©作者 | 冯太涛
单位 | 上海理工大学
研究方向 | 概率论与数理统计
前言
RNN(循环神经网络)是一种节点定向连接成环的人工神经网络。不同于前馈神经网络,RNN 可以利用内部的记忆来处理任意时序的输入序列,即不仅学习当前时刻的信息,也会依赖之前的序列信息,所以在做语音识别、语言翻译等等有很大的优势。RNN 现在变种很多,常用的如 LSTM、Seq2SeqLSTM,还有其他变种如含有 Attention 机制的 Transformer 模型等等。这些变种原理结构看似很复杂,但其实只要有一定的数学和计算机功底,在学习的时候认认真真搞懂一个,后面的都迎刃而解。
本文将对 LSTM 里面知识做高度浓缩介绍(包括前馈推导和链式法则),然后再建立时序模型和优化模型,最后评估模型并与 ARIMA 或 ARIMA-GARCH 模型做对比。

1 RNN神经网络底层逻辑介绍
(注:下面涉及的所有模型解释图来源于百度图片)
1.1 输入层、隐藏层和输出层


▲ 图1
从上图 1,假设 是序列中第 个批量输入(这里的 是样本个数, 是样本特征维度),对应隐藏层状态为 ( 为隐藏层长度),最终输出 ( 为输出向量维度,即输出向量到底含几个元素!)。那么在计算 时刻 ,有公式:
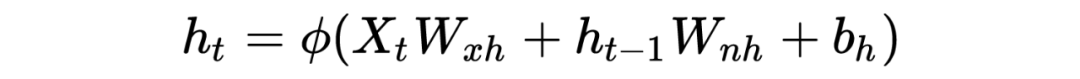
这里的 为某一特定激活函数, 为需要学习的权重, 为要学习的偏差值,那么同理输出结果为: 参数解释如上!
1.2 损失函数定义
根据误差函数性质,对于回归问题,大多数建立的是基于距离形式的均方误差函数或者绝对误差函数,如果是分类问题,我们一般会选择交叉熵这类函数!
时刻有误差 ,这里的 为真实值, 为预测值。那么整个时间长度 ,我们有 ,我们的目的就是更新所有的参数 和 使 最小。
1.3 梯度下降与链式法则求导
这里的推导比较复杂,为了让大家能理解到整个模型思想而不是存粹学术研究,只做重点介绍!且激活函数简化!
