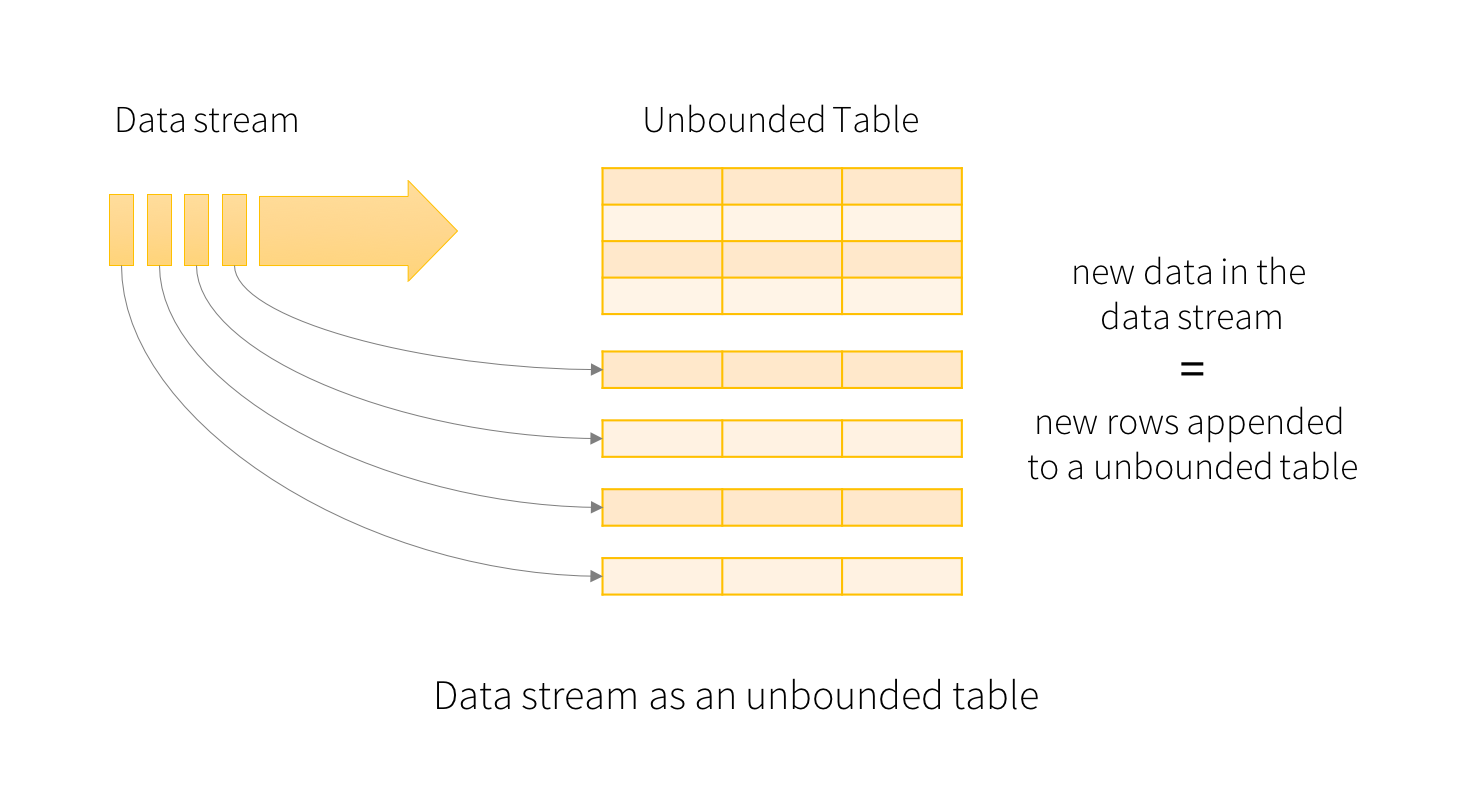
对输入的查询将生成“结果表”。 每个触发间隔(例如,每1秒),新行将附加到输入表,最终更新结果表。 每当结果表更新时,我们都希望将更改的结果行写入外部接收器。
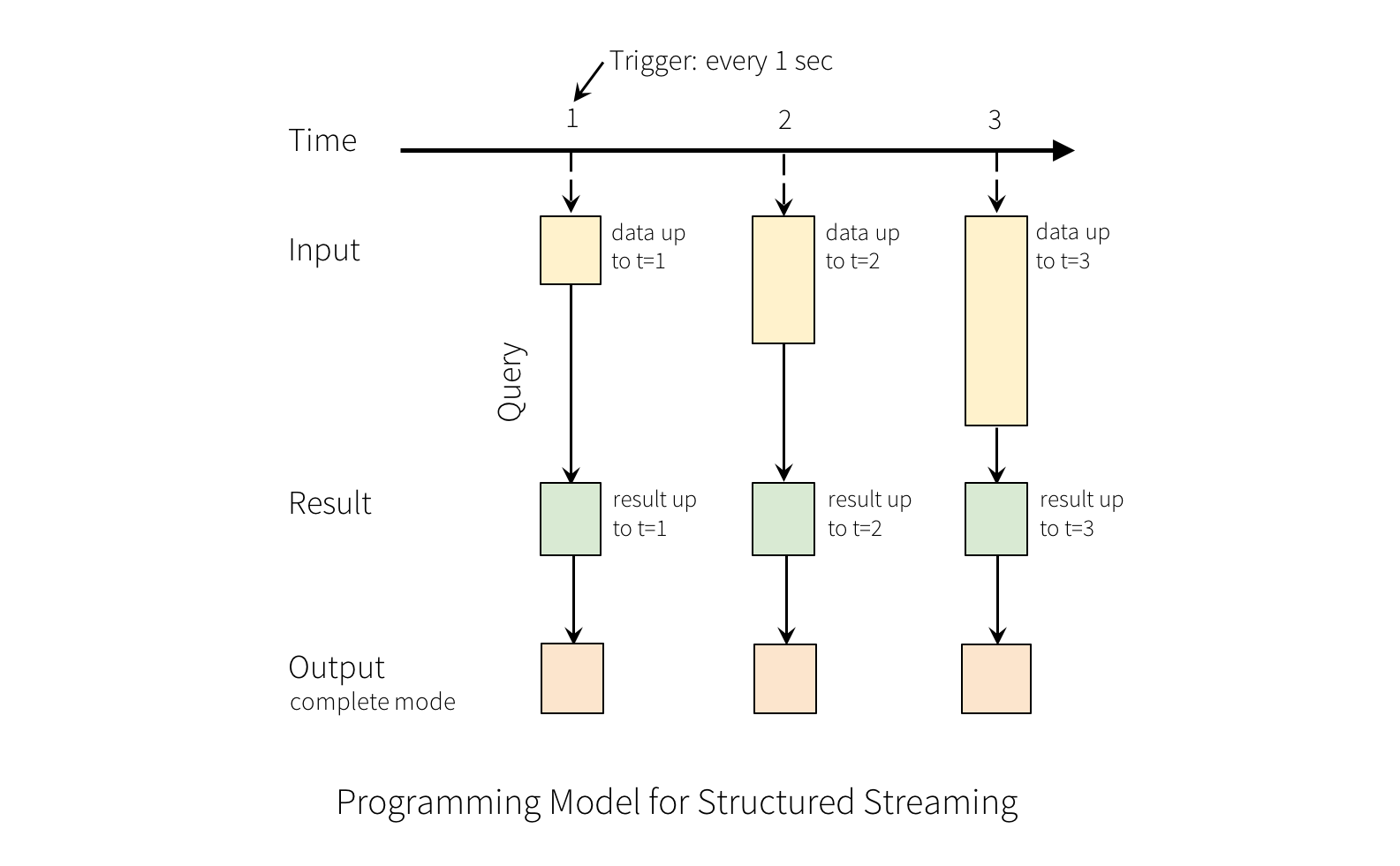
“输出”定义为写入外部存储器的内容。输出可以以不同的模式定义:
* Complete Mode(完整模式) - 整个更新的结果表将写入外部存储。由存储连接器决定如何处理整个表的写入。
* Append Mode(追加模式) - 自上次触发后,只有结果表中附加的新行才会写入外部存储器。这仅适用于预计结果表中的现有行不会更改的查询。
* Update Mode(更新模式) - 只有自上次触发后在结果表中更新的行才会写入外部存储(自Spark 2.1.1起可用)。请注意,这与 Complete Mode(完整模式)的不同之处在于此模式仅输出自上次触发后已更改的行。如果查询不包含聚合,则它将等同于 Append Mode(追加模式)。
请注意,每种模式适用于某些类型的查询。稍后将对此进行详细讨论。
为了说明此模型的使用,让我们在上面的快速示例的上下文中理解模型。第一行 DataFrame 是输入表,最后一个 wordCounts DataFrame 是结果表。请注意,生成 wordCounts 的流式 line 的 DataFrame 上的查询与静态 DataFrame 完全相同。但是,当启动此查询时,Spark将不断检查套接字连接中的新数据。如果有新数据,Spark 将运行“增量”查询,该查询将先前运行的计数与新数据相结合,以计算更新的计数,如下所示。
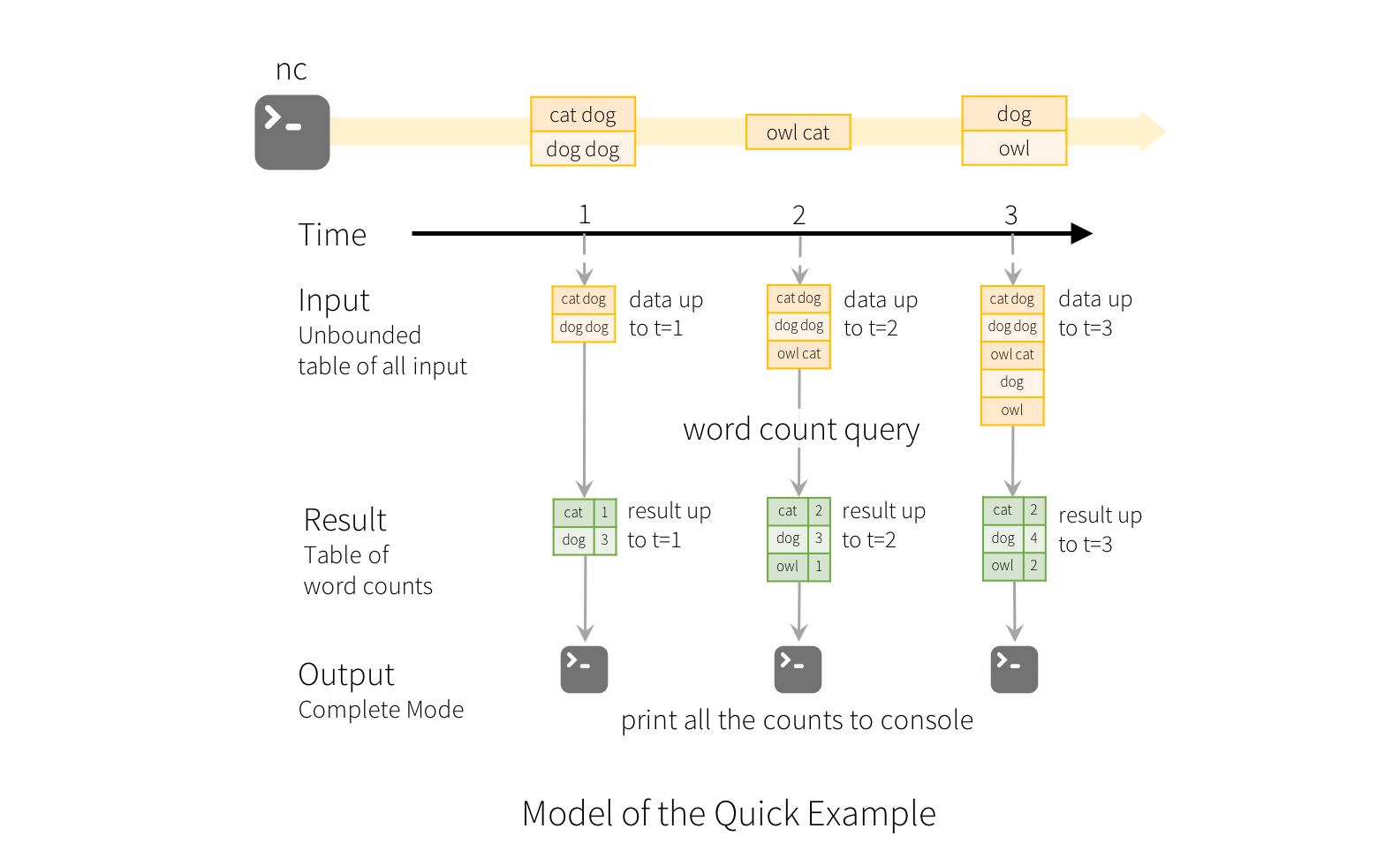
请注意,Structured Streaming不会实现整个表。 它从流数据源读取最新的可用数据,逐步处理以更新结果,然后丢弃源数据。 它只保留更新结果所需的最小中间状态数据(例如前面例子中的中间计数)。
该模型与许多其他流处理引擎明显不同。 许多流系统要求用户自己维护运行聚合,因此必须推理容错和数据一致性(至少一次,或至多一次,或完全一次)。 在此模型中,Spark 负责在有新数据时更新结果表,从而减轻用户对其的推理。 作为一个例子,让我们看看这个模型如何处理基于事件时间的处理和迟到的数据。
处理事件时间和后续数据(Handling Event-time and Late Data)
事件时间是嵌入数据本身的时间。 对于许多应用程序,您可能希望在此事件时间运行。 例如,如果您想每分钟获取IoT设备生成的事件数,那么您可能希望使用生成数据的时间(即数据中的事件时间),而不是Spark接收他们的时间。 此事件时间在此模型中非常自然地表达 - 来自设备的每个事件都是表中的一行,事件时间是行中的列值。 这允许基于窗口的聚合(例如,每分钟的事件数)在事件时间列上只是一种特殊类型的分组和聚合 - 每个时间窗口是一个组,每行可以属于多个窗口/组。 因此,可以在静态数据集(例如,来自收集的设备事件日志)以及数据流上一致地定义这种基于事件时间窗口的聚合查询,使得用户的生活更加容易。
此外,该模型自然地处理基于其事件时间到达的时间晚于预期的数据。 由于 Spark 正在更新结果表,因此它可以在存在延迟数据时完全控制更新旧聚合,以及清理旧聚合以限制中间状态数据的大小。 从 Spark 2.1开始,我们支持 watermarking ,允许用户指定后期数据的阈值,并允许引擎相应地清理旧状态。 稍后将在窗口操作部分中详细介绍这些内容。
容错语义(Fault Tolerance Semantics)
提供端到端的一次性语义是结构化流的设计背后的关键目标之一。 为实现这一目标,我们设计了结构化流媒体源,接收器和执行引擎,以可靠地跟踪处理的确切进度,以便通过重新启动和/或重新处理来处理任何类型的故障。 假设每个流源都具有偏移(类似于 Kafka 偏移或Kinesis 序列号)以跟踪流中的读取位置。 引擎使用检查点和预写日志来记录每个触发器中正在处理的数据的偏移范围。 流式接收器设计为处理重新处理的幂等功能。结合使用可重放的源和幂等接收器,结构化流可以确保在任何失败的情况下端到端完全一次的语义。
使用 Datasets 和 DataFrames API
