本文原文出处: http://blog.csdn.net/bluishglc/article/details/80423323 严禁任何形式的转载,否则将委托CSDN官方维护权益!
模型思想
从Spark 2.0开始,Spark Streaming引入了一套新的流计算编程模型:Structured Streaming,开发这套API的主要动因是自Spark 2.0之后,以RDD为核心的API逐步升级到Dataset/DataFrame上,而另一方面,以RDD为基础的编程模型对开发人员的要求较高,需要有足够的编程背景才能胜任Spark Streaming的编程工作,而新引入的Structured Streaming模型是把数据流当作一个没有边界的数据表来对待,这样开发人员可以在流上使用Spark SQL进行流处理,这大大降低了流计算的编程门槛。
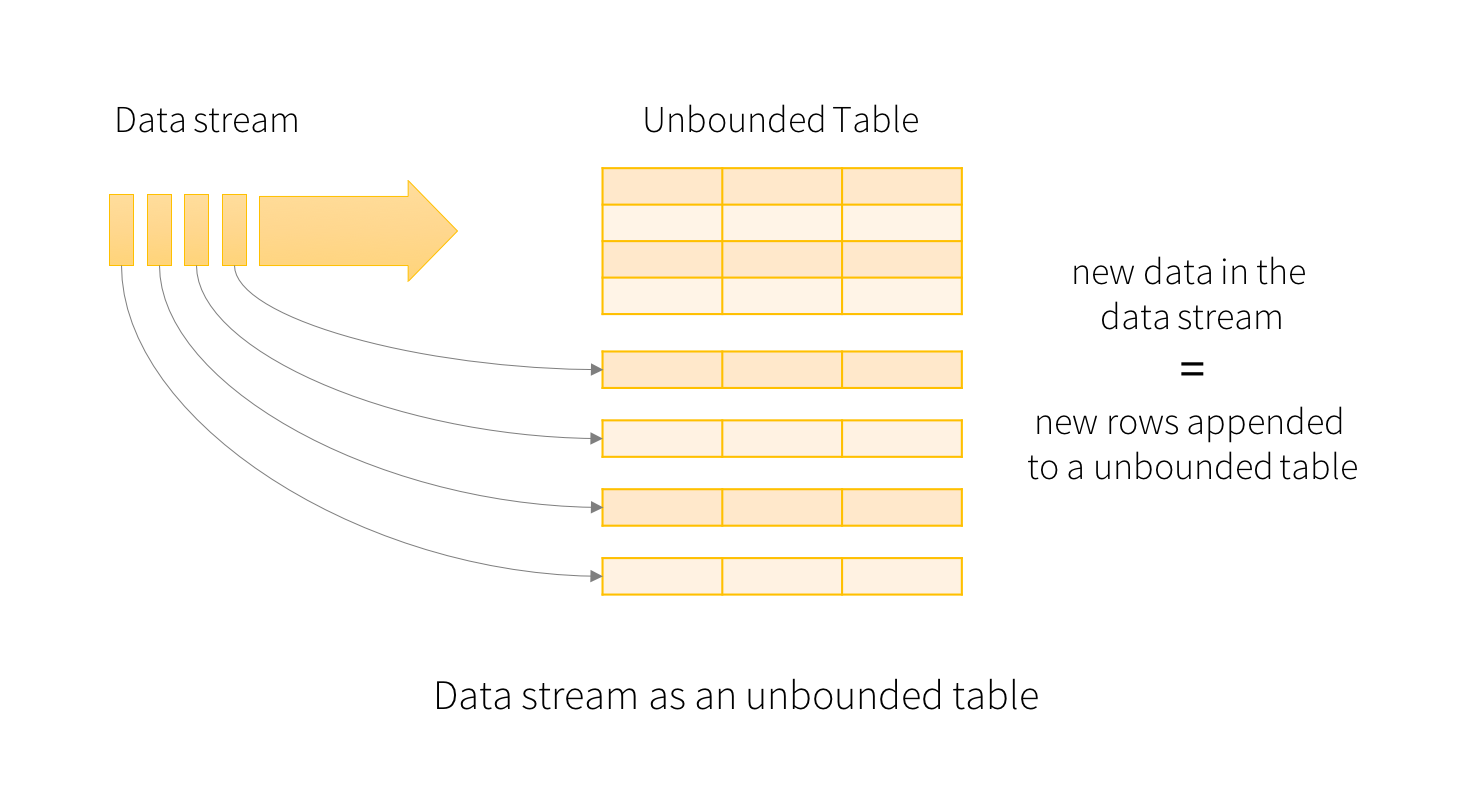
