[目录]
- 第一章:概述
- 第二章:整体数据分层
- 第三章:整体实现框架
- 第四章:元数据
- 第五章:ETL
- 第六章:数据校验
- 第七章:数据标准化
- 第八章:去重
- 第九章:增量/全量
- 第十章:拉链处理
- 第十一章:分布式处理增量
- 第十二章:列式存储
- 第十三章:逻辑数据模型(数仓模型)
- 第十四章:数据模型参考
- 第十五章:维模型
- 第十六章:渐变维
- 第十七章:数据回滚
- 第十八章:关于报表
- 第十九章:数据挖掘
数据仓库实践杂谈(四)元数据
不管在数据仓库还是大数据领域中,元数据都是最重要的一个东西。
元数据被定义为:描述数据的数据,对数据及信息资源的描述性信息。
概念很抽象。简单来说,你要处理的业务系统各有一套表结构,分别是T1、T2、T3等,合起来叫T。现在建立另一套表M,用来描述所有的T——每个系统有多少表、什么表,每个表有多少字段、什么字段,每个表都做什么用的,从哪里来的,怎么进来的,以及每个字段都是什么类型,取值的约束等。总之描述你要处理的数据是什么,以及如何处理这些数据的参数,都可以算元数据。这个定义只少不多,一切跟你需要处理的数据相关的参数、配置都可以算元数据。元数据驱动,换句话来说就是把元数据当参数,参数化驱动程序。
所以在设计数据处理程序的时候,最重要的特点就是针对元数据设计程序,而不是针对数据本身设计。程序跑起来的时候,数据是什么样,其实是不太关心的,只要元数据定义是对的就行。
然后那些什么OR-Mapping,什么Mybatis,基本上,跟我们关系不太大了。因为我们要处理的数据都会认为是动态的,内容动态,结构动态,一切依赖元数据的定义。
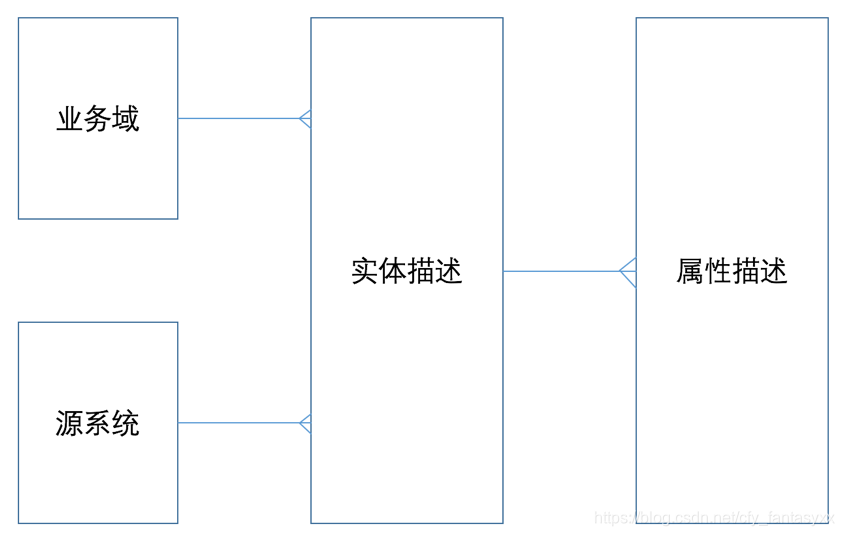
具体来说说元数据怎么定义。一个典型的定义如下:
- 业务域:描述系统都包含哪些业务范畴,比如,贷款、存款等;
- 源系统:数据来源于哪个系统,如何从该系统获取数据等;
- 实体描述:系统包含的表的描述,标准化的名称、编码,属于哪个业务域,来自哪个系统等,以及表的数据如何加载等;
- 属性描述:对表中的字段进行描述,属于哪个表,字段的取值约束、校验规则以及特殊业务含义等;
- 数据映射:每一区域的数据(表和字段)和下一区域的数据的映射关系。
根据需要,可以不断的扩展元数据的内容,从数据的业务含义、处理规则、使用规则等。
元数据能干嘛,或者怎么使用?可以从以下几个方面考虑:
- 定义每张表的数据如何获取,并且如何进入下一层。比如某系统提供的TXT文本文件,可以定义从哪里获取(FTP地址、路径、URL等)这个文本文件,文件格式(分隔符、定长),该文件加载到全量明细区是哪个表(从源到全量明细区认为是一一对应的);