从 Spark 2.0 开始,DataFrames 和 Datasets 可以表示静态的、有界的数据,以及流式、无界数据。 与静态 Datasets/DataFrames 类似,您可以使用公共入口点 SparkSession(Scala / Java / Python / R docs)从流源创建流式 Datasets/DataFrames,并对它们应用与静态 Datasets/DataFrames 相同的操作。 如果您不熟悉 Datasets/DataFrames,强烈建议您使用 Datasets/DataFrames 编程指南熟悉它们。
创建 DataFrames 流和 Datasets 流
可以通过 SparkSession.readStream() 返回的 DataStreamReader 接口(Scala / Java / Python文档)创建 Streaming DataFrame。 在R中,使用read.stream() 方法。 与用于创建静态 DataFrame 的读取接口类似,您可以指定源的详细信息 - 数据格式,架构,选项等。
Input Sources
有一些内置源。
-
File source(文件来源) - 将目录中写入的文件作为数据流读取。支持的文件格式为text,csv,json,orc,parquet。有关更新的列表,请参阅 DataStreamReader 接口的文档,以及每种文件格式支持的选项。请注意,文件必须原子地放置在给定目录中,在大多数文件系统中,可以通过文件移动操作来实现。
-
Kafka source(Kafka来源) - 从Kafka读取数据。它与Kafka broker 版本0.10.0或更高版本兼容。有关更多详细信息,请参阅Kafka集成指南。
-
Socket source(用于测试) - 从套接字连接读取UTF8文本数据。侦听服务器套接字位于驱动程序中。请注意,这应仅用于测试,因为这不提供端到端的容错保证。
-
Rate source(用于测试) - 以每秒指定的行数生成数据,每个输出行包含时间戳和值。其中timestamp是包含消息调度时间的 Timestamp 类型,value是包含消息计数的Long类型,从0开始作为第一行。此源用于测试和基准测试。
某些源不具有容错能力,因为它们无法保证在发生故障后可以使用检查点偏移重放数据。 请参阅前面的容错语义部分。 以下是Spark中所有源代码的详细信息。
-
File source
-
Options
path:输入目录的路径,对所有文件格式都是通用的。
maxFilesPerTrigger:每次触发时要考虑的最大新文件数(默认值:无最大值)
latestFirst:是否先处理最新的新文件,在有大量文件积压时很有用(默认值:false)
fileNameOnly:是否仅基于文件名而不是完整路径检查新文件(默认值:false)。 将此设置为“true”时,以下文件将被视为同一文件,因为它们的文件名“dataset.txt”是相同的:
“file:///dataset.txt”
“S3://a/dataset.txt”
“S3N://a/b/dataset.txt”
“S3A://a/b/c/dataset.txt”有关 file-format-specific 选项,请参阅 DataStreamReader(Scala / Java / Python / R)中的相关方法。 例如。
对于“parquet”格式选项,请参阅DataStreamReader.parquet()。此外,还有会话配置会影响某些文件格式。 有关更多详细信息,请参见SQL编程指南。 例如,对于“parquet”,请参见Parquet配置部分。
-
Fault-tolerant: 是
-
Notes
支持glob路径,但不支持多个以逗号分隔的路径/ globs。
-
-
Socket Source
-
Options
host:要连接的主机,必须指定
port:要连接的端口,必须指定 -
Fault-tolerant: No
-
Notes
-
-
Rate Source
-
Options
rowsPerSecond(例如100,默认值:1):每秒应生成多少行。
rampUpTime(例如5s,默认值:0s):在生成速度变为rowsPerSecond之前加速多长时间。 使用比秒更精细的粒度将被截断为整数秒。
numPartitions(例如10,默认值:Spark的默认并行性):生成的行的分区号。
源将尽力达到rowsPerSecond,但查询可能受资源限制,并且可以调整 numPartitions 以帮助达到所需的速度。 -
Fault-tolerant: Yes
-
Notes
-
-
Kafka Source
-
Options
请参阅Kafka集成指南。 -
Fault-tolerant: Yes
-
Notes
-
这里有些例子。
val spark: SparkSession = ...