上图非常直观地解释了Structured Streaming模型的设计思想,基本无需多言。另一方面,当具备了这样一张“表”后,流的运作方式是就是在这张表上进行“查询”,并将查询的结果写到另一张结果表上,这种变换与DStream经过某个transform之后形成一个新的DStream是很类似的。我们来看一下Spark Streaming官方文档上给出的一个word count的示例:
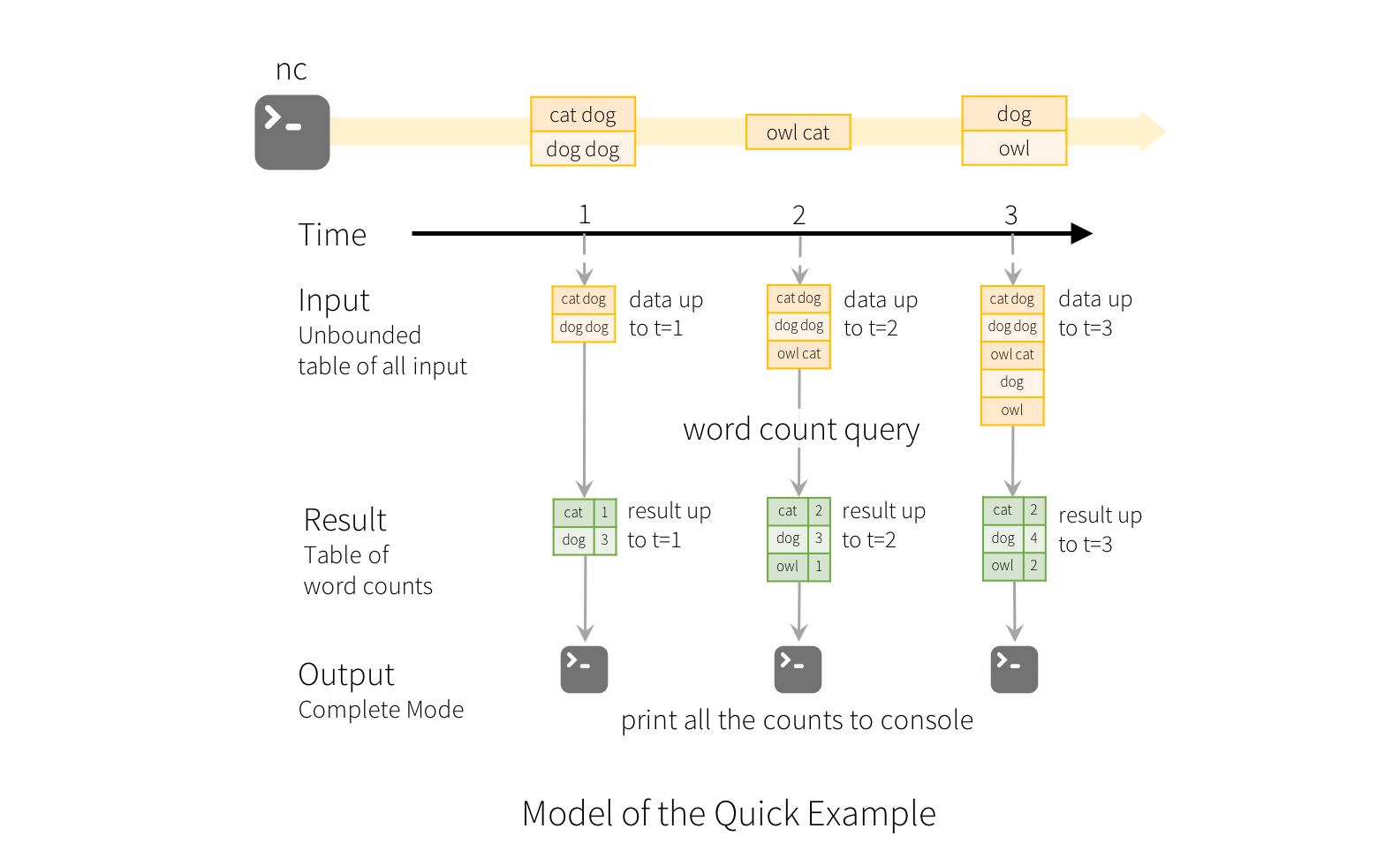
这个图直观地展示了Structured Streaming的运作方式,每次流入的文本会作为一行新数据加入到unbounded table上,然后在这个表上执行word count查询后,把统计出的word count写到结果表中并输出。
窗口操作
Structured Streaming同样支持窗口操作,同样是基于unbounded table模型来实现的,较之于DStream的窗口操作,新的API显得更加实用和强大,一个显著的改进是新的窗口运算可以基于”事件时间”(Event Time)进行计算而不在是数据进入到流上的时间(当然,这并不是说DStream不能基于事件时间进行计算,只是实现起来稍显麻烦),所谓”事件时间”是指数据所代表的事件发生时的时间,这显然更加具有实用性。