- 定义每张表的数据的加载规则,比如全量、增量、拉链等模式;
- 定义数据的校验规则,比如取值范围(数值范围、字典集合)、是否可空、字段长度、数据类型等;
- 定义数据的特殊业务含义,比如划分权限的字段,业务关联等。
- 数据映射关系:也称为Mapping,主要在一个区域转到另一个区域(比如从全量数据区到数仓模型的整合区),字段级别的映射关系;
- 数据关联:数据的关联跟数据本身同样重要,类似外键,一张表通过某个字段能关联到另外一张表(同一区域/上下区域),对于分析数据非常有价值。
可以说,完整的元数据可以控制数据生命周期中的所有操作,也可以依据此记录数据的所有变化过程。但是,要知道,数据的处理是非常复杂,存在各种情况的,如下图所示。
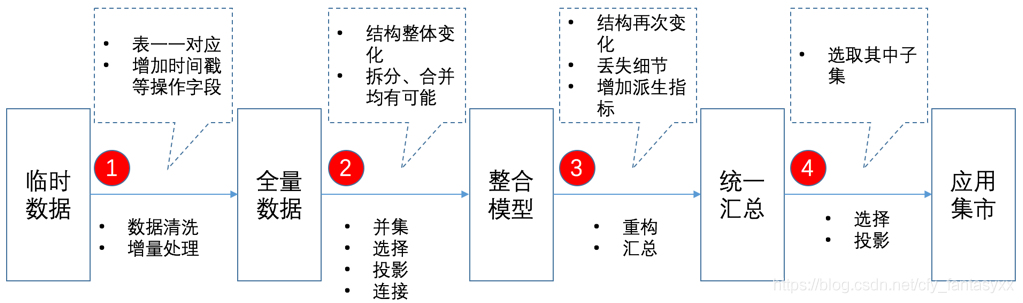
从逻辑上,我们应该可以知道两个数据应该有关系,但确实很难形式化的描述这个关系,或者能描述但是层次太深导致不实用。这是所谓的“数据血统”。因此不得不说Mapping这个东西。Mapping一度是个利器,尤其是在可视化商业工具(如Informatic)中,拉出源表,拉出个目标表,然后系统匹配快速的自动映射出里面的所有字段。具体来说:
- 操作1中,数据结构基本不会改变,仅仅是在表上增加时间戳或者拉链的标记字段,业务内容的字段可以认为是平移过来;此处机械地逐个字段映射,不如用元数据直接参数化配置;
- 操作2中,关系运算中的并集、选择、投影和连接都会使用,也就是数据的合并、拆分以及字段的合并和拆分。也就意味着某一个字段可能因为数据处理而变成了两/多个字段,或者两/多个字段合并成一个字段,如果数据处理的层次多了,这个关系就会变得非常复杂;
- 操作3中,业务细节丢失,可以基本上认为无法跟踪了,或者是一种“公式”(一般是加减四则运算及类似sum的汇总函数)才能描述的关系了。所以这里更多是规范化指标的计算公式,或者统计口径。
很多人也会问,很多应用其实是基于明细的报表为主。如果不考虑汇总层,到了整合层就可以了,是否就能溯源跟踪呢?还是那句话,理论上可以,但是实际操作上,成本很高。以银行为例,一个银行上百个系统,每个系统多的超过100张表,少的也有二三十张,基本上就得有三千张表以上,每个表10个字段也都有3万个字段以上了。每个分区都要映射,尤其整合层到形成报表可用的表,往往一次转换还不行,不同指标会使用同样的数据来计算,反复叠加起来计算,近似无穷的字段映射,不管用什么方式来管理都是成本相当高的。往往结果就是一开始心气很足,规划很宏伟,但过程中就脱节了,映射配置和实际处理对应不上。毕竟通过这样的映射来做一个报表,远没有直接写一段存储过程或者JAVA程序快捷方便的多。别怪大家不守规矩,做一个报表时间短、压力大,能做出来就不错了。