// Read text from socket
val socketDF = spark
.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
socketDF.isStreaming // Returns True for DataFrames that have streaming sources
socketDF.printSchema
// Read all the csv files written atomically in a directory
val userSchema = new StructType().add("name", "string").add("age", "integer")
val csvDF = spark
.readStream
.option("sep", ";")
.schema(userSchema) // Specify schema of the csv files
.csv("/path/to/directory") // Equivalent to format("csv").load("/path/to/directory")
这些示例生成无类型的流式 DataFrame,这意味着在编译时不检查DataFrame的架构,仅在提交查询时在运行时检查。 map,flatMap等一些操作需要在编译时知道类型。 要执行这些操作,您可以使用与静态DataFrame相同的方法将这些无类型的流式DataFrame转换为类型化的流式数据集。 有关更多详细信息,请参见SQL编程指南。 此外,有关受支持的流媒体源的更多详细信息将在本文档后面讨论。
流式 DataFrames/Datasets 的模式推理和分区
默认情况下,基于文件的源的结构化流需要您指定架构,而不是依靠 Spark 自动推断它。 此限制可确保即使在出现故障的情况下,也将使用一致的架构进行流式查询。 对于临时用例,可以通过将 spark.sql.streaming.schemaInference 设置为true来重新启用模式推断。
当名为 /key=value/ 的子目录存在且列表将自动递归到这些目录中时,确实会发生分区发现。 如果这些列出现在用户提供的模式中,则Spark将根据正在读取的文件的路径填充它们。 构成分区方案的目录必须在查询开始时存在,并且必须保持静态。 例如,可以添加 /data/year=2016/when/data/year=2015/ ,但更改分区列无效(即通过创建目录 /data/date=2016-04-17/ )。
流式 DataFrames/Datasets 操作
您可以对流式 DataFrames/Datasets 应用各种操作 - 从无类型,类似SQL的操作(例如select,where,groupBy)到类型化RDD类操作(例如map,filter,flatMap)。 有关更多详细信息,请参阅SQL编程指南。 我们来看看您可以使用的一些示例操作。
基本操作 - Selection, Projection(投影), Aggregation(聚合)
DataFrame/Dataset 上的大多数常见操作都支持流式传输。 本节稍后将讨论几个不受支持的操作。
case class DeviceData(device: String, deviceType: String, signal: Double, time: DateTime)
val df: DataFrame = ... // streaming DataFrame with IOT device data with schema { device: string, deviceType: string, signal: double, time: string }
val ds: Dataset[DeviceData] = df.as[DeviceData] // streaming Dataset with IOT device data
// Select the devices which have signal more than 10
df.select("device").where("signal > 10") // using untyped APIs
ds.filter(_.signal > 10).map(_.device) // using typed APIs
// Running count of the number of updates for each device type
df.groupBy("deviceType").count() // using untyped API
// Running average signal for each device type
import org.apache.spark.sql.expressions.scalalang.typed
ds.groupByKey(_.deviceType).agg(typed.avg(_.signal)) // using typed API
您还可以将流式 DataFrame/Dataset 注册为临时视图,然后在其上应用SQL命令。
df.createOrReplaceTempView("updates")
spark.sql("select count(*) from updates") // returns another streaming DF
注意,您可以使用 df.isStreaming 来识别 DataFrame/Dataset 是否具有流数据。
df.isStreaming
Window Operations on Event Time
使用结构化流式传输时,滑动事件时间窗口上的聚合非常简单,并且与分组聚合非常相似。 在分组聚合中,为用户指定的分组列中的每个唯一值维护聚合值(例如计数)。 在基于窗口的聚合的情况下,为每个窗口维护一行的事件时间的聚合值。 让我们通过一个例子来理解这一点。
想象一下,我们的快速示例已被修改,流现在包含行以及生成行的时间。 我们不想运行计数,而是计算10分钟内的单词,每5分钟更新一次。 也就是说,在10分钟窗口12:00-12:10,12:05-12:15,12:10-12:20等之间收到的单词数量。请注意,12:00 - 12:10表示数据在12:00之后但在12:10之前到达。 现在,考虑一下在12:07收到的一个单词。 这个词应该增加对应于两个窗口12:00 - 12:10和12:05 - 12:15的计数。 因此,计数将由分组键(即单词)和窗口(可以从事件时间计算)两者索引。
结果表看起来如下所示。
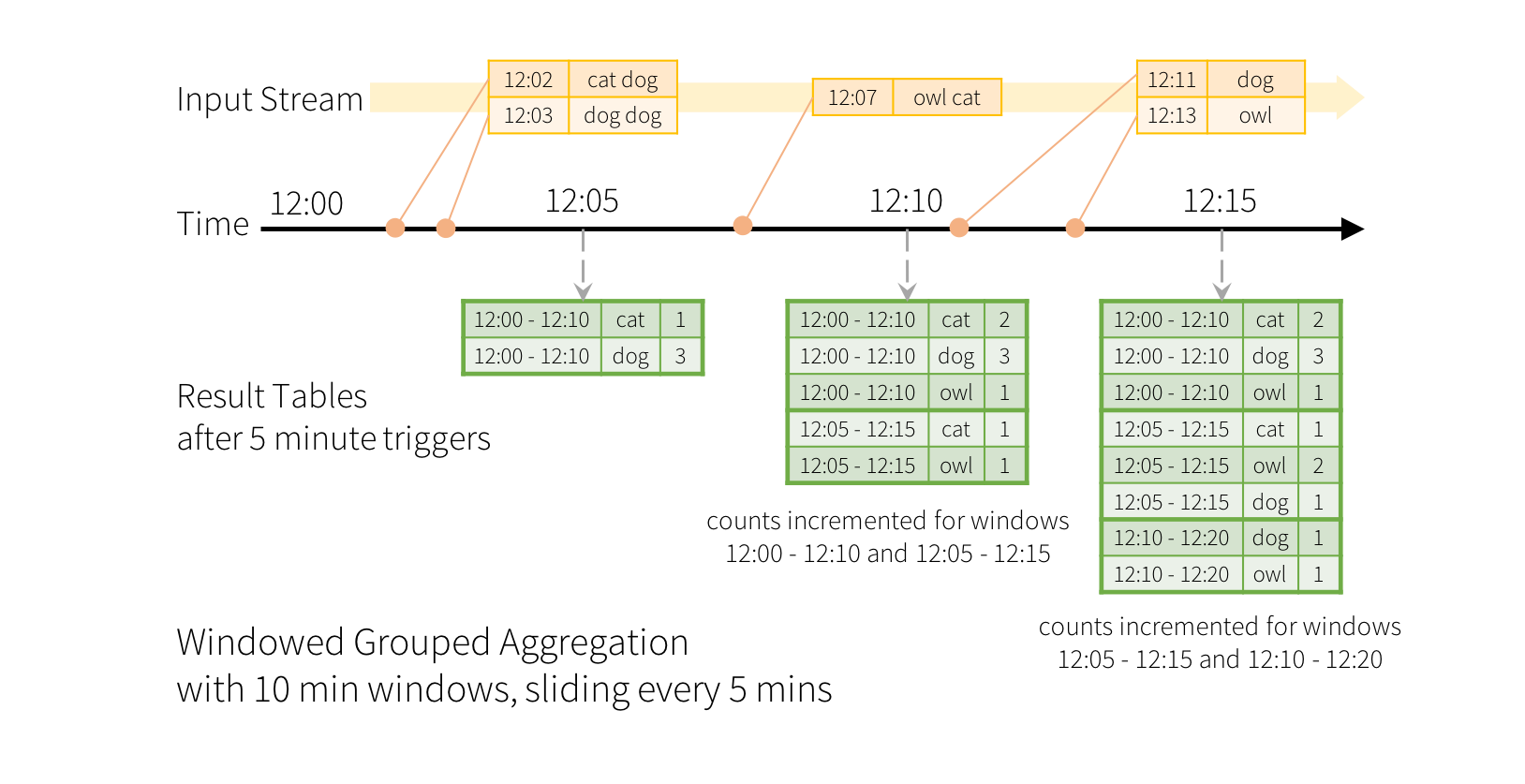
由于此窗口类似于分组,因此在代码中,您可以使用 groupBy() 和 window() 操作来表示窗口化聚合。 您可以在 Scala/Java/Python 中看到以下示例的完整代码。
import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word"
).count()
Handling Late Data and Watermarking
