1.3 神经网络基础
学习目标
- 目标
- 了解感知机结构、作用以及优缺点
- 了解tensorflow playground的使用
- 说明感知机与神经网络的联系
- 说明神经网络的组成
- 应用
- 无
1.3.1 神经网络
人工神经网络( Artificial Neural Network, 简写为ANN)也简称为神经网络(NN)。是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)结构和功能的 计算模型。经典的神经网络结构包含三个层次的神经网络。分别输入层,输出层以及隐藏层。

其中每层的圆圈代表一个神经元,隐藏层和输出层的神经元有输入的数据计算后输出,输入层的神经元只是输入。
- 神经网络的特点
- 每个连接都有个权值
- 同一层神经元之间没有连接
- 最后的输出结果对应的层也称之为全连接层
神经网络是深度学习的重要算法,用途在图像(如图像的分类、检测)和自然语言处理(如文本分类、聊天等)
那么为什么设计这样的结构呢?首先从一个最基础的结构说起,神经元。以前也称之为感知机。神经元就是要模拟人的神经元结构。

一个神经元通常具有多个树突,主要用来接受传入信息;而轴突只有一条,轴突尾端有许多轴突末梢可以给其他多个神经元传递信息。轴突末梢跟其他神经元的树突产生连接,从而传递信号。这个连接的位置在生物学上叫做“突触”。
要理解神经网络,其实要从感知机开始。
1.3.1.1 感知机(PLA: Perceptron Learning Algorithm))
感知机就是模拟这样的大脑神经网络处理数据的过程。感知机模型如下图:

感知机是一种最基础的分类模型,前半部分类似于回归模型。感知机最基础是这样的函数,而逻辑回归用的sigmoid。这个感知机具有连接的权重和偏置

我们通过一个平台去演示,就是tensorflow playground
1.3.2 playground使用

那么在这整个分类过程当中,是怎么做到这样的效果那要受益于神经网络的一些特点

要区分一个数据点是橙色的还是蓝色的,你该如何编写代码?也许你会像下面一样任意画一条对角线来分隔两组数据点,定义一个阈值以确定每个数据点属于哪一个组。
其中 b 是确定线的位置的阈值。通过分别为 x1 和 x2 赋予权重 w1 和 w2,你可以使你的代码的复用性更强。

此外,如果你调整 w1 和 w2 的值,你可以按你喜欢的方式调整线的角度。你也可以调整 b 的值来移动线的位置。所以你可以重复使用这个条件来分类任何可以被一条直线分类的数据集。但问题的关键是程序员必须为 w1、w2 和 b 找到合适的值——即所谓的参数值,然后指示计算机如何分类这些数据点。
1.3.2.1 playground简单两类分类结果

但是这种结构的线性的二分类器,但不能对非线性的数据并不能进行有效的分类。
感知机结构,能够很好去解决与、或等问题,但是并不能很好的解决异或等问题。我们通过一张图来看,有四个样本数据
与问题:每个样本的两个特征同时为1,结果为1
或问题:每个样本的两个特征一个为1,结果为1
异或:每个样本的两个特征相同为0, 不同为1
根据上述的规则来进行划分,我们很容易建立一个线性模型

相当于给出这样的数据


1.3.2.2 单神经元复杂的两类-playground演示

那么怎么解决这种问题呢?其实我们多增加几个感知机即可解决?也就是下图这样的结构,组成一层的结构?

1.3.2.3 多个神经元效果演示

1.4 神经网络原理
学习目标
- 目标
- 说明神经网络的分类原理
- 说明softmax回归
- 说明交叉熵损失
- 应用
- 无
神经网络的主要用途在于分类,那么整个神经网络分类的原理是怎么样的?我们还是围绕着损失、优化这两块去说。神经网络输出结果如何分类?