同样以word count为例,下图展示了以10分钟作为window size,5分钟为slide的窗口计算过程:
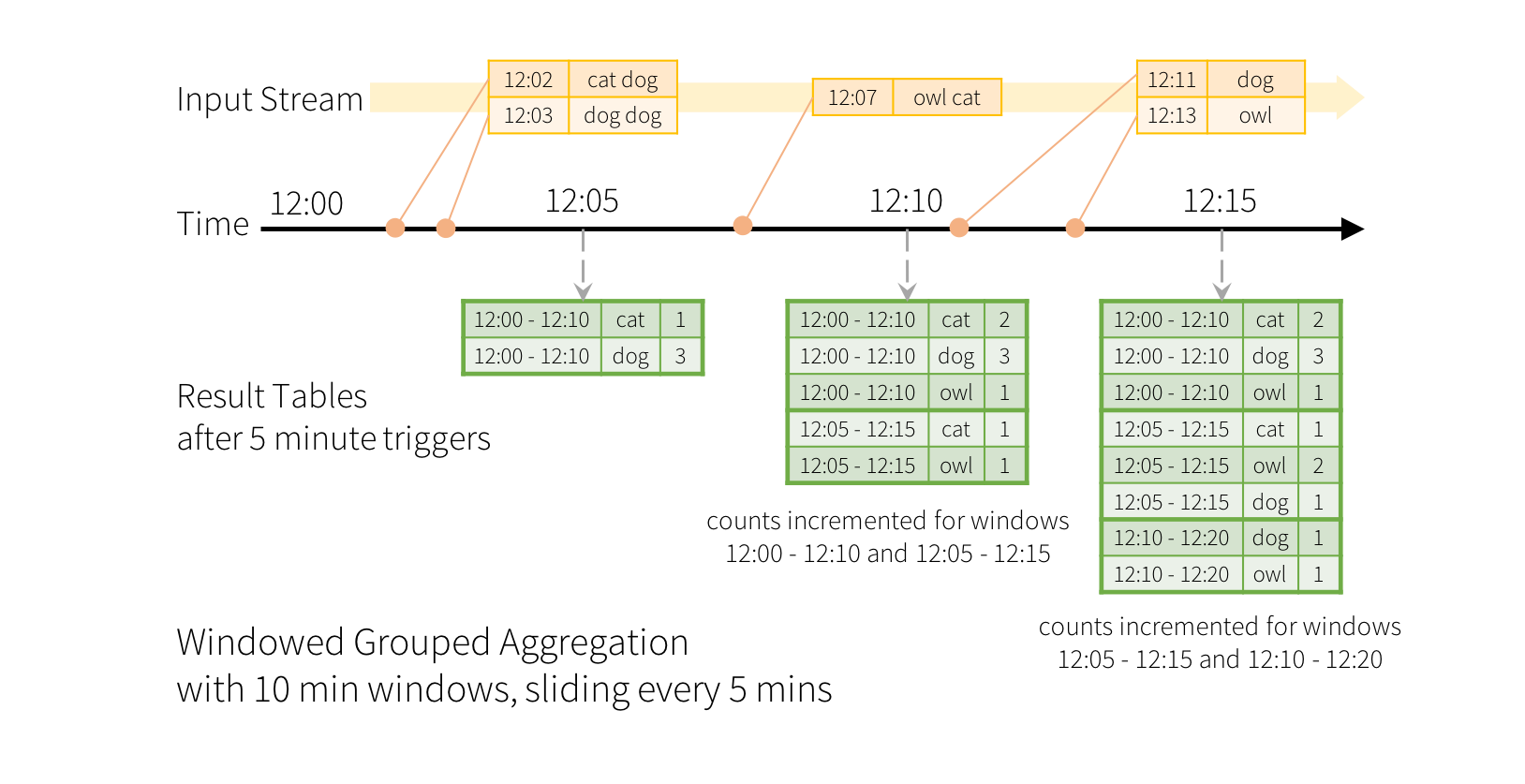
这个图形象地展示了以每行文本的时间戳为准,以10分钟为窗口尺度,统计了12:00 - 12:10, 12:05 - 12:15, 12:10 - 12:20三个时间窗口上word count值,而对应的实现代码及其地简洁:
import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word"
).count()应对数据延迟就绪
除此之外,新的API对数据延时到达也给出了一套简洁的解决方案。在很多流计算系统中,数据延迟到达的情况很常见,并且很多时候是不可控的,因为很多时候是外围系统自身问题造成的。首先,Structured Streaming可以保证一条旧的数据进入到流上时,Structured Streaming依然可以基于这些“迟到”的数据重新计算并更新计算结果,但是这样会一个问题,即需要在流上维持一个很大时间跨度的数据集,这会消耗很大的资源,同时,流计算关注的是近期数据,更新一个很早之前的状态往往已经不再具有很大的业务价值,因此Structured Streaming引入了一种叫watermarking的机制来应对这个问题。watermarking实际上就是数据的事件时间与在其流上能找到的最大事件时间的最大差值(Time-To-Live, TTL),如果这个差值超过了设定的阈值,就意味着数据太陈旧了,时效性超出了流计算应该关注的区间,不再参与计算。watermarking的定义或者说计算方法是非常有道理和有实际意义的,我们说当一组有新有旧(迟到)的数据进入到流上时,我们如何判定怎样的数据才算是太过“陈旧”的数据而不再给予关注?时间差值可以直接给出,10分钟也好,15分钟也罢,但是进行参照计算的“最新时间”怎么定呢?这里有两个可选时间:窗口的截止时间和窗口中最晚/最新的事件时间,显然后者是更加准确的,因为后者反映的是目标系统最后时刻的状态而不是当前数据流的最新状态!
