介绍
希尔排序(Shell Sort)是D.L.Shell于1959年提出来的一种排序算法,在这之前排序算法的时间复杂度基本都是 的,希尔排序算法是突破这个时间复杂度的第一批算法之一。
我们前一节讲的直接插入排序,应该说,它的效率在某些时候是很高的,比如,我们的记录本身就是基本有序的,我们只需要少量的插入操作,就可以完成整个记录集的排序工作,此时直接插入很高效。还有就是记录数比较少时,直接插入的优势也比较明显。可问题在于,两个条件本身就过于苛刻,现实中记录少或者基本有序都属于特殊情况。
希尔排序其实可以理解为是聪明版的插入排序,即先把几小波数据完成插入排序,最后再把已经插入排序过的数据再次进行插入排序。
这个算法的时间非常快。
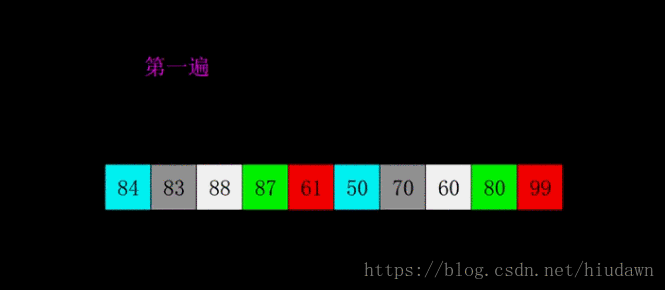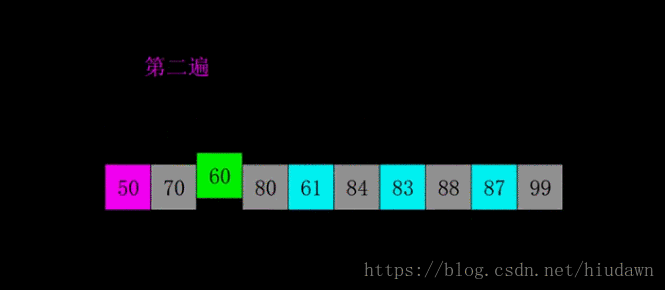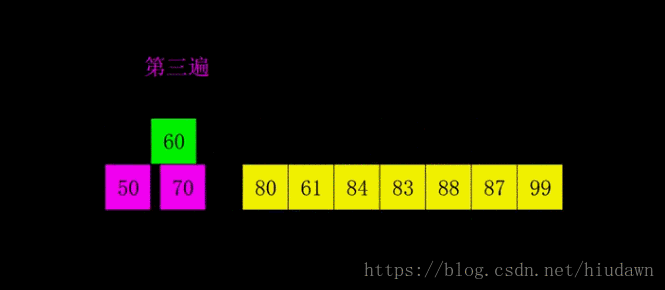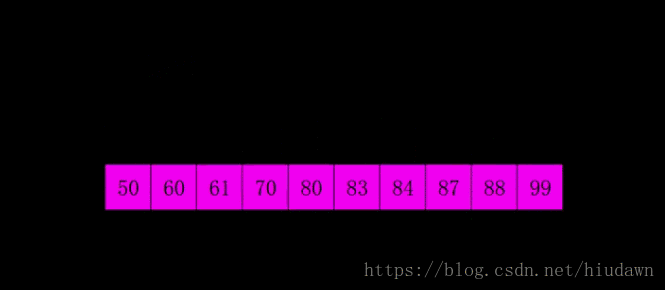
注意看,一开始不同颜色块就是不同的波次,每次的分组是会慢慢减少的。一开始组可以设定为
,即N个数据,相当于开始什么事情都不做,接下来组的数量按
衰减。具体请看代码。
代码
//辅助函数:交换两个变量
void swap(int*a,int*p)
{
int temp = *a;
*a = *p;
*p = temp;
}
//希尔排序
//插入排序的加强版,不是一次性进行插入,而是分成一拨拨来进行
//比如奇数下标的为一拨,偶数下标的为一拨,然后再对分好的两拨进行插入排序
//也就是一开始是隔一定step>1进行插入排序,最后的step=1
//这个步长的变动方式有多种,可是是 step:=step/3+1
//对大量的数据,排序效率明显比插入排序高
void shellSort(int* arr,int len)
{
int step = len;
//do while比较好,保证step为1还能再排一次
do
{
//这句一定要放这里,不然步长为1就跳出去了,最后一次无法排序
step = step/3 +1;
int i,j,k;
//分拨排序,一共有step拨
for(i=0;i<step;i++)
{
for(j=i;j<len;j+=step)
{
for(k=j;k>i;k-=step)
{
if(arr[k]<arr[k-step])
{
swap(&arr[k],&arr[k-step]);
}else
{
break;
}
}
}
}
}while(step>1);
}