神经网络解决多分类问题最常用的方法是设置n个输出节点,其中n为类别的个数。
任意事件发生的概率都在0和1之间,且总有某一个事件发生(概率的和为1)。如果将分类问题中“一个样例属于某一个类别”看成一个概率事件,那么训练数据的正确答案就符合一个概率分布。如何将神经网络前向传播得到的结果也变成概率分布呢?Softmax回归就是一个常用的方法。
1.4.1 softmax回归
Softmax回归将神经网络输出转换成概率结果


- softmax特点
如何理解这个公式的作用呢?看一下计算案例
假设输出结果为:2.3, 4.1, 5.6
softmax的计算输出结果为:
y1_p = e^2.3/(e^2.3+e^4.1+e^5.6)
y1_p = e^4.1/(e^2.3+e^4.1+e^5.6)
y1_p = e^5.6/(e^2.3+e^4.1+e^5.6)
这样就把神经网络的输出也变成了一个概率输出

那么如何去衡量神经网络预测的概率分布和真实答案的概率分布之间的距离?
1.4.2 交叉熵损失
1.4.2.1 公式
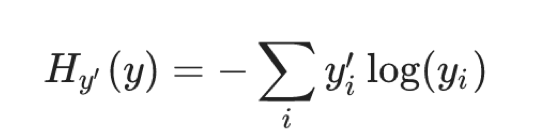
为了能够衡量距离,目标值需要进行one-hot编码,能与概率值一一对应,如下图

它的损失如何计算?
0log(0.10)+0log(0.05)+0log(0.15)+0log(0.10)+0log(0.05)+0log(0.20)+1log(0.10)+0log(0.05)+0log(0.10)+0log(0.10)
上述的结果为1log(0.10),那么为了减少这一个样本的损失。神经网络应该怎么做?所以会提高对应目标值为1的位置输出概率大小,由于softmax公式影响,其它的概率必定会减少。只要这样进行调整这样是不是就预测成功了!!!!!
提高对应目标值为1的位置输出概率大小
1.4.2.2 损失大小
神经网络最后的损失为平均每个样本的损失大小。对所有样本的损失求和取其平均值
1.4.3 梯度下降算法
目的:使损失函数的值找到最小值
方式:梯度下降
函数的梯度(gradient)指出了函数的最陡增长方向。梯度的方向走,函数增长得就越快。那么按梯度的负方向走,函数值自然就降低得最快了。模型的训练目标即是寻找合适的 w 与 b 以最小化代价函数值。假设 w 与 b 都是一维实数,那么可以得到如下的 J 关于 w 与 b 的图:

可以看到,此成本函数 J 是一个凸函数
参数w和b的更新公式为:
w := w - \alpha\frac{dJ(w, b)}{dw}w:=w−αdwdJ(w,b),b := b - \alpha\frac{dJ(w, b)}{db}b:=b−αdbdJ(w,b)
注:其中 α 表示学习速率,即每次更新的 w 的步伐长度。当 w 大于最优解 w′ 时,导数大于 0,那么 w 就会向更小的方向更新。反之当 w 小于最优解 w′ 时,导数小于 0,那么 w 就会向更大的方向更新。迭代直到收敛。
通过平面来理解梯度下降过程:

1.4.4 网络原理总结
我们不会详细地讨论可以如何使用反向传播和梯度下降等算法训练参数。训练过程中的计算机会尝试一点点增大或减小每个参数,看其能如何减少相比于训练数据集的误差,以望能找到最优的权重、偏置参数组合。


