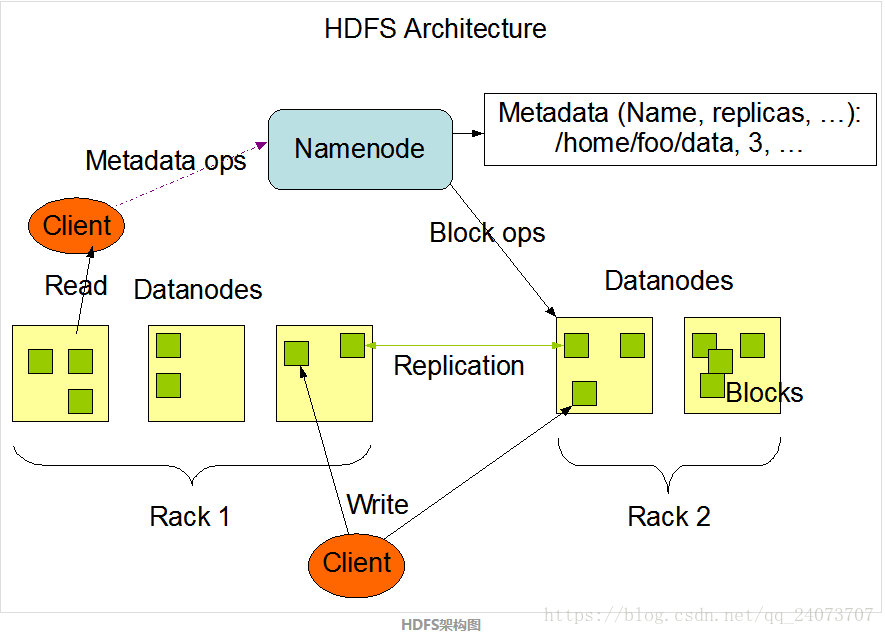
架构设计
NameNode
存储:文件系统的命名空间
- 文件名称
- 文件目录结构
- 文件的属性(权限 创建时间 副本数)
- 文件对应哪些数据块 –> 这些数据块对应哪些DataNode节点上
不会持久化存储这个映射关系,是通过集群的启动和运行时,DataNode定期发送blockReport给NameNode,以此NameNode在【内存】中动态维护这种映射关系。
作用:管理文件系统的命名空间。它维护着文件系统树及整棵树内所有的文件和目录。
这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件fsimage和编辑日志文件editlog。
DataNode
存储:数据块和数据块校验和
与Namenode通信:
- 每隔3秒发送一个心跳包
- 每十次心跳发送一次blockReport
作用(主要):读写文件的数据块
Scondary NameNode
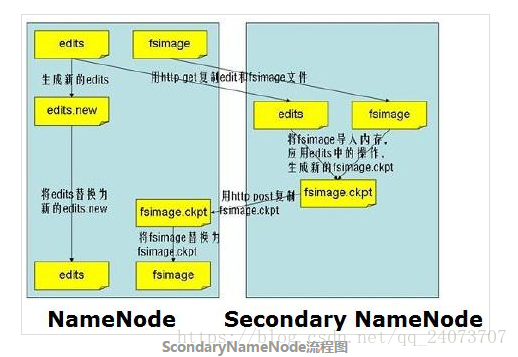
- 存储:命名空间镜像文件fsimage 和 编辑日志editlog
- 作用:定期合并fsimage+editlog文件为新的fsimage推送给namenode.俗称检查点动作,checkpoint.