对于参数 的更新,经典的梯度下降格式为: ,根据微积分知识,我们知道链式法则公式为:若 ,那么 可以表示为链式求导过程!
现在开始推导各个函数的链式求导结果,对于任意 时刻的输出 ,由损失函数定义很容易知: ,那么对于 的更新,由 步才能到 ,求和可得:
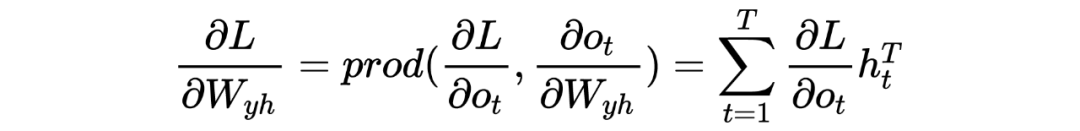
对于终端时刻 ,我们很容易有:
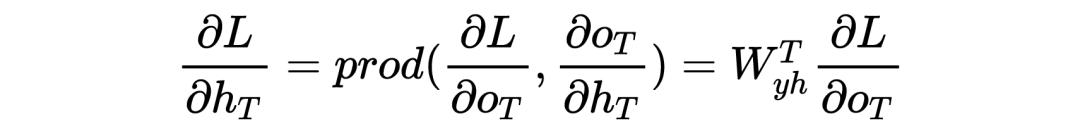
但对于 < 时刻而言,对于隐藏层的求导比较复杂,因为有个时间前后关系,所以我们有:
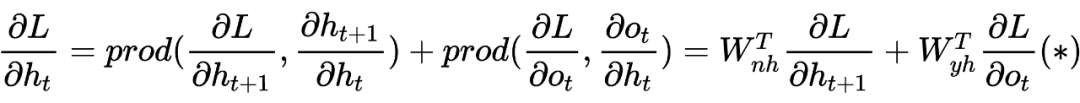
那么同理,很容易我们将解决:

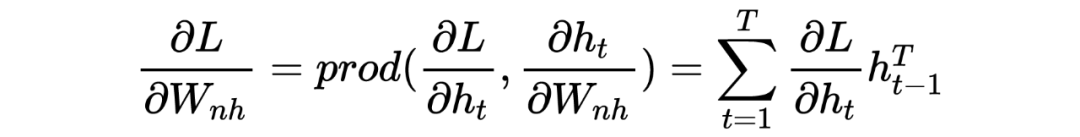
2 对于梯度消散(爆炸)的原理解释
一般 RNN 模型,会因为在链式法则中存在梯度消散(爆炸)的问题,所以我们要发展新的变种来解决这种问题,那么这梯度问题到底在哪呢?仔细发现在上一节的(*)式推导过程中,对于隐藏层求导,我们继续对(*)式改写可得:
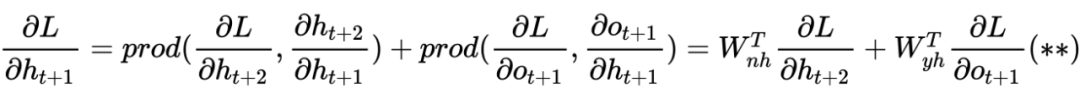
我们再对 往后推一步,然后依次推到 时刻,最终由数学归纳法很容易得到:
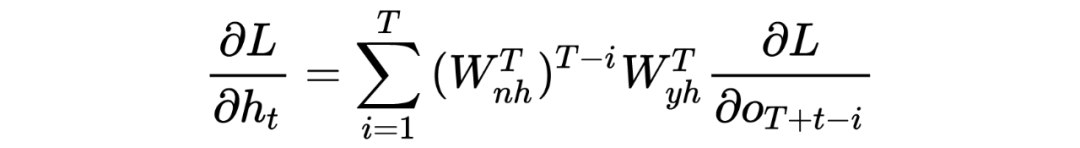
由此式我们知道当 、 变大或变小,对于幂次计算,结果会突变大或者趋于平稳消散不见!由此一般 RNN 理论介绍到此,想具体了解的可以查阅相关论文。
3 LSTM底层理论介绍
为了更好的捕获时序中间隔较大的依赖关系,基于门控制的长短记忆网络(LSTM)诞生了!
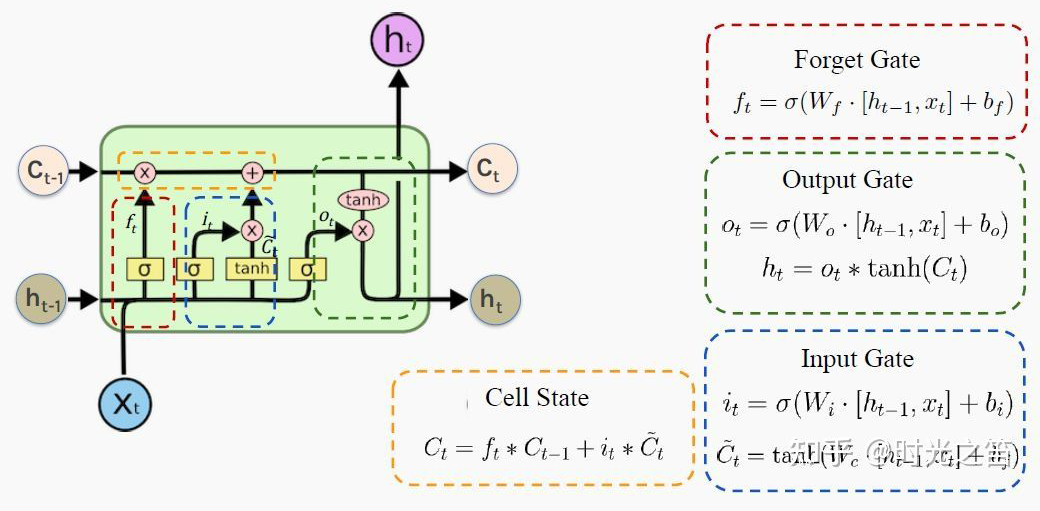
▲ 图2
所谓“门”结构就是用来去除或者增加信息到细胞状态的能力。这里的细胞状态是核心,它属于隐藏层,类似于传送带,在整个链上运行,信息在上面流传保持不变会变得很容易!