业务人员来做报表,这永远只是神话。
其实我认为,懂技术的人,学点业务会更容易一点。毕竟在这方面我们不关心业务流程,只需要关心数据结构和数据含义。而业务人员学技术,基本上不太现实。
还有一点,这种溯源基本上只有技术人员关注,一般都是报表计算出问题了,回头去找对应的数据从哪里来,统计口径是否正确,原始数据是否正确。所以搞不好就是业务不买单,技术不需要。
那如何管理所有的映射过程呢?在后面会讨论ETL的框架和特点。
关于数据的关联,某种程度上有点像数据的映射。但所站的层面应该更高,应该站在业务的层面分析数据的关联。这其实涉及到一些“主数据”的概念。比以典型的信贷业务为例,用户往往会希望查询到一份贷款合同之后,希望看到签订该合同的客户资料以及贷款项目、借据、放款记录以及还款记录等内容,而这些内容都会在另外的表中。通过“业务外键”的关联,可以把这些内容都串联起来。甚至可以从汇总层某客户贷款中总金额指标追溯到此金额由几笔贷款合同组成。
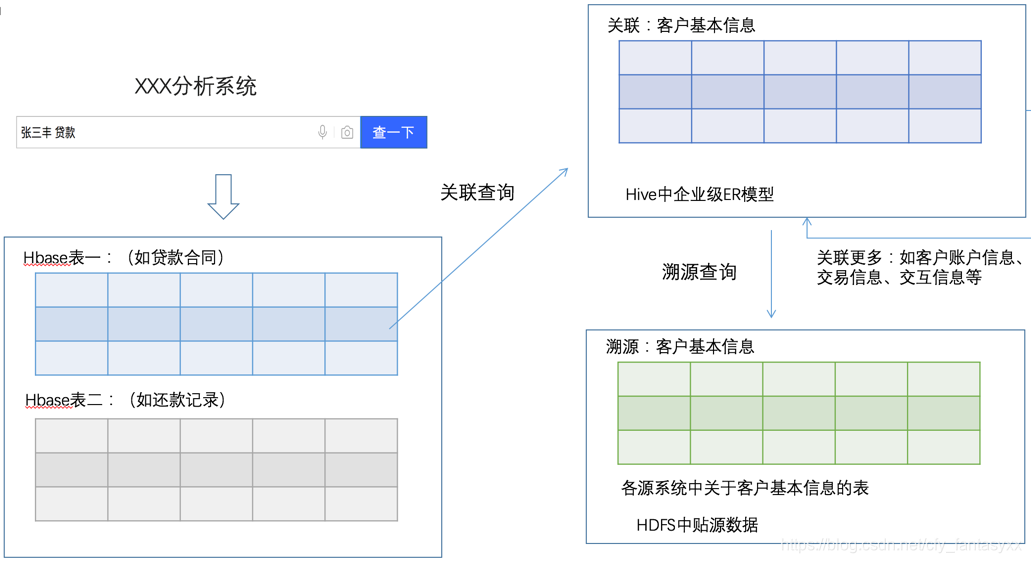
在同一个数据区域中,通过数据关联把每个业务实体组成了一个网络,或者一张有向图。如果打通其他数据区域,就变成一个立体的数据关联空间。
从业务的角度提供溯源机制,会更加得到业务人员的认同和支持。上图例子翻译成业务语言就是,查询到了某人的贷款合同/记录之后,需要进一步看一下客户的资料,系统先提供一个整合的客户信息视图给用户,但用户还想进一步看,比如该客户在信贷系统的资料,以及在核心系统的资料。
最后,要强调的是,上面说的所有功能,都应该基于元数据去开发,不能在程序中写死。这也是元数据的最大作用。说白了,元数据是一个有一定规范的参数。关于元数据有很多学术上的论著以及规范,其中最出名的是对象管理组织OMG提出的一些列规范,从1995年采用了MOF(Meta Object Facility),1997年采用了UML,2000年,OMG又采用了CWM。之前有一段时间专门做元数据,但到最后,感觉几乎是在做学术研究,之后也基本不记得都做了什么了。剩下的感觉就是曲高和寡。明明不复杂的东西,搞得没人弄的懂。到了现在,给做数据仓库的同学的建议就是做一套表,然后不断升级,丰富就可以。至少在应用基本,元数据最重要的是用起来,而且要贯彻在系统的每一个地方。这才是关键,至于那些规范,真有闲暇可以去看看。
未完待续。
