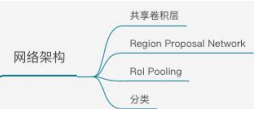
1.网络架构
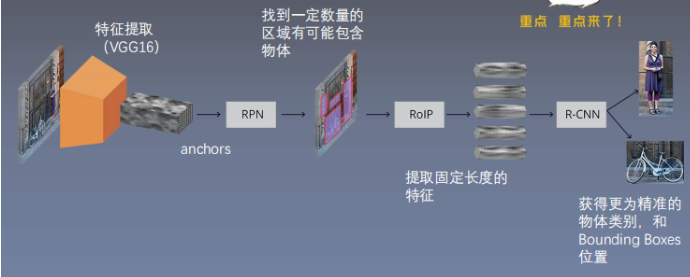
VGG16网络
anchors:人工放上去的
RPN对anchors进行二分类,正样本,负样本
RoIP:前面的框框已经圈出目标,但还不知道具体属于哪个类,它就是干这个工作的
2.VGG网络
VGG网络可以任意替换其他的任意神经网络,resnet等
以VGG网络为例:
- 首先缩放至固定大小MxN。VGG网络输出Feature Map
- 放入共享Conv layers
- RPN计算proposals
- Roi Pooling层则利用,proposals从feature maps中提取proposal features
- 送入后续全连接和softmax网络作classification。
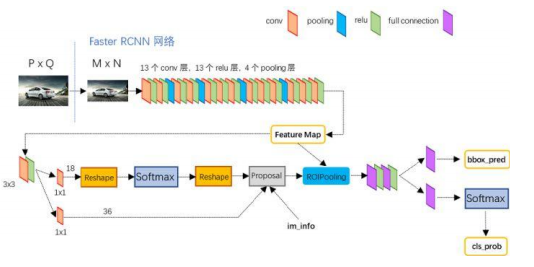
3.共享卷积层
以VGG网络为例:
- Conv layers部分共有13个conv层, 13个relu层,4个pooling层。
- 所有的conv层都是:kernel_size=3,pad=1, stride=1
- 所有的pooling层都是:kernel_size=2,pad=0, stride=2
- 在Faster RCNN Conv layers中对所有的卷积都做了扩边处理( pad=1,即填充一圈0),导致原图变为 (M+2)x(N+2)大小,再做3x3卷积后输出MxN 。
- pooling层kernel_size=2,stride=2。这样每个经过 pooling层的MxN矩阵,都会变为(M/2)x(N/2)大小。
- 一个MxN大小的矩阵经过Conv layers固定变为 (M/16)xN/16) (注:有四层pooling,2^4=16)
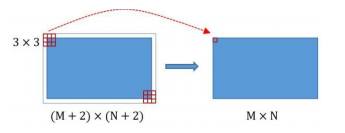
图像的大小改变都是有pooling造成的
为什么叫共享?因为VGG产生的Feature Map用于RPN的训练,同时也用于RCNN的训练
4.Anchors
绿框框逐行的扫描
备选框:有一定的可能性包含物体在里面
- 4个值表示矩形左上和右下角点坐标:(x1,y1,x2,y2)
- 九个矩阵共有三种形状,长宽比大约为:
- 为每一个点都配备这9种anchors作为初始的检测框
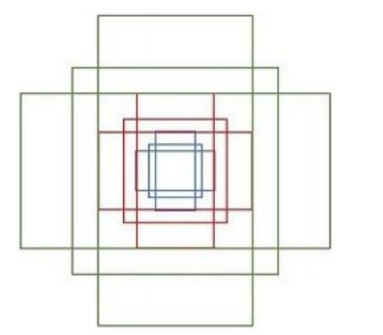
对每一个点都生成这样的框框,量是非常巨大的
- 原文中使用的是ZF model中,其 Conv Layers中最后的conv5层 num_output=256,对应生成256 张特征图,所以相当于feature map每个点都是256-dimensions.
- 训练程序会在合适的anchors中随机选取128个postive anchors+128 个negative anchors进行训练
例如:
一个feature map 就产生17100个anchors
4.1对Anchor分配标签
-
区分前景与背景Anchor,标记标签(1 正例, -1 负例,0忽略)
- 正例:对于每一gt box,交并比最大的 anchor、与任一 gt box交并比超过一定阈值(0.7)
- 负例:与所有gt boxes交并比小于一定阈 值(0.3) 其他忽略
-
对每一前景anchor,根据对应的gt box计算回归值
回归值的计算,使得框框的位置挪到一个更精确的位置
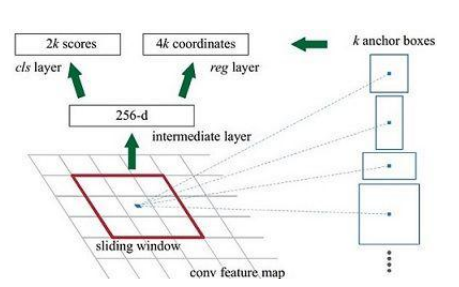
5.RPN(Region Proposal Network)
目的:判定哪些anchors有可能包含物体。
输入:所有的anchors (数量巨大)
输出:(1)包含物体的概率
(2)调整anchors的位置
anchors人工标定的9种大小,RPN把背景区分出来
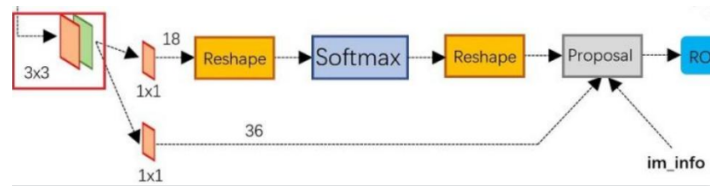
- 上面一条用softmax分类anchors获得positive和negative
- 下面一条用于计算对于anchors的bounding box regression偏移量
- 最后的proposal获取positive anchors的正确proposal, 剔除太小和超出边界的 proposal
生成检测框是非常耗时的,例如使用SPP(金字塔特征获取)
6.正负样本的判定