上图 2 非常形象生动描绘了 LSTM 核心的“三门结构”。红色圈就是所谓的遗忘门,那么在 时刻如下公式表示(如果我们真理解了 RNN 逻辑,LSTM 理解起来将变得比较轻松):
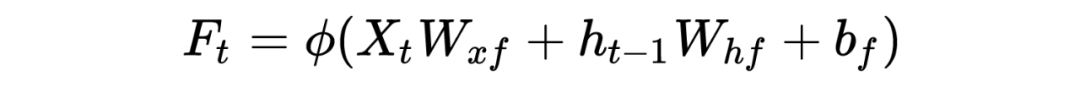
蓝圈输入门有
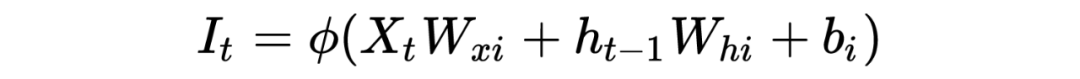
绿圈输出门有
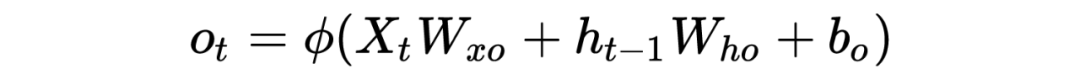
同理以上涉及的参数 和 为需要通过链式法则更新的参数!那么最后黄圈的细胞信息计算公式:
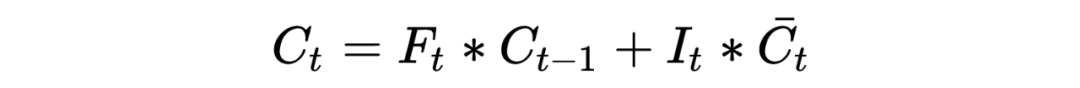
其中
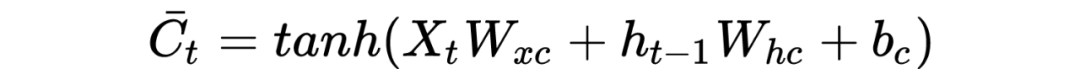
这里涉及的双曲正切函数 一般是固定的,那么费这么大事,搞这么多信息控制过程是为了什么?当然是为了更新细胞 值从而为了获取下一步隐藏层的值:
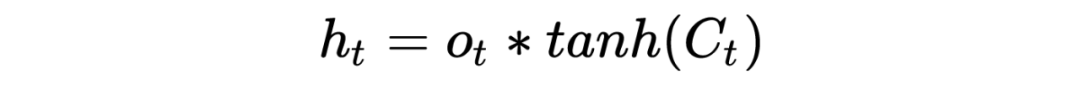
3.1 sigmoid激活函数的意义
当 激活函数选择 sigmoid 属于 0~1 的函数时,对于遗忘门近似等于 1,输入门近似等于 0,其实 是不更新的,那么过去的细胞信息一直保留到现在,解决了梯度消散问题。
同理,输出门可以近似等于 1,也可以近似等于 0,那么近似等于 1 时细胞信息将传递给隐藏层;近似等于 0 时,细胞信息只自己保留。至此所有参数更新一遍并继续向下走。。。
PS:也许初学者看到这么多符号会比较头疼,但逻辑是从简到复杂的,RNN 彻底理解有助于理解后面的深入模型。这里本人也省略了很多细节,大体模型框架就是如此,对于理解模型如何工作已经完全够了。至于怎么想出来的以及更为详细的推导过程,由于作者水平有限,可参考相关 RNN 论文,可多交流学习!
4 建模预测存在“右偏移”怎么办!