现在考虑如果其中一个事件到达应用程序较晚会发生什么。 例如,应用程序在12:11可以接收在12:04(即事件时间)生成的单词。 应用程序应使用时间12:04代替12:11来更新窗口12:00-12:10的旧计数。 这在我们基于窗口的分组中自然发生 - 结构化流可以长时间维持部分聚合的中间状态,以便后期数据可以正确更新旧窗口的聚合,如下所示。
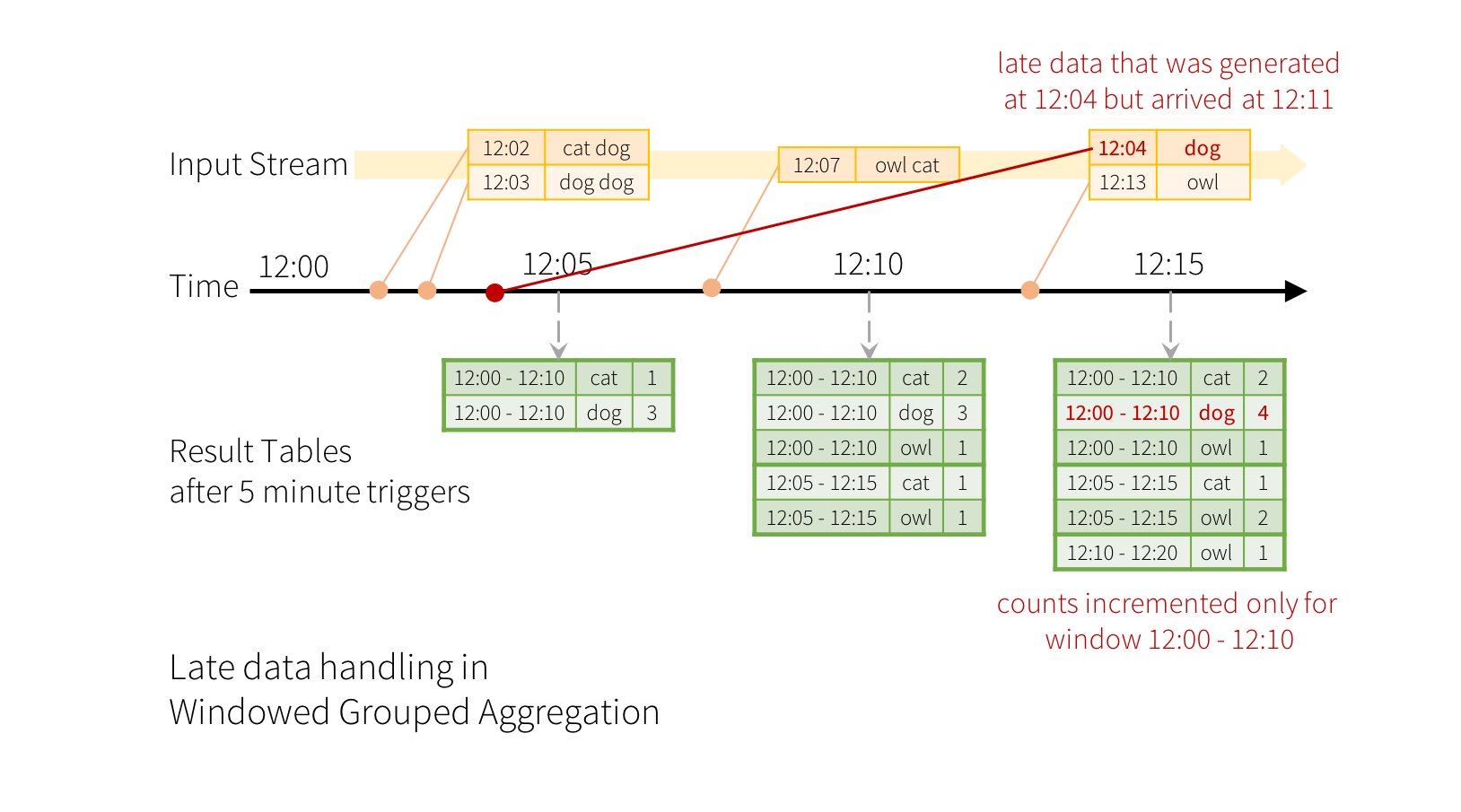
但是,要运行此查询数天,系统必须限制它累积的中间内存中状态的数量。这意味着系统需要知道何时可以从内存状态中删除旧聚合,因为应用程序不再接收该聚合的后期数据。为了实现这一点,我们在 Spark 2.1 中引入了水印(watermarking),使引擎能够自动跟踪数据中的当前事件时间并尝试相应地清理旧状态。您可以通过指定事件时间列来定义查询的水印,并根据事件时间确定数据预计的延迟时间。对于从时间T开始的特定窗口,引擎将保持状态并允许延迟数据更新状态直到(引擎看到的最大事件时间 - 迟阈值> T)。换句话说,阈值内的后期数据将被聚合,但是晚于阈值的数据将开始被丢弃(参见本节后面的精确保证)。让我们通过一个例子来理解这一点。我们可以使用withWatermark() 在上一个示例中轻松定义水印,如下所示。
import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words
.withWatermark("timestamp", "10 minutes")
.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word")
.count()
在这个例子中,我们在“timestamp”列的值上定义查询的水印,并且还将“10分钟”定义为允许数据延迟的阈值。 如果此查询在更新输出模式下( Update output mode)运行(稍后将在输出模式部分中讨论),则引擎将继续更新结果表中窗口的计数,直到窗口比水印更老,该水印落后于列中的当前事件时间“ 时间戳“10分钟。 这是一个例子。
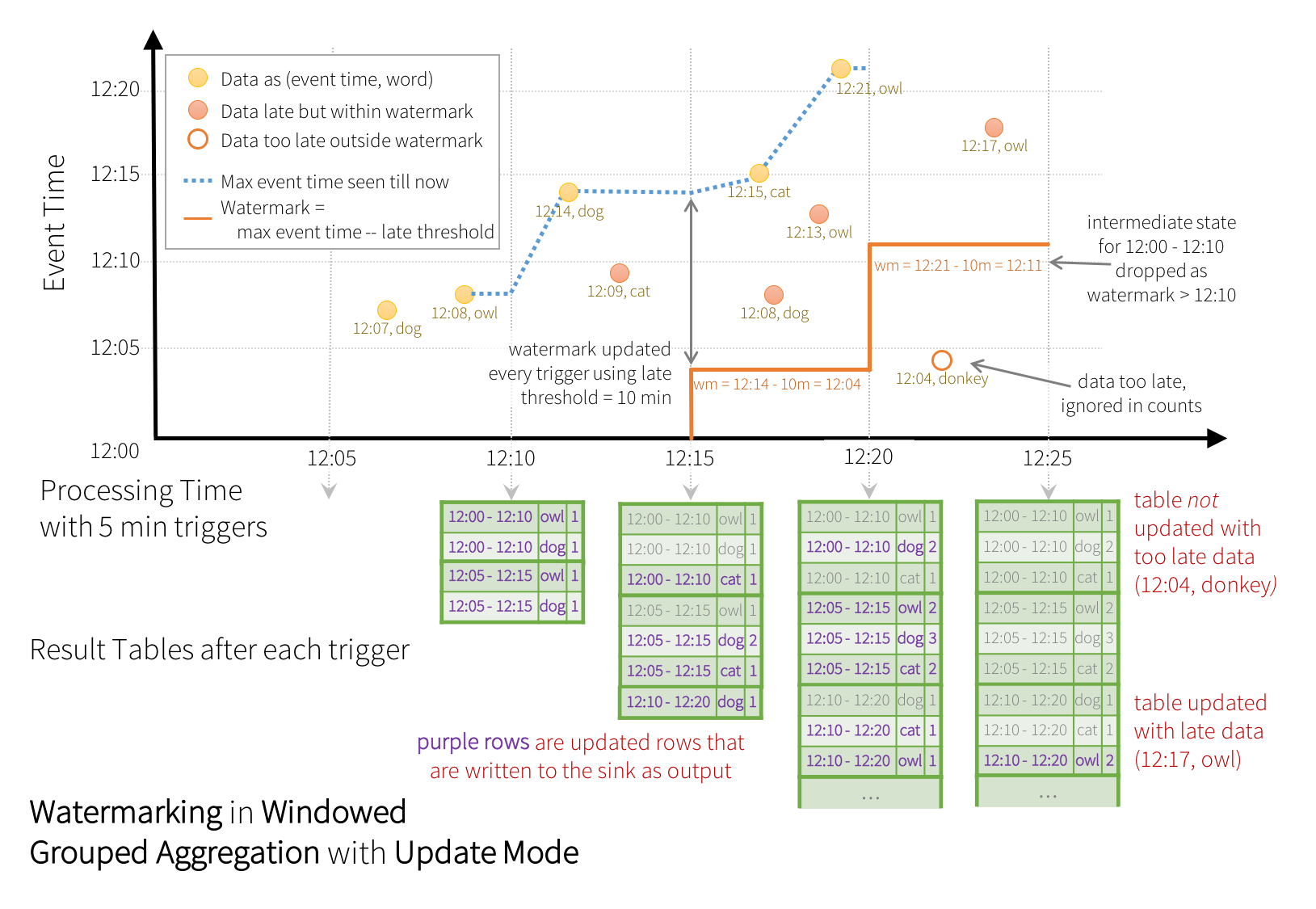
如图所示,引擎跟踪的最大事件时间是蓝色虚线,并且在每个触发开始时设置为(最大事件时间 - ‘10分钟’)的水印是红线。例如,当引擎观察数据(12:14,dog)时,它会将下一次触发的水印设置为12:04。该水印使引擎保持中间状态另外10分钟,以允许计算延迟数据。例如,数据(12:09,cat)无序且迟到,它在Windows 12:00-12:10和12:05 - 12:15之间。因为它仍然在触发器中的水印12:04之前,所以引擎仍然将中间计数保持为状态并且正确地更新相关窗口的计数。但是,当水印更新为12:11时,窗口的中间状态(12:00-12:10)被清除,所有后续数据(例如(12:04,donkey))被认为“太晚”,因此忽略了,在每次触发之后,更新的计数(即紫色行)被写入接收器作为触发输出,如更新模式所指示的。
某些接收器(例如文件)可能不支持更新模式所需的细粒度更新。 为了使用它们,我们还支持附加模式(Update Mode),其中只有最终计数被写入接收器。 这如下图所示。
请注意,在非流式数据集上使用withWatermark是no-op。 由于水印不应以任何方式影响任何批量查询,我们将直接忽略它。
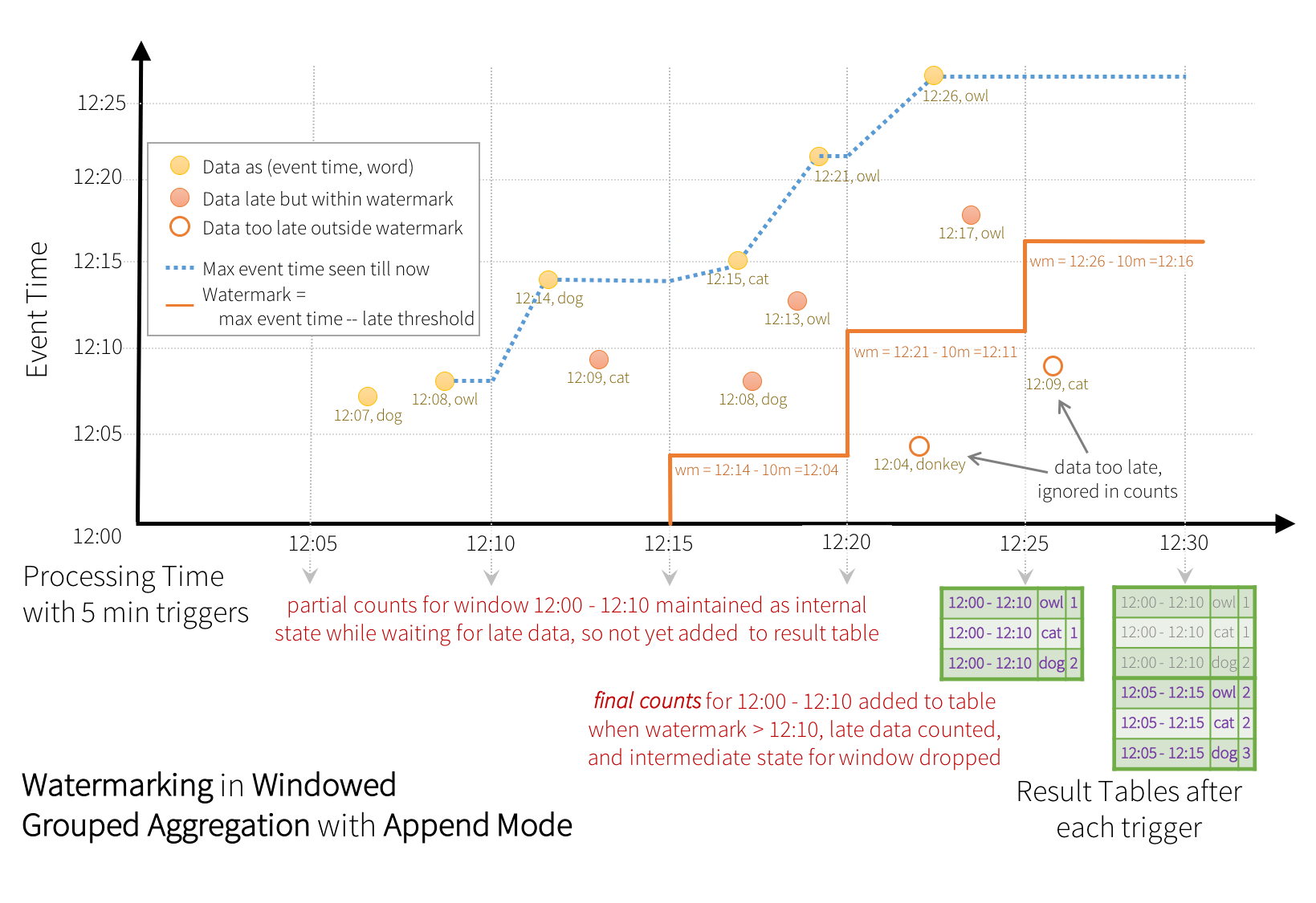
与之前的更新模式类似,引擎维护每个窗口的中间计数。 但是,部分计数不会更新到结果表,也不会写入接收器。 引擎等待“10分钟”以计算延迟日期,然后丢弃窗口<水印的中间状态,并将最终计数附加到 Table/sink。 例如,仅在水印更新为12:11后,窗口12:00 - 12:10的最终计数才会附加到结果表中。
用于清除聚合状态的水印的条件
重要的是要注意,在聚合查询中清除状态的水印必须满足以下条件(从Spark 2.1.1开始,将来可能会有变化)。
-
输出模式必须为 Append 或 Update。 Complete模式 要求保留所有聚合数据,因此不能使用水印来降低中间状态。 有关每种输出模式语义的详细说明,请参见“输出模式”部分。
-
聚合必须具有事件时间列或事件时间列上的窗口。
-
必须在与聚合中使用的时间戳列相同的列上调用withWatermark。 例如
df.withWatermark("time", "1 min").groupBy("time2).count()在Append输出模式中无效,因为水印是在与聚合列不同的列上定义的。 -
必须在聚合之前调用withWatermark才能使用水印细节。 例如,
df.groupBy("time").count().withWatermark("time", "1 min")在 Append 输出模式下无效。
带水印聚合的语义保证
-
水印延迟(使用withWatermark设置)为 “2 hours” 可确保引擎永远不会丢弃任何延迟小于2小时的数据。 换句话说,任何不到2小时(在事件时间方面)的数据都保证汇总到那时处理的最新数据。
-
但是,保证只在一个方向严格。 延迟2小时以上的数据不能保证被丢弃; 它可能会也可能不会聚合。 更多延迟的是数据,引擎进行处理的可能性较小。
Join Operations
结构化流支持将流式 Dataset/DataFrame 与静态 Dataset/DataFrame 以及另一个流式 Dataset/DataFrame 连接起来。 流连接的结果以递增方式生成,类似于上一节中的流聚合的结果。 在本节中,我们将探讨在上述情况下支持哪种类型的连接(即内部,外部等)。 请注意,在所有受支持的连接类型中,与流式 Dataset/DataFrame 的连接结果与使用包含流中相同数据的静态 Dataset/DataFrame 的结果完全相同。
Stream-static Joins
自Spark 2.0引入以来,Structured Streaming 支持流和静态 DataFrame/Dataset 之间的连接(内连接和某种类型的外连接)。 这是一个简单的例子。
val staticDf = spark.read. ...
val streamingDf = spark.readStream. ...
streamingDf.join(staticDf, "type") // inner equi-join with a static DF
streamingDf.join(staticDf, "type", "right_join") // right outer join with a static DF
请注意,流静态连接不是有状态的,因此不需要进行状态管理。 但是,尚不支持几种类型的流静态外连接。 这些列在此加入部分的末尾。
Stream-stream Joins
在Spark 2.3中,我们添加了对流 - 流连接的支持,也就是说,您可以加入两个流 Datasets/DataFrames。 在两个数据流之间生成连接结果的挑战是,在任何时间点,数据集的视图对于连接的两侧都是不完整的,这使得在输入之间找到匹配更加困难。 从一个输入流接收的任何行都可以与来自另一个输入流的任何未来的,尚未接收的行匹配。 因此,对于两个输入流,我们将过去的输入缓冲为流状态,以便我们可以将每个未来输入与过去的输入相匹配,从而生成连接结果。 此外,类似于流聚合,我们自动处理迟到的无序数据,并可以使用水印限制状态。 让我们讨论不同类型的受支持的流 - 流连接以及如何使用它们。