- 参数:hdfs-default.xml文件
dfs.namenode.checkpoint.period: 3600 秒
副本放置策略
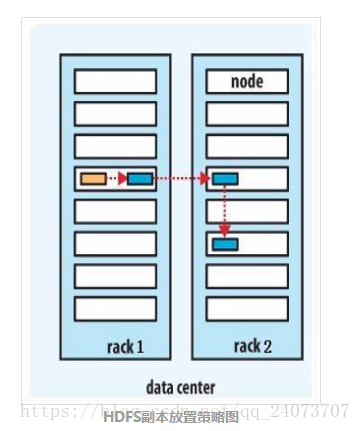
- 第一副本:放置在上传文件的DataNode上;如果是集群外提交,则随机挑选一台磁盘不太慢、CPU不太忙的节点上
- 第二副本:放置在与第一个副本不同的机架的节点上
- 第三副本:与第二个副本相同机架的不同节点上
- 如果还有更多的副本:随机放在节点中
读写流程
HDFS读流程
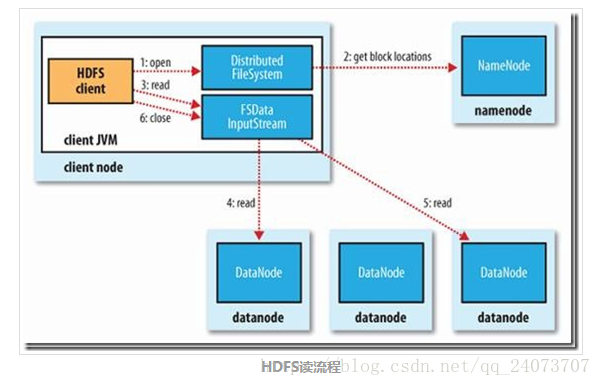
- Client通过
FileSystem.open()方法,去与NameNode进行rpc通信,返回该文件的部分或全部的block列表(也包含该列表各block的分布在Datanode地址的列表),也就是返回FSDataInputStream对象 Client调用
FSDataInputStream.read()方法- 与第一个块的最近的Datanode进行read,读取完毕后会
check,若sucessful,会关闭与当前Datanode通信;若check file,会记录失败的块和Datanode信息,下次就不会读取,那么就会去该块的第二个Datanode地址读取; - 然后去第二个块的最近的Datanode上的进行读取,check后,会关闭与此datanode的通信;
- 假如block列表读取完了,文件还未结束,那么FileSystem会从Namenode获取下一批的block的列表;
- 与第一个块的最近的Datanode进行read,读取完毕后会
Client调用
FSDataInputStream.close()方法,关闭输入流
HDFS写流程
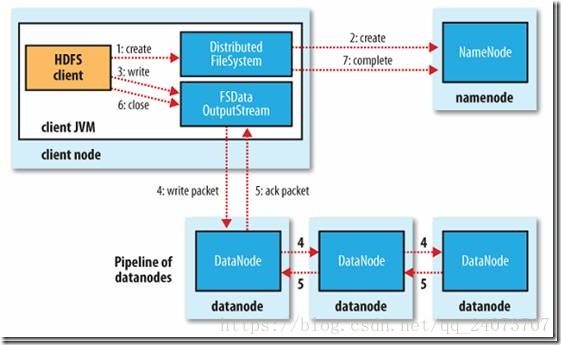
Client调用
FileSystem.create()方法,去与Namenode进行rpc通信,check该路径的文件是否存在以及有没有权限创建该文件,假如ok,就创建一个新文件,但是并不关联任何block,返回一个FSDataOutputStream对象;假如not ok,就返回错误信息,所以写代码要try-catchClient调用
FSDataOutputStream.write()方法- 将第一个块写入第一个
Datanode,第一个Datanode写完传给第二个节点,第二个写完传给第三节点,当第三个节点写完返回一个ackpacket给第二个节点,第二个返回一个ackpacket给第一个节点,第一个节点返回ackpacket给FSDataOutputStream对象,意思标识第一个块写完,副本数为3;然后剩余的块依次这样写
- 将第一个块写入第一个
当向文件写入数据完成后,Client调用
FSDataOutputStream.close()方法,关闭输出流,flush缓存区的数据包;- 再调用
FileSystem.complete()方法,告诉Namenode节点写入成功
进程
通过jps命令查看进程
NameNode SecondaryNameNode DataNode
其各自进程会生成一个对应的pid文件
常用命令
jps查看进程
[hadoop@hadoop1 ~]$ jps
54450 Jps
10611 NodeManager
5720 NameNode
6030 SecondaryNameNode
5823 DataNode
10511 ResourceManager
[hadoop@hadoop1 ~]$
[hadoop@hadoop1 ~]$ which jps
/usr/java/jdk1.8.0_45/bin/jps
[hadoop@hadoop1 ~]$
[root@hadoop1 ~]# cd /tmp/hsperfdata_hadoop/
[root@hadoop1 hsperfdata_hadoop]# ll
total 160
-rw-------. 1 hadoop hadoop 32768 Dec 17 10:11 10511
-rw-------. 1 hadoop hadoop 32768 Dec 17 10:11 10611
-rw-------. 1 hadoop hadoop 32768 Dec 17 10:11 5720
-rw-------. 1 hadoop hadoop 32768 Dec 17 10:11 5823
-rw-------. 1 hadoop hadoop 32768 Dec 17 10:11 6030
正常流程
[root@hadoop1 hsperfdata_hadoop]# jps
10611 -- process information unavailable
6325 jar
54487 Jps
5720 -- process information unavailable
6030 -- process information unavailable
5823 -- process information unavailable
10511 -- process information unavailable
[root@hadoop1 hsperfdata_hadoop]# ps -ef |greo 10611
找到该进程的使用用户名称
[root@hadoop1 hsperfdata_hadoop]# su - hadoop