为了做对比实验,我们还会选择之前时序文章所对应的实际销量数据!我们将基于 keras 模块构建自己的 LSTM 网络进行时序预测。
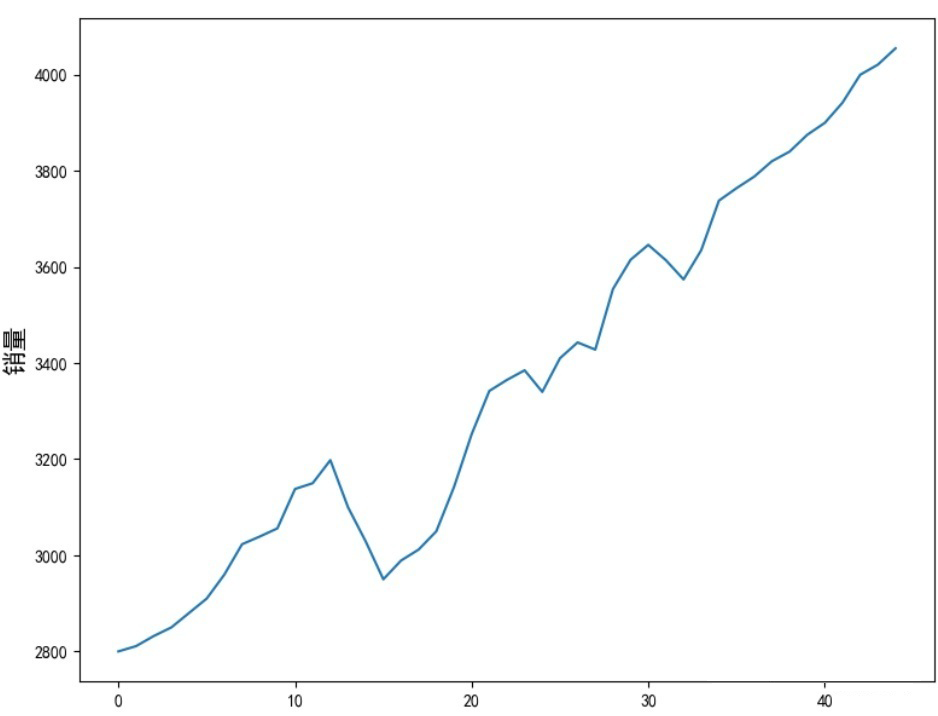
▲ 图3:实际销量数据
4.1 构建一般LSTM模型,当我们选择步长为1时,先给出结果如下
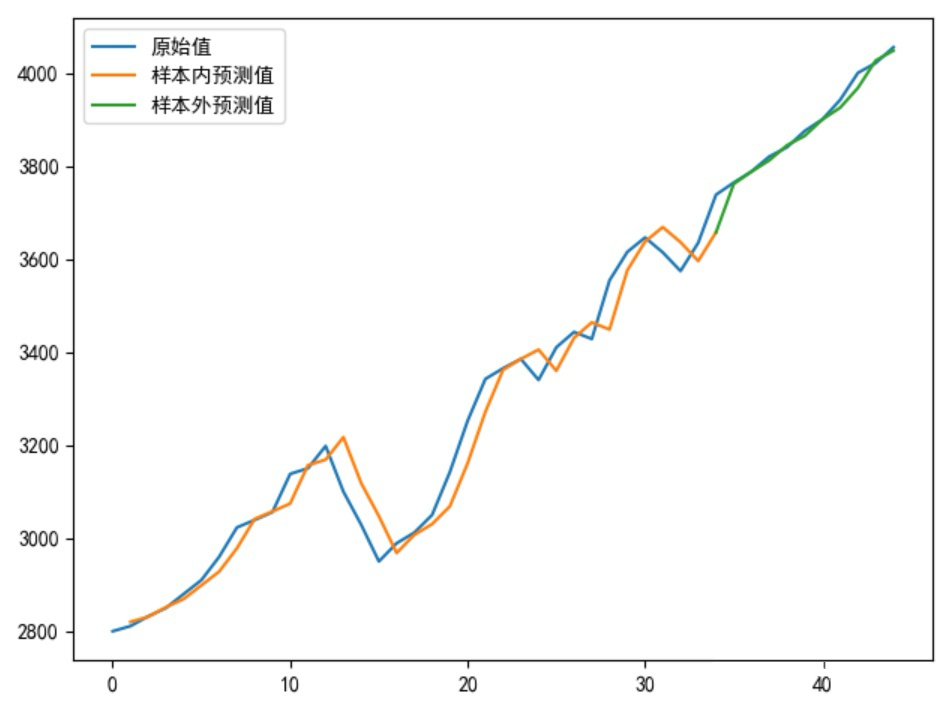
▲ 图4
正常建立 LSTM 模型预测会出现如上预测值右偏现象,尽管 r2 或者 MSE 很好,但这建立的模型其实是无效模型!
4.2 原因与改进
当模型倾向于把上一时刻的真实值作为下一时刻的预测值,导致两条曲线存在滞后性,也就是真实值曲线滞后于预测值曲线,如图 4 那样。之所以会这样,是因为序列存在自相关性,如一阶自相关指的是当前时刻的值与其自身前一时刻值之间的相关性。因此,如果一个序列存在一阶自相关,模型学到的就是一阶相关性。而消除自相关性的办法就是进行差分运算,也就是我们可以将当前时刻与前一时刻的差值作为我们的回归目标。
而且从之前文章做的白噪声检验也发现,该序列确实存在很强的自相关性!如下图 5 所示。
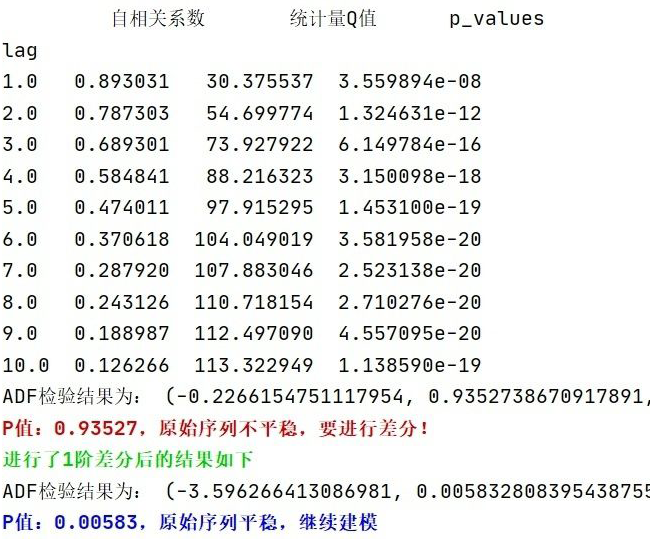
▲ 图5
5 改进模型输出
我们看下模型最终输出结果:
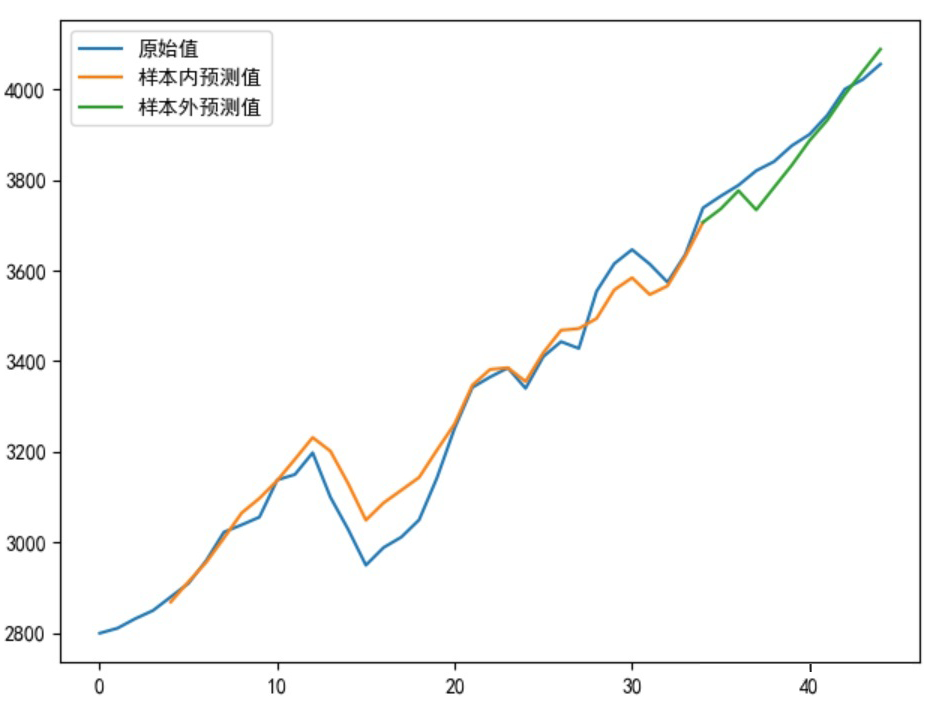

▲ 图6:LSTM结果
5.1 经典时序模型下的最优输出结果
ARIMA 模型的定阶原理与建模分析:
https://zhuanlan.zhihu.com/p/417232759
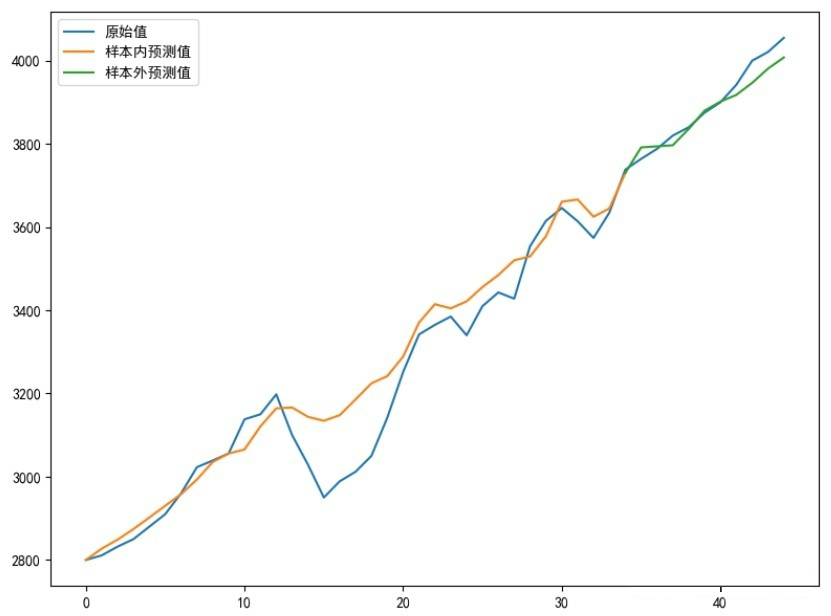
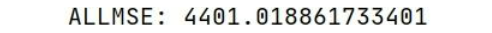
▲ 图7:ARIMA结果
此结果的全局 MSE=4401.02 大于 LSTM 网络的 MSE=2521.30,由此可见当我们优化 LSTM 模型后,一定程度上时序建模比 ARIMA 或者 ARIMA-GARCH 要优!
LSTM 预测理论跟 ARIMA 也是有区别的,LSTM 主要是基于窗口滑动取数据训练来预测滞后数据,其中的 cell 机制会由于权重共享原因减少一些参数;ARIMA 模型是根据自回归理论,建立与自己过去有关的模型。两者共同点就是能很好运用序列数据,而且通过不停迭代能无限预测下去,但预测模型还是基于短期预测有效,长期预测必然会导致偏差很大,而且有可能出现预测值趋于不变的情况。
6 最终代码
from keras.callbacks import LearningRateScheduler
from sklearn.metrics import mean_squared_error
from keras.models import Sequential
import matplotlib.pyplot as plt
from keras.layers import Dense
from keras.layers import LSTM
from keras import optimizers
import keras.backend as K
import tensorflow as tf
import pandas as pd
import numpy as np
plt.rcParams['font.sans-serif']=['SimHei']##中文乱码问题!
plt.rcParams['axes.unicode_minus']=False#横坐标负号显示问题!
###初始化参数
my_seed = 369#随便给出个随机种子
tf.random.set_seed(my_seed)##运行tf才能真正固定随机种子
sell_data = np.array([2800,2811,2832,2850,2880,2910,2960,3023,3039,3056,3138,3150,3198,3100,3029,2950,2989,3012,3050,3142,3252,3342,3365,3385,3340,3410,3443,3428,3554,3615,3646,3614,3574,3635,3738,3764,3788,3820,3840,3875,3900,3942,4000,4021,4055])
num_steps = 3##取序列步长
test_len = 10##测试集数量长度
S_sell_data = pd.Series(sell_data).diff(1).dropna()##差分
revisedata = S_sell_data.max()
sell_datanormalization = S_sell_data / revisedata##数据规范化
##数据形状转换,很重要!!