Inner Joins with optional Watermarking
支持任何类型的列上的内连接以及任何类型的连接条件。 但是,当流运行时,流状态的大小将无限增长,因为必须保存所有过去的输入,因为任何新输入都可以与过去的任何输入匹配。 为了避免无界状态,您必须定义其他连接条件,以便无限期旧输入无法与将来的输入匹配,因此可以从状态清除。 换句话说,您必须在连接中执行以下附加步骤。
- 定义两个输入上的水印延迟,以便引擎知道输入的延迟时间(类似于流聚合)
- 在两个输入上定义事件时间的约束,使得引擎可以确定何时不需要一个输入的旧行(即,将不满足时间约束)与另一个输入匹配。 可以用两种方式之一定义该约束。
- 时间范围连接条件 (e.g. …JOIN ON leftTime BETWEEN rightTime AND rightTime + INTERVAL 1 HOUR),
- 加入事件时间窗口 (e.g. …JOIN ON leftTimeWindow = rightTimeWindow).
让我们通过一个例子来理解这一点。
假设我们希望加入一系列广告展示次数(展示广告时),并在广告中添加另一个用户点击流,以便在展示次数达到可获利的点击时进行关联。 要在此流 - 流连接中允许状态清理,您必须指定水印延迟和时间约束,如下所示。
- 水印延迟(Watermark delays):比如说,展示次数和相应的点击次数可以分别在事件时间内延迟/无序,最多2个小时和3个小时。
- 事件时间范围条件:假设,在相应的印记后0秒到1小时的时间范围内可能发生点击事件。
代码看起来像这样。
import org.apache.spark.sql.functions.expr
val impressions = spark.readStream. ...
val clicks = spark.readStream. ...
// Apply watermarks on event-time columns
val impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
val clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
// Join with event-time constraints
impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
""")
)
具有水印的流 inner join 的语义保证
这类似于通过聚合水印提供的保证。 水印延迟 “2 hours” 可确保引擎永远不会丢失任何延迟小于2小时的数据。 但延迟2小时以上的数据可能会或可能不会得到处理。
Outer Joins with Watermarking
虽然水印+事件时间约束对于内连接是可选的,但对于左外连接和右外连接,必须指定它们。 这是因为为了在外连接中生成NULL结果,引擎必须知道输入行何时不会与将来的任何内容匹配。 因此,必须指定水印+事件时间约束以生成正确的结果。 因此,使用外部联接的查询看起来与之前的广告货币化示例非常相似,只是会有一个附加参数将其指定为外部联接。
impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
"""),
joinType = "leftOuter" // can be "inner", "leftOuter", "rightOuter"
)
具有水印的流 - 流外连接的语义保证
外连接与内部连接 inner joins具有相同的保证,关于水印延迟以及数据是否会被丢弃。
注意事项
关于如何生成外部结果,有一些重要的特征需要注意。
-
将生成外部NULL结果,延迟取决于指定的水印延迟和时间范围条件。 这是因为引擎必须等待那么长时间以确保没有匹配,并且将来不会再有匹配。
-
在微批量引擎的当前实现中,水印在微批次结束时前进,并且下一个微批次使用更新的水印来清理状态并输出外部结果。 由于我们仅在存在要处理的新数据时才触发微批处理,因此如果在流中没有接收到新数据,则外部结果的生成可能会延迟。 简而言之,如果连接的两个输入流中的任何一个在一段时间内没有接收到数据,则外部(两种情况,左侧或右侧)输出可能会延迟。
支持流式查询中的连接矩阵
| Left Input | Right Input | Join Type | _ |
|---|---|---|---|
| Static | Static | 所有类型 | 支持,因为它不在流数据上,即使它可以存在于流式查询中 |
| Stream | Static | Inner | 支持,而不是有状态 |
| Stream | Static | Left Outer | 支持,而不是有状态 |
| Stream | Static | Right Outer | 不支持 |
| Stream | Static | Full Outer | 不支持 |
| Static | Stream | Inner | 支持,而不是有状态 |
| Static | Stream | Left Outer | 不支持 |
| Static | Stream | Right Outer | 支持,而不是有状态 |
| Static | Stream | Full Outer | 不支持 |
| Stream | Stream | Inner | 支持,可选择在两侧指定水印+状态清理的时间限制 |
| Stream | Stream | Left Outer | 有条件支持,必须在正确+时间约束上指定水印以获得正确的结果,可选择在左侧指定水印以进行所有状态清理 |
| Stream | Stream | Right Outer | 有条件支持,必须在左侧指定水印+时间约束以获得正确结果,可选择在右侧指定水印以进行所有状态清理 |
| Stream | Stream | Full Outer | 不支持 |
有关支持的连接的其他详细信息
- 连接可以级联,也就是说,你可以做
df1.join(df2, ...).join(df3, ...).join(df4, ....). - 从Spark 2.3开始,只有在查询处于追加输出模式时才能使用连接。 其他输出模式尚不支持。
- 从Spark 2.3开始,在连接之前不能使用其他非类似地图的操作。 以下是一些不能使用的例子。
- 在加入之前无法使用流聚合。
- 在连接之前,无法在更新模式下使用 mapGroupsWithState 和 flatMapGroupsWithState。
流重复数据删除
您可以使用事件中的唯一标识符对数据流中的记录进行重复数据删除。 这与使用唯一标识符列的静态重复数据删除完全相同。 该查询将存储来自先前记录的必要数据量,以便它可以过滤重复记录。 与聚合类似,您可以使用带或不带水印的重复数据删除。
-
使用水印 - 如果重复记录的到达时间有上限,则可以在事件时间列上定义水印,并使用guid和事件时间列进行重复数据删除。 该查询将使用水印从过去的记录中删除旧的状态数据,这些记录不会再被重复。 这限制了查询必须维护的状态量。
-
没有水印 - 由于重复记录可能到达时没有界限,查询将来自所有过去记录的数据存储为状态。
val streamingDf = spark.readStream. ... // columns: guid, eventTime, ...
// Without watermark using guid column
streamingDf.dropDuplicates("guid")
// With watermark using guid and eventTime columns
streamingDf
.withWatermark("eventTime", "10 seconds")
.dropDuplicates("guid", "eventTime")
处理多个 watermarks 的策略
流式查询可以具有多个联合或连接在一起的输入流。 每个输入流可以具有不同的延迟数据阈值,这些阈值需要被容忍用于有状态操作。 您可以在每个输入流上使用 withWatermarks(“eventTime”, delay) 指定这些阈值。 例如,考虑在inputStream1和inputStream2之间使用流 - 流连接的查询。
inputStream1.withWatermark(“eventTime1”, “1 hour”) .join( inputStream2.withWatermark(“eventTime2”, “2 hours”), joinCondition)
在执行查询时,Structured Streaming 单独跟踪每个输入流中看到的最大事件时间,根据相应的延迟计算水印,并选择单个全局水印用于有状态操作。 默认情况下,选择最小值作为全局水印,因为它确保如果其中一个流落后于其他流(例如,其中一个流因上游故障而停止接收数据),则不会意外丢弃数据。 换句话说,全局水印将以最慢流的速度安全地移动,并且查询输出将相应地延迟。
但是,在某些情况下,您可能希望获得更快的结果,即使这意味着从最慢的流中删除数据。 从Spark 2.4开始,您可以通过将SQL配置 spark.sql.streaming.multipleWatermarkPolicy 设置为max(默认为min)来设置多水印策略以选择最大值作为全局水印。 这使得全局水印以最快的速度发展。 但是,作为副作用,来自较慢流的数据将被积极地丢弃。 因此,明智地使用此配置。
任意有状态的 Operations
许多用例需要比聚合更高级的有状态操作。 例如,在许多用例中,您必须从事件的数据流中跟踪会话。 要进行此类会话,您必须将任意类型的数据保存为状态,并使用每个触发器中的数据流事件对状态执行任意操作。 从Spark 2.2开始,这可以使用操作 mapGroupsWithState 和更强大的操作 flatMapGroupsWithState 来完成。 这两个操作都允许您在分组数据集上应用用户定义的代码以更新用户定义的状态。 有关更具体的详细信息,请查看API文档(Scala/Java)和示例(Scala/Java)。
不支持的 Operations
流式 DataFrame/Dataset 不支持一些 DataFrame/Dataset 操作。 其中一些如下。
* 流数据集上尚不支持多个流聚合(即,流DF上的聚合链)。
* 流数据集不支持限制和获取前N行。
* 不支持对流数据集进行不同的操作。
* 仅在聚合和完全输出模式之后,流数据集才支持排序操作。
* 不支持流数据集上的几种外连接类型。 有关详细信息,请参阅连接操作部分中的支持矩阵。
此外,有一些数据集方法不适用于流数据集。 它们是立即运行查询并返回结果的操作,这对流式数据集没有意义。 相反,这些功能可以通过显式启动流式查询来完成(请参阅下一节)。
count()- 无法从流数据集返回单个计数。 相反,使用 ds.groupBy().count() 返回包含运行计数的流数据集。foreach()- 而是使用 ds.writeStream.foreach(…)(参见下一节)。show()- 而是使用控制台接收器(参见下一节)。
如果您尝试这些操作中的任何一个,您将看到一个AnalysisException,例如“operation XYZ is not supported with streaming DataFrames/Datasets”。 虽然其中一些可能在未来的Spark版本中得到支持,但还有一些基本上难以有效地实现流数据。 例如,不支持对输入流进行排序,因为它需要跟踪流中接收的所有数据。 因此,这基本上难以有效执行。
启动流式查询
一旦定义了最终结果 DataFrame/Dataset,剩下的就是开始流式计算。 为此,您必须使用通过 Dataset.writeStream() 返回的 DataStreamWriter(Scala/Java/Python文档)。您必须在此界面中指定以下一项或多项。
- 输出接收器的详细信息:数据格式,位置等。
- 输出模式 Output mode:指定写入输出接收器的内容。
- 查询名称 Query name:可选地,指定查询的唯一名称以进行标识。
- 触发间隔 Trigger interval:可选择指定触发间隔。 如果未指定,则系统将在前一处理完成后立即检查新数据的可用性。 如果由于先前的处理尚未完成而错过了触发时间,则系统将立即触发处理。
- 检查点位置:对于可以保证端到端容错的某些输出接收器,请指定系统写入所有检查点信息的位置。 这应该是与HDFS兼容的容错文件系统中的目录。 检查点的语义将在下一节中详细讨论。
Output Modes
有几种类型的输出模式。
-
Append mode (default) - 这是默认模式,其中只有自上次触发后添加到结果表的新行将输出到接收器。 仅支持那些添加到结果表中的行永远不会更改的查询。 因此,此模式保证每行仅输出一次(假设容错接收器)。 例如,仅使用select, where, map, flatMap, filter, join等的查询将支持 Append 模式。
-
Complete mode - 每次触发后,整个结果表将输出到接收器。 聚合查询支持此功能。
-
Update mode - (自Spark 2.1.1起可用)仅将结果表中自上次触发后更新的行输出到接收器。 在将来的版本中添加更多信息。
不同类型的流式查询支持不同的输出模式。 这是兼容性矩阵。
- Queries with aggregation
-
Aggregation on event-time with watermark
- Supported Output Modes: Append, Update, Complete
- Notes
- 追加模式使用水印来删除旧的聚合状态。 但是窗口化聚合的输出延迟了
withWatermark()中指定的后期阈值,如模式语义,行可以在最终确定之后(即在超过水印之后)添加到结果表中一次。 有关详细信息,请参阅迟到数据部分 - 更新模式使用水印来删除旧的聚合状态。
- 完成模式不会丢弃旧的聚合状态,因为根据定义,此模式会保留结果表中的所有数据。
- 追加模式使用水印来删除旧的聚合状态。 但是窗口化聚合的输出延迟了
-
Other aggregations:
- Supported Output Modes: Complete, Update
- Notes
- 由于未定义水印(仅在其他类别中定义),因此不会丢弃旧的聚合状态。
- 不支持追加模式,因为聚合可以更新,因此违反了此模式的语义。
-
Queries with mapGroupsWithState
- Supported Output Modes: Update
-
Queries with flatMapGroupsWithState
-
Append operation mode
- Supported Output Modes: Append
- Notes
- flatMapGroupsWithState之后允许聚合。
-
Update operation mode
- Supported Output Modes: Update
- Notes
- flatMapGroupsWithState之后不允许聚合。
-
Queries with joins
- Supported Output Modes: Append
- Notes
- 尚不支持 Update 和 Complete模式。 有关支持哪种类型的连接的详细信息,请参阅连接操作部分中的支持列表。
-
Other queries
- Supported Output Modes: Append, Update
- Notes
- 不支持 Complete 模式,因为在结果表中保留所有未聚合数据是不可行的。
Output Sinks
有几种类型的内置输出接收器。
- 文件接收器(File sink) - 将输出存储到目录。
writeStream
.format("parquet") // can be "orc", "json", "csv", etc.
.option("path", "path/to/destination/dir")
.start()
- Kafka sink - 将输出存储到 Kafka 中的一个或多个主题。
writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "updates")
.start()
- Foreach接收器 - 对输出中的记录运行任意计算。 有关详细信息,请参阅本节后面的内容。
writeStream
.foreach(...)