[hadoop@hadoop1 ~]$ jps
10611 NodeManager
5720 NameNode
54524 Jps
6030 SecondaryNameNode
5823 DataNode
10511 ResourceManager
[hadoop@hadoop1 ~]$
异常流程
[root@hadoop1 rundeck]# jps
10611 -- process information unavailable
6325 jar
5720 -- process information unavailable
6030 -- process information unavailable
54591 Jps
5823 -- process information unavailable
10511 -- process information unavailable
[root@hadoop1 rundeck]#
[root@hadoop1 rundeck]# kill -9 10611
[root@hadoop1 rundeck]# jps
10611 -- process information unavailable
6325 jar
5720 -- process information unavailable
54605 Jps
6030 -- process information unavailable
5823 -- process information unavailable
10511 -- process information unavailable
[root@hadoop1 rundeck]# ps -ef|grep 10611
root 54618 48324 0 10:15 pts/1 00:00:00 grep 10611
[root@hadoop1 rundeck]#
10611信息残留,去/tmp/hsperfdata_hadoop文件夹删除该10611文件
[root@hadoop1 hsperfdata_hadoop]# ll
total 160
-rw-------. 1 hadoop hadoop 32768 Dec 17 10:17 10511
-rw-------. 1 hadoop hadoop 32768 Dec 17 10:15 10611
-rw-------. 1 hadoop hadoop 32768 Dec 17 10:17 5720
-rw-------. 1 hadoop hadoop 32768 Dec 17 10:17 5823
-rw-------. 1 hadoop hadoop 32768 Dec 17 10:16 6030
[root@hadoop1 hsperfdata_hadoop]# rm -f 10611
[root@hadoop1 hsperfdata_hadoop]#
[root@hadoop1 hsperfdata_hadoop]# jps
54626 Jps
6325 jar
5720 -- process information unavailable
6030 -- process information unavailable
5823 -- process information unavailable
10511 -- process information unavailable
[root@hadoop1 hsperfdata_hadoop]# su - hadoop
[hadoop@hadoop1 ~]$ jps
54661 Jps
5720 NameNode
6030 SecondaryNameNode
5823 DataNode
10511 ResourceManager
[hadoop@hadoop1 ~]$
hadoop和hdfs文件系统命令
hadoop fs 等价 hdfs dfs
[hadoop@hadoop1 hadoop]$ bin/hdfs dfs -ls /
[hadoop@hadoop1 hadoop]$ bin/hdfs dfs -mkdir -p /rzdatadir001/001
[hadoop@hadoop1 hadoop]$ bin/hdfs dfs -cat /test.log
[hadoop@hadoop1 hadoop]$ bin/hdfs dfs -put rzdata.log1 /rzdatadir001/001
[hadoop@hadoop1 hadoop]$ bin/hdfs dfs -get /rzdatadir001/001/rzdata.log1 /tmp/
[hadoop@hadoop1 hadoop]$ bin/hdfs dfs -get /rzdatadir001/001/rzdata.log1 /tmp/rzdata.log123 重命名
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
配置回收站
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
core-site.xml
fs.trash.interval : 10080
//测试
bin/hdfs dfs -rm -r -f /xxxx ---》进入回收站,是可以恢复的
bin/hdfs dfs -rm -r -f -skipTrash /xxxx ---》不进入回收站,是不可以恢复的大数据课程推荐:
