LSTM 网络是一种特殊的循环神经网络,它在RNN 的基础上进行了改进
,通过增加输入门、遗忘门和输出门,缓解了模型训练中梯度消失和梯度
爆炸的问题,弥补了传统 RNN 模型的不足。LSTM 网络单元结构如下
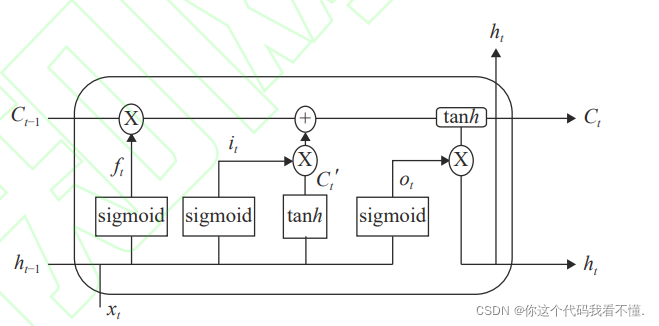
ht、ht-1 为当前单元及上一个单元的输出;xt 为当前单元的输入;sigmoid、tanh 为激活函数;图中的圆圈均表示向量之间的算术规则;Ct 为神经元 在 t 时 刻 的 状 态 ; ft 为 遗 忘 阈 值 , 该 阈 值 通 过sigmoid 激活函数控制细胞应该如何丢弃信息;it 为输入阈值,该阈值决定了 sigmoid 函数需要更新的信息,然后使用 tanh 激活函数生成新的记忆 Ct,并最终控制向神经元状态添加多少新信息;ot 为输出阈值,该阈值决定了 sigmoid 函数输出神经元状态的哪些部分,并使用 tanh 激活函数处理神经元状态,得到最终的结果。计算公式如下:
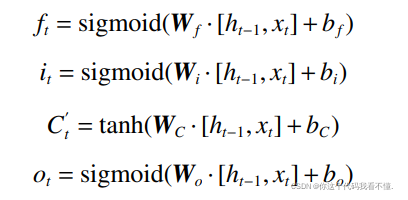
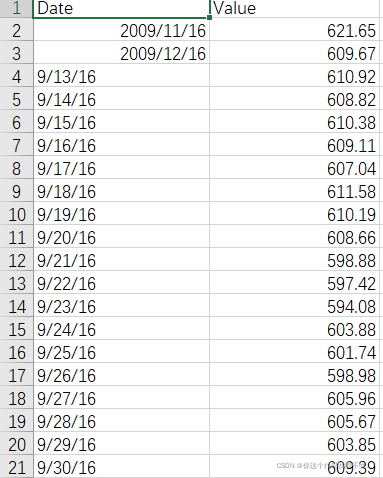
数据描述:
只有时间和当天收盘的数据
代码
import tushare as ts
import torch.nn as nn
import torch
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import numpy as np
from torch.autograd import Variable
import os
import pandas as pd
from torchvision import transforms
import numpy as np
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
from torchsummary import summary
# 获取代号为000300的股票价格
# cons=ts.get_apis()
# df=ts.bar('000001', conn=cons, asset='INDEX', start_date='2018-01-01', end_date='')
#
# df=df.sort_index(ascending=True)
df = pd.read_csv("LBMA-GOLD.csv")
#df = pd.read_csv("BCHAIN-MKPRU.csv")
df = df.sort_index(ascending=True)
print(df.head(5))
# 提取open,close,high,low,vol 作为feature,并做标准化
df = df[["USD (PM)"]]
close_min = df['USD (PM)'].min()
close_max = df["USD (PM)"].max()
# df = df[["Value"]]
# close_min = df['Value'].min()
# close_max = df["Value"].max()
df = df.apply(lambda x: (x - min(x)) / (max(x) - min(x)))
# 定义X和Y: 根据前n天的数据,预测当天的收盘价
# 例如根据 1月1日,1月2日,1月3日 的价格预测 1月4日的收盘价
# X=[ ["open1","close1","high1","low1","vol1"] ,["open2","close2","high2","low2","vol2"] ,["open3","close3","high3","low3","vol3"] ]
# Y=[ close4 ]
# 那么X对应的sequence=3 , [ input_size=5(5维度) ,这tm就是nlp中每个词的embedding ]
total_len = df.shape[0]
sequence = 5
X = []
Y = []
for i in range(df.shape[0] - sequence):
X.append(np.array(df.iloc[i:(i + sequence), ].values, dtype=np.float32))
Y.append(np.array(df.iloc[(i + sequence), 0], dtype=np.float32))
print(X[0])
print(Y[0])
x = len(X)
y = len(Y)
# 重写Dataset
class Mydataset(Dataset):
def __init__(self, xx, yy, transform=None):
self.x = xx
self.y = yy
self.tranform = transform
def __getitem__(self, index):
x1 = self.x[index]
y1 = self.y[index]
if self.tranform != None:
return self.tranform(x1), y1
return x1, y1
def __len__(self):
return len(self.x)
# # 构建batch
trainx, trainy = X[:int(0.7 * total_len)], Y[:int(0.7 * total_len)]
testx, testy = X[int(0.7 * total_len):], Y[int(0.7 * total_len):]
train_loader = DataLoader(dataset=Mydataset(trainx, trainy, transform=transforms.ToTensor()), batch_size=12,
shuffle=True)
test_loader = DataLoader(dataset=Mydataset(testx, testy), batch_size=12, shuffle=True)
from sklearn.metrics import mean_absolute_error,r2_score,mean_squared_error
def Evaluate(y_test,y_pre):
MAPE=100*np.mean(np.abs((y_pre - y_test) / y_test))
MAE=mean_absolute_error(y_test,y_pre)
R2=r2_score(y_test,y_pre)
MSE=mean_squared_error(y_test,y_pre)
RMSE=np.sqrt(mean_squared_error(y_test,y_pre))
M=[MAPE,MAE,R2,MSE,RMSE]
return M
class lstm(nn.Module):
def __init__(self, input_size=1, hidden_size=32, output_size=1):
super(lstm, self).__init__()
# lstm的输入 #batch,seq_len, input_size
self.hidden_size = hidden_size
self.input_size = input_size
self.output_size = output_size
self.rnn = nn.LSTM(input_size=self.input_size, hidden_size=self.hidden_size, batch_first=True)
self.linear = nn.Linear(self.hidden_size, self.output_size)
def forward(self, x):
out, (hidden, cell) = self.rnn(
x) # x.shape : batch,seq_len,hidden_size , hn.shape and cn.shape : num_layes * direction_numbers,batch,hidden_size
a, b, c = hidden.shape
out = self.linear(hidden.reshape(a * b, c))
return out
model = lstm()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
preds = []
labels = []
for i in range(100):
total_loss = 0
for idx, (data, label) in enumerate(train_loader):
data1 = data.squeeze(1)
pred = model(Variable(data1))
label = label
label = label.unsqueeze(1)
loss = criterion(pred, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
# 开始测试
preds = []
labels = []
for idx, (x, label) in enumerate(test_loader):
x = x.squeeze(1) # batch_size,seq_len,input_size
pred = model(x)
preds.extend(pred.data.squeeze(1).tolist())
label = label
labels.extend(label.tolist())
print(preds)
print(labels)
print(Evaluate(np.array(labels),np.array(preds)))
# print(len(preds[0:50]))
# print(len(labels[0:50]))
import matplotlib.pyplot as plt
plt.plot([ele * (close_max - close_min) + close_min for ele in preds[0:500]], "r", label="pred")
plt.plot([ele * (close_max - close_min) + close_min for ele in labels[0:500]], "b", label="real")
plt.show()
ele = preds[0]
ele1 = labels[0]
print(ele1 * (close_max - close_min) + close_min)
print(ele * (close_max - close_min) + close_min)
# close1_min = preds.min()
# close1_max = preds.max()
# preds = preds.apply(lambda x: (x - min(x)) / (max(x) - min(x)))
# preds = np.array(preds)
# preds = preds.apply(lambda x: (close_max-close_min)*x + close_min)
# print(preds)