def data_format(data, num_steps=3, test_len=5):
# 根据test_len进行分组
X = np.array([data[i: i + num_steps]
for i in range(len(data) - num_steps)])
y = np.array([data[i + num_steps]
for i in range(len(data) - num_steps)])
train_size = test_len
train_X, test_X = X[:-train_size], X[-train_size:]
train_y, test_y = y[:-train_size], y[-train_size:]
return train_X, train_y, test_X, test_y
transformer_selldata = np.reshape(pd.Series(sell_datanormalization).values,(-1,1))
train_X, train_y, test_X, test_y = data_format(transformer_selldata, num_steps, test_len)
print('\033[1;38m原始序列维度信息:%s;转换后训练集X数据维度信息:%s,Y数据维度信息:%s;测试集X数据维度信息:%s,Y数据维度信息:%s\033[0m'%(transformer_selldata.shape, train_X.shape, train_y.shape, test_X.shape, test_y.shape))
def buildmylstm(initactivation='relu',ininlr=0.001):
nb_lstm_outputs1 = 128#神经元个数
nb_lstm_outputs2 = 128#神经元个数
nb_time_steps = train_X.shape[1]#时间序列长度
nb_input_vector = train_X.shape[2]#输入序列
model = Sequential()
model.add(LSTM(units=nb_lstm_outputs1, input_shape=(nb_time_steps, nb_input_vector),return_sequences=True))
model.add(LSTM(units=nb_lstm_outputs2, input_shape=(nb_time_steps, nb_input_vector)))
model.add(Dense(64, activation=initactivation))
model.add(Dense(32, activation='relu'))
model.add(Dense(test_y.shape[1], activation='tanh'))
lr = ininlr
adam = optimizers.adam_v2.Adam(learning_rate=lr)
def scheduler(epoch):##编写学习率变化函数
# 每隔epoch,学习率减小为原来的1/10
if epoch % 100 == 0 and epoch != 0:
lr = K.get_value(model.optimizer.lr)
K.set_value(model.optimizer.lr, lr * 0.1)
print('lr changed to {}'.format(lr * 0.1))
return K.get_value(model.optimizer.lr)
model.compile(loss='mse', optimizer=adam, metrics=['mse'])##根据损失函数性质,回归建模一般选用”距离误差“作为损失函数,分类一般选”交叉熵“损失函数
reduce_lr = LearningRateScheduler(scheduler)
###数据集较少,全参与形式,epochs一般跟batch_size成正比
##callbacks:回调函数,调取reduce_lr
##verbose=0:非冗余打印,即不打印训练过程
batchsize = int(len(sell_data) / 5)
epochs = max(128,batchsize * 4)##最低循环次数128
model.fit(train_X, train_y, batch_size=batchsize, epochs=epochs, verbose=0, callbacks=[reduce_lr])
return model
def prediction(lstmmodel):
predsinner = lstmmodel.predict(train_X)
predsinner_true = predsinner * revisedata
init_value1 = sell_data[num_steps - 1]##由于存在步长关系,这里起始是num_steps
predsinner_true = predsinner_true.cumsum() ##差分还原
predsinner_true = init_value1 + predsinner_true
predsouter = lstmmodel.predict(test_X)
predsouter_true = predsouter * revisedata
init_value2 = predsinner_true[-1]
predsouter_true = predsouter_true.cumsum() ##差分还原
predsouter_true = init_value2 + predsouter_true
# 作图
plt.plot(sell_data, label='原始值')
Xinner = [i for i in range(num_steps + 1, len(sell_data) - test_len)]
plt.plot(Xinner, list(predsinner_true), label='样本内预测值')
Xouter = [i for i in range(len(sell_data) - test_len - 1, len(sell_data))]
plt.plot(Xouter, [init_value2] + list(predsouter_true), label='样本外预测值')
allpredata = list(predsinner_true) + list(predsouter_true)
plt.legend()
plt.show()
return allpredata
mymlstmmodel = buildmylstm()
presult = prediction(mymlstmmodel)
def evaluate_model(allpredata):
allmse = mean_squared_error(sell_data[num_steps + 1:], allpredata)
print('ALLMSE:',allmse)
evaluate_model(presult)7 总结
任何模型都不是万能的,重点是要有发现问题和解决问题的能力。
小数据建模往往比大数据要更难,更要思考。
对于深度模型学习,本人还是强烈建议要大致懂模型的内涵和原理,有条件甚至可以自己推导一遍或者简单实现下梯度下降算法、损失函数构建等等,否则很难解决真正的问题。
推荐阅读:
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书