9*2=18
7.Bounding Box Regression
- 我们的目标是寻找一种关系,使得输入原始的anchor A经过映射得到一个跟真实窗口G更接近的回归窗口G’。
- Anchor box与predicted box, ground truth之间的平移量:
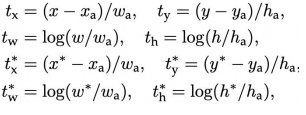
- VGG输出50x38x512, 对应50x38xk个anchors
- RPN输出:
- 50x38x2k的positive/negative softmax分类特征矩阵
- 50x38x4k的regression坐标回归特征矩阵
8.Proposal Layer
- Proposal Layer负责综合变换量和positive anchors, 计算出精准的proposal。
- 3个输入: anchors分类结果,对应bbox的变换量和缩放信息
- 缩放信息:若经过4次pooling后WxH=(M/16)x(N/16),则缩放量为16。

处理流程:
- 生成anchors,依据变换量对所有的anchors做bbox regression回归。
- 按照输入的positive softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors。
- 限定超出图像边界的positive anchors为图像边界,防止后续roi pooling时proposal超出图像边界。
- 剔除尺寸非常小的positive anchors。
- 对剩余的positive anchors进行NMS。
- 之后输出proposal=[x1, y1, x2, y2],对应的是MxN的图像尺度。
生成anchors -> softmax分类器提取positvie anchors -> bbox reg回归positive anchors -> Proposal Layer生成proposals
9.Roi pooling
- 目前的proposals还 没有具体的物体信息。
- 因此需要从已有的 bounding boxes中 提取特征。
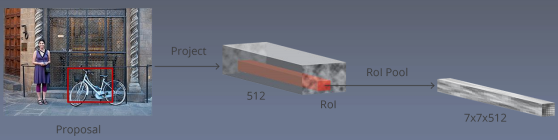
两个输入:
- 原始的feature maps
- RPN输出的proposal boxes
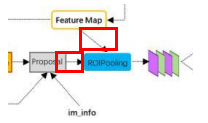
为何要RoI Pooling
- proposals大小形状各不相同
- 从Spatial Pyramid Pooling发展而来

信息的丢失
图像的失真
处理步骤: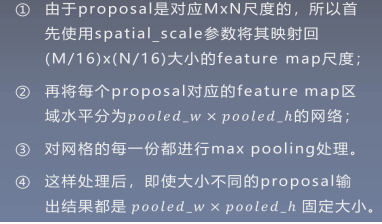
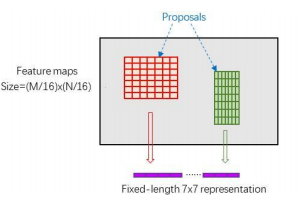
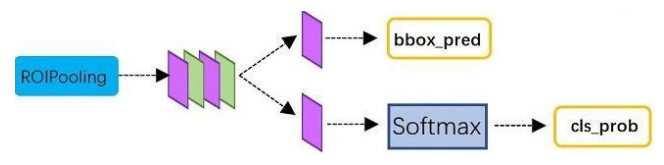
10.分类
- 通过全连接和softmax对proposals进行分类
- 再次对proposals进行bounding box regression,获 取更高精度的bbox
11.Faster RCNN的训练
- 训练RPN,该网络用ImageNet预训练的模型初始化;
- 我们利用第一步的RPN生成的建议框,由 Fast R-CNN训练一个单独的检测网络,这个检测网络同样是由ImageNet预训练的模型初始化的;
- 我们用检测网络初始化RPN训练,但我们固定共享的卷积层,并且只微调RPN独有的层, 现在两个网络共享卷积层了;
- 保持共享的卷积层固定,微调Fast R-CNN的 fc层。这样,两个网络共享相同的卷积层, 构成一个一的网络。
12.网络总结
- 基于ZF或VGG16提取输入图像特征
- 生成anchors
- RPN计算:特征图feature map通过RPN预测anchor参数:置信度 (foreground)和转为预测框的坐标系数
- 根据anchors和RPN预测的anchors参数,计算预测框的坐标系数, 并得到每个预测框的所属类别labels。
- ROI Pooling把目标转为统一的固定尺寸。
- Fast RCNN 预测预测框的类别,和转为目标框的平移缩放系数。注意:这里要与RPN区分.