tf.keras介绍
1.3 Tensorflow实现神经网络
学习目标
- 目标
- 掌握Tensorflow API的使用
- 应用
- 应用TF搭建一个分类模型
1.3.1 TensorFlow keras介绍
Keras 是一个用于构建和训练深度学习模型的高阶 API。它可用于快速设计原型、高级研究和生产,具有以下三个主要优势:
- 方便用户使用,快速构建模型 Keras 具有针对常见用例做出优化的简单而一致的界面。它可针对用户错误提供切实可行的清晰反馈。
-
模块化和可组 将可配置的构造块连接在一起就可以构建 Keras 模型,并且几乎不受限制。
-
导入:
import tensorflow as tf
from tensorflow import keras
- 1、获取相关现有数据集(无需自己去构造)
- keras.datasets
- mnist:手写数字
- fashion_mnist:时尚分类
- cifar10(100):10个类别分类
- keras.datasets
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
print(train_images, train_labels)
- 2、构建模型
- 在 Keras 中,您可以通过组合层来构建模型。模型(通常)是由层构成的图。最常见的模型类型是层的堆叠,keras.layers中就有很多模型,如下图:可以在源码文件中找到
- tf.keras.Sequential模型(layers如下)
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import DepthwiseConv2D
from tensorflow.python.keras.layers import Dot
from tensorflow.python.keras.layers import Dropout
from tensorflow.python.keras.layers import ELU
from tensorflow.python.keras.layers import Embedding
from tensorflow.python.keras.layers import Flatten
from tensorflow.python.keras.layers import GRU
from tensorflow.python.keras.layers import GRUCell
from tensorflow.python.keras.layers import LSTMCell
...
...
...
- Flatten:将输入数据进行形状改变展开
- Dense:添加一层神经元
- Dense(units,activation=None,**kwargs)
- units:神经元个数
- activation:激活函数,参考tf.nn.relu,tf.nn.softmax,tf.nn.sigmoid,tf.nn.tanh
- **kwargs:输入上层输入的形状,input_shape=()
- Dense(units,activation=None,**kwargs)
tf.keras.Sequential构建类似管道的模型
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)
])
-
3、训练与评估
-
通过调用model的
compile方法去配置该模型所需要的训练参数以及评估方法。 -
model.compile(optimizer,loss=None,metrics=None, 准确率衡):配置训练相关参数
- optimizer:梯度下降优化器(在keras.optimizers)
from tensorflow.python.keras.optimizers import Adadelta from tensorflow.python.keras.optimizers import Adagrad from tensorflow.python.keras.optimizers import Adam from tensorflow.python.keras.optimizers import Adamax from tensorflow.python.keras.optimizers import Nadam from tensorflow.python.keras.optimizers import Optimizer from tensorflow.python.keras.optimizers import RMSprop from tensorflow.python.keras.optimizers import SGD from tensorflow.python.keras.optimizers import deserialize from tensorflow.python.keras.optimizers import get from tensorflow.python.keras.optimizers import serialize from tensorflow.python.keras.optimizers import AdamOptimizer()- loss=None:损失类型,类型可以是字符串或者该function名字参考:
from tensorflow.python.keras.losses import KLD from tensorflow.python.keras.losses import KLD as kld from tensorflow.python.keras.losses import KLD as kullback_leibler_divergence from tensorflow.python.keras.losses import MAE from tensorflow.python.keras.losses import MAE as mae from tensorflow.python.keras.losses import MAE as mean_absolute_error from tensorflow.python.keras.losses import MAPE from tensorflow.python.keras.losses import MAPE as mape from tensorflow.python.keras.losses import MAPE as mean_absolute_percentage_error from tensorflow.python.keras.losses import MSE from tensorflow.python.keras.losses import MSE as mean_squared_error from tensorflow.python.keras.losses import MSE as mse from tensorflow.python.keras.losses import MSLE from tensorflow.python.keras.losses import MSLE as mean_squared_logarithmic_error from tensorflow.python.keras.losses import MSLE as msle from tensorflow.python.keras.losses import binary_crossentropy from tensorflow.python.keras.losses import categorical_crossentropy from tensorflow.python.keras.losses import categorical_hinge from tensorflow.python.keras.losses import cosine from tensorflow.python.keras.losses import cosine as cosine_proximity from tensorflow.python.keras.losses import deserialize from tensorflow.python.keras.losses import get from tensorflow.python.keras.losses import hinge from tensorflow.python.keras.losses import logcosh from tensorflow.python.keras.losses import poisson from tensorflow.python.keras.losses import serialize from tensorflow.python.keras.losses import sparse_categorical_crossentropy from tensorflow.python.keras.losses import squared_hinge- metrics=None, ['accuracy']
-
model.fit():进行训练
-
(x=None,y=None, batch_size=None,epochs=1,callbacks=None)
-
x:特征值:
1、Numpy array (or array-like), or a list of arrays 2、A TensorFlow tensor, or a list of tensors 3、`tf.data` dataset or a dataset iterator. Should return a tuple of either `(inputs, targets)` or `(inputs, targets, sample_weights)`. 4、A generator or `keras.utils.Sequence` returning `(inputs, targets)` or `(inputs, targets, sample weights)`. -
y:目标值
-
batch_size=None:批次大小
-
epochs=1:训练迭代次数
-
callbacks=None:添加回调列表(用于如tensorboard显示等)
-
-
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5)
model.evaluate(test_images, test_labels)
1.3.2 案例:实现多层神经网络进行时装分类
70000 张灰度图像,涵盖 10 个类别。以下图像显示了单件服饰在较低分辨率(28x28 像素)下的效果:

1.3.2.1 需求:
| 标签 | 类别 |
|---|---|
| 0 | T 恤衫/上衣 |
| 1 | 裤子 |
| 2 | 套衫 |
| 3 | 裙子 |
| 4 | 外套 |
| 5 | 凉鞋 |
| 6 | 衬衫 |
| 7 | 运动鞋 |
| 8 | 包包 |
1.3.2.2 步骤分析和代码实现:
- 读取数据集:
- 从datasets中获取相应的数据集,直接有训练集和测试集
class SingleNN(object):
def __init__(self):
(self.train, self.train_label), (self.test, self.test_label) = keras.datasets.fashion_mnist.load_data()
- 进行模型编写
- 双层:128个神经元,全连接层10个类别输出
class SingleNN(object):
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)
])
这里我们model只是放在类中,作为类的固定模型属性
激活函数的选择
涉及到网络的优化时候,会有不同的激活函数选择有一个问题是神经网络的隐藏层和输出单元用什么激活函数。之前我们都是选用 sigmoid 函数,但有时其他函数的效果会好得多,大多数通过实践得来,没有很好的解释性。
可供选用的激活函数有:
- tanh 函数(the hyperbolic tangent function,双曲正切函数):

效果比 sigmoid 函数好,因为函数输出介于 -1 和 1 之间。
注 :tanh 函数存在和 sigmoid 函数一样的缺点:当 z 趋紧无穷大(或无穷小),导数的梯度(即函数的斜率)就趋紧于 0,这使得梯度算法的速度会减慢。
- ReLU 函数(the rectified linear unit,修正线性单元)

当 z > 0 时,梯度始终为 1,从而提高神经网络基于梯度算法的运算速度,收敛速度远大于 sigmoid 和 tanh。然而当 z < 0 时,梯度一直为 0,但是实际的运用中,该缺陷的影响不是很大。
-
Leaky ReLU(带泄漏的 ReLU):

Leaky ReLU 保证在 z < 0 的时候,梯度仍然不为 0。理论上来说,Leaky ReLU 有 ReLU 的所有优点,但在实际操作中没有证明总是好于 ReLU,因此不常用。
为什么需要非线性的激活函数
使用线性激活函数和不使用激活函数、直接使用 Logistic 回归没有区别,那么无论神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,就成了最原始的感知器了。
a^{[1]} = z^{[1]} = W^{[1]}x+b^{[1]}a[1]=z[1]=W[1]x+b[1]
{a}^{[2]}=z^{[2]} = W^{[2]}a^{[1]}+b^{[2]}a[2]=z[2]=W[2]a[1]+b[2]
那么这样的话相当于
{a}^{[2]}=z^{[2]} = W^{[2]}(W^{[1]}x+b^{[1]})+b^{[2]}=(W^{[2]}W^{[1]})x+(W^{[2]}b^{[1]}+b^{[2]})=wx+ba[2]=z[2]=W[2](W[1]x+b[1])+b[2]=(W[2]W[1])x+(W[2]b[1]+b[2])=wx+b
- 编译、训练以及评估
def compile(self):
SingleNN.model.compile(optimizer=tf.train.AdamOptimizer(),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy'])
return None
def fit(self):
SingleNN.model.fit(self.train, self.train_label, epochs=5)
return None
def evaluate(self):
test_loss, test_acc = SingleNN.model.evaluate(self.test, self.test_label)
print(test_loss, test_acc)
return None
1.3.2.1 打印模型
- model.summary():查看模型结构
1.3.2.2 手动保存和回复模型
- 目的:防止训练长时间,出现意外导致重新训练
- model.save_weights('./weights/my_model')
- model.load_weights('./weights/my_model')
SingleNN.model.save_weights("./ckpt/SingleNN")
def predict(self):
# 直接使用训练过后的权重测试
if os.path.exists("./ckpt/checkpoint"):
SingleNN.model.load_weights("./ckpt/SingleNN")
predictions = SingleNN.model.predict(self.test)
print(np.argmax(predictions, 1))
return
1.3.2.3 添加Tensorboard观察损失等情况
# 添加tensoboard观察
tensorboard = keras.callbacks.TensorBoard(log_dir='./graph', histogram_freq=0,
write_graph=True, write_images=True)
SingleNN.model.fit(self.train, self.train_label, epochs=5, callbacks=[tensorboard])1.4 深层神经网络
学习目标
- 目标
- 了解深层网络的前向传播与反向传播的过程
- 应用
- 无
为什么使用深层网络
对于人脸识别等应用,神经网络的第一层从原始图片中提取人脸的轮廓和边缘,每个神经元学习到不同边缘的信息;网络的第二层将第一层学得的边缘信息组合起来,形成人脸的一些局部的特征,例如眼睛、嘴巴等;后面的几层逐步将上一层的特征组合起来,形成人脸的模样。随着神经网络层数的增加,特征也从原来的边缘逐步扩展为人脸的整体,由整体到局部,由简单到复杂。层数越多,那么模型学习的效果也就越精确。
通过例子可以看到,随着神经网络的深度加深,模型能学习到更加复杂的问题,功能也更加强大。
1.4.1 深层神经网络表示
1.4.1.1 什么是深层网络?