.start()
- Console sink (for debugging) - 每次触发时都会将输出打印到控制台/标准输出。 支持Append和Complete输出模式。 这应该用于低数据量的调试目的,因为在每次触发后收集整个输出并将其存储在驱动程序的内存中。
writeStream
.format("console")
.start()
- Memory sink (for debugging) - 输出作为内存表存储在内存中。 支持Append和Complete输出模式。 这应该用于低数据量的调试目的,因为整个输出被收集并存储在驱动程序的内存中。 因此,请谨慎使用。
writeStream
.format("memory")
.queryName("tableName")
.start()
某些接收器不具有容错能力,因为它们不保证输出的持久性,仅用于调试目的。 请参阅前面的容错语义部分。 以下是Spark中所有接收器的详细信息。
-
File Sink
-
Kafka Sink
-
Foreach Sink
- Supported Output Modes: Append, Update, Complete
- Options
- None
- Fault-tolerant:取决于ForeachWriter的实现
- Notes:
- 更多细节将在下一节中介绍
-
ForeachBatch Sink
- Supported Output Modes: Append, Update, Complete
- Options
- None
- Fault-tolerant:取决于实施
- Notes:
- 更多细节将在下一节中介绍
-
Console Sink
- Supported Output Modes: Append, Update, Complete
- Options
numRows:每个触发器打印的行数(默认值:20)truncate:是否过长时截断输出(默认值:true)
- Fault-tolerant:No
- Notes:
-
Memory Sink
- Supported Output Modes: Append, Complete
- Options
- None
- Fault-tolerant:不可以。但在完整模式下,重启查询将创建完整表。
- Notes:
- 表名是查询名称。
请注意,您必须调用 start() 来实际开始执行查询。 这将返回一个 StreamingQuery 对象,该对象是持续运行的执行的句柄。 您可以使用此对象来管理查询,我们将在下一小节中讨论。 现在,让我们通过几个例子来理解这一切。
// ========== DF with no aggregations ==========
val noAggDF = deviceDataDf.select("device").where("signal > 10")
// Print new data to console
noAggDF
.writeStream
.format("console")
.start()
// Write new data to Parquet files
noAggDF
.writeStream
.format("parquet")
.option("checkpointLocation", "path/to/checkpoint/dir")
.option("path", "path/to/destination/dir")
.start()
// ========== DF with aggregation ==========
val aggDF = df.groupBy("device").count()
// Print updated aggregations to console
aggDF
.writeStream
.outputMode("complete")
.format("console")
.start()
// Have all the aggregates in an in-memory table
aggDF
.writeStream
.queryName("aggregates") // this query name will be the table name
.outputMode("complete")
.format("memory")
.start()
spark.sql("select * from aggregates").show() // interactively query in-memory table
Using Foreach and ForeachBatch
foreach 和 foreachBatch操作允许您在流式查询的输出上应用任意操作和编写逻辑。 它们的用例略有不同 - 虽然foreach允许每行自定义写入逻辑,foreachBatch允许在每个微批量的输出上进行任意操作和自定义逻辑。 让我们更详细地了解他们的用法。
ForeachBatch
foreachBatch(…) 允许您指定在流式查询的每个微批次的输出数据上执行的函数。 从Spark 2.4开始,Scala,Java和Python都支持它。 它需要两个参数:DataFrame 或 Dataset,它具有微批次的输出数据和微批次的唯一ID。
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
// Transform and write batchDF
}.start()
使用foreachBatch,您可以执行以下操作。
-
重用现有的批处理数据源 - 对于许多存储系统,可能还没有可用的流式接收器,但可能已经存在用于批量查询的数据写入器。使用foreachBatch,您可以在每个微批次的输出上使用批处理数据编写器。
-
写入多个位置 - 如果要将流式查询的输出写入多个位置,则可以简单地多次写入输出 DataFrame/Dataset 。但是,每次写入尝试都会导致重新计算输出数据(包括可能重新读取输入数据)。要避免重新计算,您应该缓存输出 DataFrame/Dataset,将其写入多个位置,然后 uncache 。这是一个大纲。
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.persist()
batchDF.write.format(…).save(…)
// location 1 batchDF.write.format(…).save(…)
// location 2 batchDF.unpersist()
}
- 应用其他DataFrame操作 - 流式 DataFrame 中不支持许多 DataFrame 和 Dataset 操作,因为Spark不支持在这些情况下生成增量计划。 使用 foreachBatch,您可以在每个微批输出上应用其中一些操作。 但是,您必须自己解释执行该操作的端到端语义。
注意:
- 默认情况下,foreachBatch仅提供至少一次写保证。 但是,您可以使用提供给该函数的batchId作为重复数据删除输出并获得一次性保证的方法。
- foreachBatch不适用于连续处理模式,因为它从根本上依赖于流式查询的微批量执行。 如果以连续模式写入数据,请改用foreach。
Foreach
如果foreachBatch不是一个选项(例如,相应的批处理数据写入器不存在,或连续处理模式),那么您可以使用foreach表达自定义编写器逻辑。 具体来说,您可以通过将数据划分为三种方法来表达数据写入逻辑:打开,处理和关闭。 从Spark 2.4开始,foreach可用于Scala,Java和Python。
在Scala中,您必须扩展ForeachWriter类(docs)。
streamingDatasetOfString.writeStream.foreach(
new ForeachWriter[String] {
def open(partitionId: Long, version: Long): Boolean = {
// Open connection
}
def process(record: String): Unit = {
// Write string to connection
}
def close(errorOrNull: Throwable): Unit = {
// Close the connection
}
}
).start()
执行语义启动流式查询时,Spark以下列方式调用函数或对象的方法:
-
此对象的单个副本负责查询中单个任务生成的所有数据。 换句话说,一个实例负责处理以分布式方式生成的数据的一个分区。
-
此对象必须是可序列化的,因为每个任务都将获得所提供对象的新的序列化反序列化副本。 因此,强烈建议在调用open()方法之后完成用于写入数据的任何初始化(例如,打开连接或启动事务),这表示任务已准备好生成数据。
-
方法的生命周期如下:
- 对于partition_id的每个分区:
- 对于 epoch_id 的流数据的每个批次/纪元(batch/epoch):
- 方法 open(partitionId, epochId) 被调用。
- 如果 open(…) 返回true,则对于分区和 batch/epoch 中的每一行,都会调用方法 process(row) 。
- 调用方法 close(error) ,在处理 rows 时看到错误(如果有)。
- 对于 epoch_id 的流数据的每个批次/纪元(batch/epoch):
- 对于partition_id的每个分区:
-
如果 open() 方法存在并且成功返回(不管返回值),则调用 close() 方法(如果存在),除非JVM或Python进程在中间崩溃。
-
注意: 当失败导致某些输入数据的重新处理时,open() 方法中的partitionId和epochId可用于对生成的数据进行重复数据删除。 这取决于查询的执行模式。 如果以微批处理模式执行流式查询,则保证由唯一元组(partition_id, epoch_id)表示的每个分区具有相同的数据。 因此,(partition_id, epoch_id) 可用于对数据进行重复数据删除和/或事务提交,并实现一次性保证。 但是,如果正在以连续模式执行流式查询,则此保证不成立,因此不应用于重复数据删除。
触发器 (Triggers)
流式查询的触发器设置定义了流式数据处理的时间,查询是作为具有固定批处理间隔的微批量查询还是作为连续处理查询来执行。 以下是支持的各种触发器。
-
Trigger Type: unspecified (default)
如果未明确指定触发设置,则默认情况下,查询将以微批处理模式执行,一旦前一个微批处理完成处理,将立即生成微批处理。 -
Fixed interval micro-batches(固定间隔微批次)
查询将以微批处理模式执行,其中微批处理将以用户指定的间隔启动。- 如果先前的微批次在该间隔内完成,则引擎将等待该间隔结束,然后开始下一个微批次。
- 如果前一个微批次需要的时间长于完成的间隔(即如果错过了间隔边界),则下一个微批次将在前一个完成后立即开始(即,它不会等待下一个间隔边界))。
- 如果没有可用的新数据,则不会启动微批次。
-
One-time micro-batch(一次性微批次)
查询将执行仅一个微批处理所有可用数据,然后自行停止。 这在您希望定期启动集群,处理自上一个时间段以来可用的所有内容,然后关闭集群的方案中非常有用。 在某些情况下,这可能会显着节省成本。 -
Continuous with fixed checkpoint interval (experimental)
连续固定检查点间隔 (实验)
查询将以新的低延迟,连续处理模式执行。 在下面的连续处理部分中阅读更多相关信息。
以下是一些代码示例。
import org.apache.spark.sql.streaming.Trigger
// Default trigger (runs micro-batch as soon as it can)
df.writeStream
.format("console")
.start()
// ProcessingTime trigger with two-seconds micro-batch interval
df.writeStream
.format("console")
.trigger(Trigger.ProcessingTime("2 seconds"))
.start()
// One-time trigger
df.writeStream
.format("console")
.trigger(Trigger.Once())
.start()
// Continuous trigger with one-second checkpointing interval
df.writeStream
.format("console")
.trigger(Trigger.Continuous("1 second"))
.start()
Managing Streaming Queries (管理流式查询)
启动查询时创建的 StreamingQuery 对象可用于监视和管理查询。
val query = df.writeStream.format("console").start() // get the query object
query.id // 获取从检查点数据重新启动后持续存在的运行查询的唯一标识符
query.runId // 获取此运行查询的唯一ID,该ID将在每次启动/重新启动时生成
query.name // 获取自动生成或用户指定名称的名称
query.explain() // 打印查询的详细说明
query.stop() // 停止查询
query.awaitTermination() // 阻塞,直到查询终止,带有stop()或出错
query.exception // 如果查询已因错误而终止,则为异常
query.recentProgress // 此查询的最新进度更新数组
query.lastProgress // 此流式查询的最新进度更新
您可以在单个SparkSession中启动任意数量的查询。 它们将同时运行,共享群集资源。 您可以使用 sparkSession.streams() 来获取可用于管理当前活动查询的 StreamingQueryManager (Scala/Java/Python docs) 。
val spark: SparkSession = ...
spark.streams.active // 获取当前活动的流式查询列表
spark.streams.get(id) // 通过其唯一ID获取查询对象
spark.streams.awaitAnyTermination() // 阻止,直到其中任何一个终止
监视流式查询(Monitoring Streaming Queries)
有多种方法可以监控活动的流式查询。 您可以使用Spark的Dropwizard Metrics支持将指标推送到外部系统,也可以通过编程方式访问它们。
以交互方式读取监测指标 (Reading Metrics Interactively)
您可以使用 streamingQuery.lastProgress() 和 streamingQuery.status() 直接获取活动查询的当前状态和指标。 lastProgress() 返回 Scala 和 Java中的 StreamingQueryProgress 对象以及 Python 中具有相同字段的字典。 它包含有关在流的最后一次触发中所取得进展的所有信息- 处理了哪些数据,处理速率,延迟等等。还有 streamingQuery.recentProgress,它返回最后几个进展的数组。
此外,streamingQuery.status() 返回 Scala 和 Java 中的 StreamingQueryStatus 对象以及 Python 中具有相同字段的字典。 它提供了有关查询立即执行操作的信息 - 触发器是否处于活动状态,是否正在处理数据等。
这里有一些例子。
val query: StreamingQuery = ...
println(query.lastProgress)
/* Will print something like the following.
{
"id" : "ce011fdc-8762-4dcb-84eb-a77333e28109",
"runId" : "88e2ff94-ede0-45a8-b687-6316fbef529a",
"name" : "MyQuery",
"timestamp" : "2016-12-14T18:45:24.873Z",
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0,
"durationMs" : {
"triggerExecution" : 3,
"getOffset" : 2
},
"eventTime" : {
"watermark" : "2016-12-14T18:45:24.873Z"
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "KafkaSource[Subscribe[topic-0]]",
"startOffset" : {
"topic-0" : {
"2" : 0,
"4" : 1,
"1" : 1,
"3" : 1,
"0" : 1
}
},
"endOffset" : {
"topic-0" : {
"2" : 0,
"4" : 115,
"1" : 134,
"3" : 21,
"0" : 534
}
},
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0
} ],
"sink" : {
"description" : "MemorySink"
}
}
*/
println(query.status)
/* Will print something like the following.