我们官方文档展示的例子:
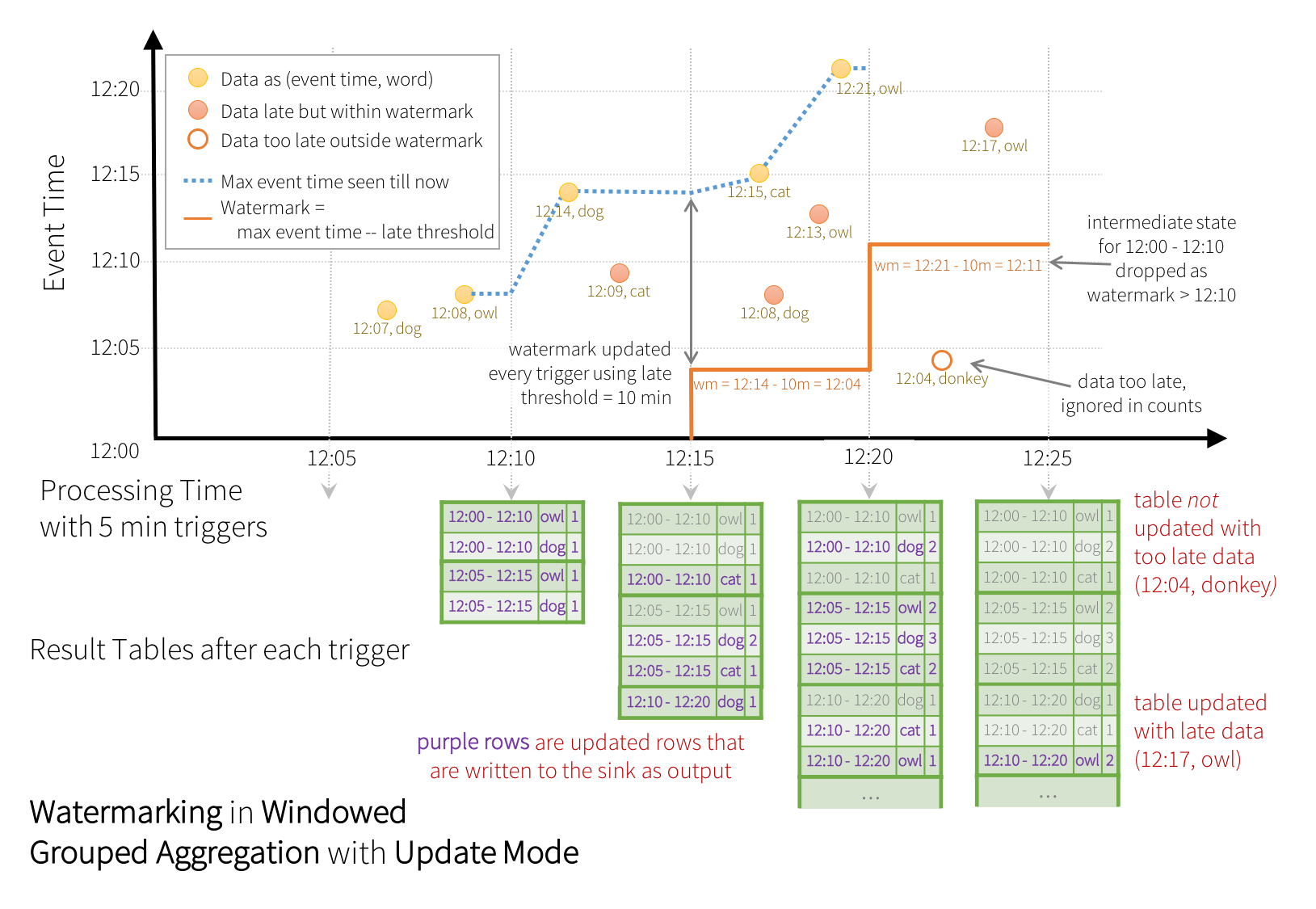
在这个图中,watermark设定为10分钟,我们先看一个延迟到达但没有超过watermark的例子:(12:09, cat) ,这个数据会最先进入12:05 - 12:15这个窗口(虽然正常情况下它在12:00-12:10这个窗口开启时就应该已经就绪了,显然它是一个迟到的数据),watermark设定为10分钟话意味着有效的事件时间可以推后到12:14 - 10m = 12:04,因为12:14是这个窗口中接收到的最晚的时间,代表目标系统最后时刻的状态,由于12:09在12:04之后,因此被视为了“虽然迟到但尚且可以接收”的数据而被更新到了结果表中,也就是(12:00 - 12:10, cat, 1)。
另一个超出watermark的例子是(12:04, dog),这个数据最早进入的窗口是12:15 - 12:25,窗口中最晚的事件时间是12:17,watermark为10分钟意味着有效的事件时间可以推后到12:07,而(12:04, dog)比这个值还要早,说明它”太旧了”,所以不会被更新到结果表中了。
同样的,在编程层面实现这些要求也是很简单的,整个Structured Streaming和Dataset/DataFrame都是声明性的:
import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words
.withWatermark("timestamp", "10 minutes")
.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word")
.count()对于基于watermarking的窗口计算的最后一个问题就是Update模式和Append模式了,两种模式的区别是:Update模式总是倾向于“尽可能早”的将处理结果更新到sink,当出现迟到数据时,早期的某个计算结果将会被更新。如果用于接收处理结果的sink不支持更新操作,则只能选择Append模式,Append模式就是推迟计算结果的输出到一个相对较晚的时刻,确保结果是稳定的,不会再被更新,比如:12:00 - 12:10窗口的处理结果会等到watermark更新到12:11之后才会写入到sink。
补充:关于Output Mode
Structured Streaming有三种输出模式:Append, Complete和Update , 它们的区别如下:
Append模式:顾名思义,既然是Append,那就意味着它每次都是添加新的行,那么也就是说:它适用且只适用于那些一旦产生计算结果便永远不会去修改的情形, 所以它能保证每一行数据只被数据一次
Complete模式:整张结果表在每次触发时都会全量输出!这显然是是要支撑那些针对数据全集进行的计算,例如:聚合
Update模式:某种意义上是和Append模式针锋相对的一个种模式,它只输出上次trigger之后,发生了“更新”的数据的,这包含新生的数据和行发生了变化的行。对于数据库类型的sink来说,这是一种理想的模式。
Structured Streaming的三种输出模式和处理数据操作类型以及Sink有密切的关系,并不是在任何情形下都可以随意使用任意一的模式,对此官方文档中给出一个表格:
| 查询类型 | 支持的模式 | 说明 | |
|---|---|---|---|
| 带聚合的查询 | 使用watermark,基于事件时间的聚合 | Append | 在此种情形下,append模式的工作方式是:超出了watermark 的聚合状态会被丢弃,但是由于是append模式,Spark必须保证聚合结果是“稳定”之后的一个最终值,所以聚合结果的输出将会被推迟到watermark关闭之后的那个时刻而不是以当前时间为终止时间的那个窗口时间。 |
| Update | 在此种情形下,update模式同样会丢弃超出了watermark 的聚合状态,并总是在第一次时间输出更新了的行!如果存在迟到数据,某一个行可能在update模式下输出多次,直到超出了watermark的规定时间 | ||
| Complete | 在此种情形下,Complete不会舍弃任何聚合状态 | ||
| 其他聚合运算 | Update,Complete | 既然没有了wartermark,那意味着我们设置一个无限长时间的warkmark,也就是说我们认为数据的有可能会无限期地延时到达,所以也就不可能有一个“确定以及稳定”的聚合状态,所以就不能以append模式输出,只能是要么每次触发时更新结果,要么每次输出全集! | |
| 带mapGroupsWithState的查询 | Update | ||
| 带flatMapGroupsWithState的查询 | Append操作模式 | Append | 在flatMapGroupsWithState之后允许聚合操作 |
| Update操作模式 | Update | 在flatMapGroupsWithState之后不允许聚合操作 | |
| 带 joins查询 | Append | ||
| 其他查询 | Append, Update |