使用浅层网络的时候很多分类等问题得不到很好的解决,所以需要深层的网络。
1.4.2 四层网络的前向传播与反向传播

在这里首先对每层的符号进行一个确定,我们设置L为第几层,n为每一层的个数,L=[L1,L2,L3,L4],n=[5,5,3,1]
1.4.2.1 前向传播
首先还是以单个样本来进行表示,每层经过线性计算和激活函数两步计算
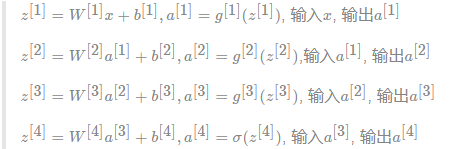

1.4.2.2 反向传播
因为涉及到的层数较多,所以我们通过一个图来表示反向的过程


1.4.3 参数与超参数
1.4.3.1 参数
参数即是我们在过程中想要模型学习到的信息(模型自己能计算出来的),例如 W[l]W[l],b[l]b[l]。而超参数(hyper parameters)即为控制参数的输出值的一些网络信息(需要人经验判断)。超参数的改变会导致最终得到的参数 W[l],b[l] 的改变。
1.4.3.2 超参数
典型的超参数有:
- 学习速率:α
- 迭代次数:N
- 隐藏层的层数:L
- 每一层的神经元个数:n[1],n[2],...
- 激活函数 g(z) 的选择
当开发新应用时,预先很难准确知道超参数的最优值应该是什么。因此,通常需要尝试很多不同的值。应用深度学习领域是一个很大程度基于经验的过程。
1.4.3.3 参数初始化
- 为什么要随机初始化权重
如果在初始时将两个隐藏神经元的参数设置为相同的大小,那么两个隐藏神经元对输出单元的影响也是相同的,通过反向梯度下降去进行计算的时候,会得到同样的梯度大小,所以在经过多次迭代后,两个隐藏层单位仍然是对称的。无论设置多少个隐藏单元,其最终的影响都是相同的,那么多个隐藏神经元就没有了意义。
在初始化的时候,W 参数要进行随机初始化,不可以设置为 0。b 因为不存在上述问题,可以设置为 0。
以 2 个输入,2 个隐藏神经元为例:
W = np.random.rand(2,2)* 0.01
b = np.zeros((2,1))
- 初始化权重的值选择
这里将 W 的值乘以 0.01(或者其他的常数值)的原因是为了使得权重 W 初始化为较小的值,这是因为使用 sigmoid 函数或者 tanh 函数作为激活函数时,W 比较小,则 Z=WX+b 所得的值趋近于 0,梯度较大,能够提高算法的更新速度。而如果 W 设置的太大的话,得到的梯度较小,训练过程因此会变得很慢。
ReLU 和 Leaky ReLU 作为激活函数时不存在这种问题,因为在大于 0 的时候,梯度均为 1。