{
"message" : "Waiting for data to arrive",
"isDataAvailable" : false,
"isTriggerActive" : false
}
*/
使用异步API以编程方式报告指标 (Reporting Metrics programmatically using Asynchronous APIs)
您还可以通过附加StreamingQueryListener(Scala / Java文档)异步监视与SparkSession关联的所有查询。 使用sparkSession.streams.attachListener() 附加自定义 StreamingQueryListener 对象后,将在启动和停止查询以及活动查询中取得进展时获得回调。 这是一个例子,
val spark: SparkSession = ...
spark.streams.addListener(new StreamingQueryListener() {
override def onQueryStarted(queryStarted: QueryStartedEvent): Unit = {
println("Query started: " + queryStarted.id)
}
override def onQueryTerminated(queryTerminated: QueryTerminatedEvent): Unit = {
println("Query terminated: " + queryTerminated.id)
}
override def onQueryProgress(queryProgress: QueryProgressEvent): Unit = {
println("Query made progress: " + queryProgress.progress)
}
})
使用Dropwizard报告指标
Spark支持使用 Dropwizard 库报告指标。 要同时报告结构化流式查询的指标,您必须在 SparkSession 中显式启用配置 spark.sql.streaming.metricsEnabled。
spark.conf.set("spark.sql.streaming.metricsEnabled", "true")
// or
spark.sql("SET spark.sql.streaming.metricsEnabled=true")
启用此配置后,在SparkSession中启动的所有查询都会通过Dropwizard将指标报告给已配置的任何接收器(例如Ganglia,Graphite,JMX等)。
通过检查点从故障中恢复
如果发生故障或故意关机,您可以恢复先前查询的先前进度和状态,并从中断处继续。 这是使用检查点和预写日志完成的。 您可以使用检查点位置配置查询,并且查询将保存所有进度信息(即,在每个触发器中处理的偏移范围)和运行的聚合(例如,快速示例中的计数)到检查点位置。 此检查点位置必须是HDFS兼容文件系统中的路径,并且可以在启动查询时设置为 DataStreamWriter 中的选项。
aggDF
.writeStream
.outputMode("complete")
.option("checkpointLocation", "path/to/HDFS/dir")
.format("memory")
.start()
流式查询中更改后的恢复语义
在从同一检查点位置重新启动之间允许对流查询进行哪些更改存在限制。 以下是一些不允许的更改,或者更改的效果未明确定义。 对于他们所有:
- 术语 “allowed” 意味着您可以执行指定的更改,但其效果的语义是否明确定义取决于查询和更改。
- 术语“not allowed”意味着您不应该执行指定的更改,因为重新启动的查询可能会因不可预测的错误而失败。
sdf表示使用sparkSession.readStream生成的流式 DataFrame/Dataset 。
变化的类型
- 输入源的数量或类型(即不同来源)的变化:这是不允许的。
- 输入源参数的更改:是否允许此更改以及更改的语义是否明确定义取决于源和查询。 这里有一些例子。
- 允许 Addition/deletion/modification 速率限制:
spark.readStream.format("kafka").option("subscribe", "topic")改为spark.readStream.format("kafka").option("subscribe", "topic").option("maxOffsetsPerTrigger", ...) - 通常不允许对订阅的主题/文件进行更改,因为结果是不可预测的:
spark.readStream.format("kafka").option("subscribe", "topic")改为spark.readStream.format("kafka").option("subscribe", "newTopic")
- 允许 Addition/deletion/modification 速率限制:
- 输出接收器类型的变化:允许几个特定接收器组合之间的变化。 这需要根据具体情况进行验证。 这里有一些例子。
- 允许 File sink 到 Kafka sink。 Kafka 只会看到新数据。
- 不允许 Kafka sink 到 File sink。
- kafka sink 改为 foreach,反之亦然。
- 输出接收器参数的变化:是否允许这种变化以及变化的语义是否明确定义取决于接收器和查询。 这里有一些例子。
- 不允许更改文件接收器的输出目录:
sdf.writeStream.format("parquet").option("path", "/somePath")改变为sdf.writeStream.format("parquet").option("path", "/anotherPath") - 允许对输出主题进行更改:
sdf.writeStream.format("kafka").option("topic", "someTopic")改变为sdf.writeStream.format("kafka").option("topic", "anotherTopic") - 允许对用户定义的 foreach 接收器(即ForeachWriter代码)进行更改,但更改的语义取决于代码。
- 不允许更改文件接收器的输出目录:
- projection/filter/类似map的operations:允许某些情况。 例如:
- 允许添加/删除过滤器:sdf.selectExpr(“a”) 改为 sdf.where(…).selectExpr(“a”).filter(…).
- 允许更改具有相同输出模式的投影:
sdf.selectExpr("stringColumn AS json").writeStream改为sdf.selectExpr("anotherStringColumn AS json").writeStream - 有条件地允许使用不同输出模式的投影更改:
sdf.selectExpr("a").writeStream改为sdf.selectExpr("b").writeStream。
仅当输出接收器允许模式从“a”更改为“b”时才允许writeStream”。
- 有状态操作的变化:流式查询中的某些操作需要维护状态数据以便不断更新结果。 结构化流自动检查状态数据到容错存储(例如,, HDFS, AWS S3, Azure Blob存储)并在重新启动后恢复它。 但是,这假设状态数据的模式在重新启动时保持相同。 这意味着在重新启动之间不允许对流式查询的有状态操作进行任何更改(即添加,删除或 schema 修改)。 以下是有状态操作的列表,在重新启动之间不应更改其 schema 以确保状态恢复:
- 流聚合:例如,sdf.groupBy(“a”).agg(…)。 不允许对分组键或聚合的数量或类型进行任何更改。
- 流式重复数据删除:例如,sdf.dropDuplicates(“a”)。 不允许对分组键或聚合的数量或类型进行任何更改。
- 流 - 流连接:例如,sdf1.join(sdf2, …)(即两个输入都是使用sparkSession.readStream生成的)。 不允许更改 schema 或等连接列。
不允许更改连接类型(外部或内部)。 连接条件的其他更改是不明确的。 - 任意有状态操作:例如, sdf.groupByKey(…).mapGroupsWithState(…) 或sdf.groupByKey(…).flatMapGroupsWithState(…)。 不允许对用户定义状态的模式和超时类型进行任何更改。 允许在用户定义的状态映射函数中进行任何更改,但更改的语义效果取决于用户定义的逻辑。 如果您确实希望支持状态模式更改,则可以使用支持模式迁移的编码/解码方案将复杂状态数据结构显式编码/解码为字节。 例如,如果将状态保存为Avro编码的字节,则可以在查询重新启动之间更改Avro状态模式,因为二进制状态将始终成功恢复。
连续处理(Continuous Processing)
[实验]
连续处理是Spark 2.3中引入的一种新的实验性流执行模式,可实现低的(~1 ms)端到端延迟,并且至少具有一次容错保证。 将其与默认的微批处理引擎相比较,该引擎可以实现一次性保证,但最多可实现~100ms的延迟。 对于某些类型的查询(在下面讨论),您可以选择执行它们的模式而无需修改应用程序逻辑(即不更改DataFrame / Dataset操作)。
要在连续处理模式下运行支持的查询,您只需指定一个continuous trigger,并将所需的检查点间隔作为参数。 例如,
import org.apache.spark.sql.streaming.Trigger
spark
.readStream
.format("rate")
.option("rowsPerSecond", "10")
.option("")
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.trigger(Trigger.Continuous("1 second")) // 只更改查询
.start()
检查点间隔为1秒意味着连续处理引擎将每秒记录查询的进度。 生成的检查点采用与微批处理引擎兼容的格式,因此可以使用任何触发器重新启动任何查询。 例如,以微批处理模式启动的支持查询可以以连续模式(continuous mode)重新启动,反之亦然。 请注意,无论何时切换到连续模式,您都将获得至少一次的容错保证。
支持的查询
从Spark 2.3开始,连续处理模式仅支持以下类型的查询。
-
Operations:在连续模式下仅支持类似 map 的 Dataset/DataFrame 操作,即仅投影(select,map,flatMap,mapPartitions等)和选择(where,filter等)。
- 除了聚合函数(因为尚不支持聚合),current_timestamp() 和 current_date()(使用时间的确定性计算具有挑战性)之外,支持所有SQL函数。
-
Sources:
- Kafka source:支持所有选项。
- Rate source:适合测试。 只有连续模式支持的选项是 numPartitions 和 rowsPerSecond。
-
Sinks:
- Kafka sink: 支持所有选项。
- Memory sink: 适合调试。
- Console sink: 适合调试。 支持所有选项。 请注意,控制台将打印您在 continuous trigger 中指定的每个检查点间隔。
有关它们的更多详细信息,请参阅输入源和输出接收器部分。 虽然控制台接收器适用于测试,但使用Kafka作为源和接收器可以最好地观察端到端低延迟处理,因为这允许引擎处理数据并使结果在输出 Topic中毫秒内可用,输入 Topic 中的输入数据开始可用。
说明(Caveats)
- 连续处理引擎启动多个长时间运行的任务,这些任务不断从源中读取数据,处理数据并连续写入接收器。 查询所需的任务数取决于查询可以并行从源读取的分区数。 因此,在开始连续处理查询之前,必须确保群集中有足够的核心并行执行所有任务。 例如,如果您正在读取具有10个分区的Kafka主题,则群集必须至少具有10个核心才能使查询取得进展。
- 停止连续处理流可能会产生虚假的任务终止警告。 这些可以安全地忽略。
- 目前没有自动重试失败的任务。 任何失败都将导致查询停止,并且需要从检查点手动重新启动。
附加信息
进一步阅读
-
- 有关如何运行Spark示例的说明
-
阅读结构化流 Kafka 集成指南中有关与Kafka集成的内容
-
阅读Spark SQL编程指南中有关使用 DataFrames/Datasets 的更多详细信息
-
第三方博客帖子
Talks
-
Spark Summit Europe 2017 (2017 欧洲 Spark 峰会)
- 简单、可扩展、容错的流处理Apache Spark中的 Structured Streaming -
Part 1 slides/video,
Part 2 slides/video - 深入了解 Structured Streaming 中的有状态流处理 - slides/video
- 简单、可扩展、容错的流处理Apache Spark中的 Structured Streaming -
-
Spark Summit 2016
- 深入了解Structured Streaming - slides/video
