[目录]
- 第一章:概述
- 第二章:整体数据分层
- 第三章:整体实现框架
- 第四章:元数据
- 第五章:ETL
- 第六章:数据校验
- 第七章:数据标准化
- 第八章:去重
- 第九章:增量/全量
- 第十章:拉链处理
- 第十一章:分布式处理增量
- 第十二章:列式存储
- 第十三章:逻辑数据模型(数仓模型)
- 第十四章:数据模型参考
- 第十五章:维模型
- 第十六章:渐变维
- 第十七章:数据回滚
- 第十八章:关于报表
- 第十九章:数据挖掘
数据仓库实践杂谈(五)ETL
ETL是建立数据仓库的核心,也是工作量最大的部分。所谓ETL,前面也提到过:Extract-Transform-Load的缩写。抽取-转换-加载。也就是从源系统抽取出来,经过一系列的加工(变形),最后加载到数据仓库中。只要做过数据加工的人都会知道,这个Transform(转换)过程实际上是由很多处理步骤有顺序、有条件的组成的。
ETL平台应该包括如下几个基本功能:
- 可以从不同的数据源抽取数据,支持多种数据库,从多种存储介质或文件系统中读取文件等。
- 管理数量众多的转换程序,可以清晰的知道每个程序是做什么的。
- 支持调用自定义的扩展处理程序。
- 支持转换程序的有机组合,跟工作流一样,可以按顺序、分支、同步等。
- 支持把数据加载到不同的数据存储系统。
上面只是最基本的功能,实际上,针对大量数据的处理过程,往往需要考虑集群,实现分布式的数据处理。比如:
- 横向扩展的工作节点管理,异常恢复、错误转移等。
- 提供图形化的界面以便设计处理流程。
- 内置众多数据处理功能。
这就是一个很复杂的系统了。我们一般都说,一个系统基本上只有20%的代码是实现正常的、基础的功能,剩下80%的代码都是处理异常和提升体验的。
早年流行的ETL工具基本上就是Informatic和DataStage的天下了。价格昂贵。当然,他们非常强大,图形化界面做的非常好,拖拖拽拽就能完成基本的ETL开发,元数据管理能力强大。还有很多其他功能,比如数据映射、血缘跟踪、各种常规处理模式的支持等。那时候做数据仓库的同学们基本都有个梦想,自己做一个很好的ETL工具。感谢开源社区的发展,现在有了非商业软件的选择,而且基本也不需要自己做了。
比较成熟、出名的开源ETL工具,大概应该就是Kettle和Airflow了吧。都很好的工具,支持大数据,支持分布式,有图形化界面。我认为最大的差别就是Kettle是Java的,Airflow是Python的。Python现在很流行,做数据处理很渐变,但对于喜欢Java的老程序员来说,通过Python调用Java的处理程序,就麻烦一点了。
顺带提一句,Kettle是Pentaho公司出的,Mondrian也是这公司出的。后面会提到,这是当年很厉害的一个ROLAP开源工具。
下图是kettle的一个例子:
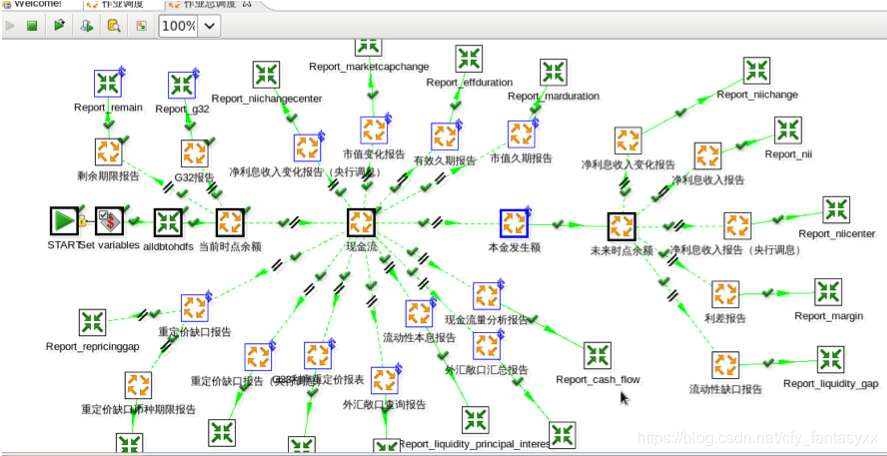
目前相对完善的ETL开源产品都是某个公司开源出来的,并不是开源社区支持的。是否适用,确实看自己的想法了。当然,有些人把一些数据加载工具(如Sqoop),数据管道工具(如Kafka)等也认为是ETL工具。而我认为这只是ETL的一部分吧,在实现ETL过程中可以去用,但并不是ETL的全部。当然,在特定场景,比如数据要求实时性高,处理不复杂(直接加载),也有人认为Kafka才是数据处理的未来。
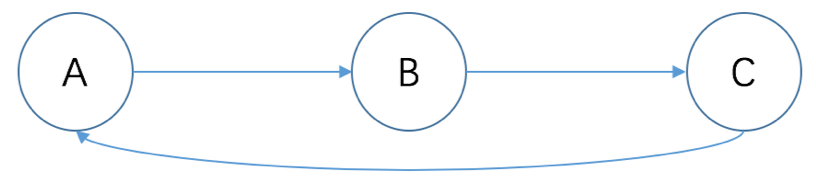
不管如何,ETL的一个核心就是定义处理任务的时序。其实就跟工作流一样。但一般用于OA(办公自动化)的工作流每个步骤基本都是人参与的,而数据处理的流程一般都是静默执行的。这就产生了一个现在流行的词——有向无环图(DAG)。高深的数学理论不去说它,所谓有向,就是两个节点之间是有方向的,从A到B就不能从B到A。而无环,则要求无回路,比如A到B,B到C,C回到A,就是回路了。有回路则会造成死循环,毕竟图形化的流程定义很难做到根据程序执行的各种情况来决定往前走还是回去。而且,重新执行前面的步骤,可能对已有数据来说是个灾难。
ETL工具一般都提供了大量的内置处理功能,比如数据的映射(Mapping),也就是从一个表的某个字段对应到另外一张表的一个字段。还有类似投影、选择、联合union、连接join等操作。但实际处理中用的很少。绝大多数的数据转换都是用通过自己的一个程序(基于元数据驱动)来处理。至少我们的实际经验是这样,完全机械的一对一的映射,一个简单的程序搞定,不需要拖拽半天;复杂的映射拉一条线还得关联一个自定义程序。
所以我们可以说,大部分成功的平台的数据处理过程都是由多个数据处理程序片段组成的。通过ETL调度工具调度执行对应的程序。然而这样的处理程序可能会有很多,比如银行的数据仓库平台会有上千个都不止的处理程序。管理好这些程序非常重要。
所以,我们可以把关注点放在管理好众多的处理程序片段。一个好的数据处理程序片段应该具备如下特点:
- 功能纯粹:算一个指标就算一个指标,处理一张表就一张表,不要把过多的事情放在一个程序里面去做,可以通过简单的描述就能清楚做什么;
- 元数据驱动:尽量在利用元数据作为参数开发,避免硬编码表或字段名称,甚至常用的指标处理公式也应该参数化;
- 明确输入输出:输入的是什么数据,输出什么数据,都可以形式化地明确定义;
- 自带回滚功能:发生错误之后如何处理,自己回滚,还是调用公共的回滚程序等,但必须有对应的回滚程序或机制;
不用担心程序太多运行麻烦,ETL调度工具就是用来干这个事情的。要关心的是如何有效管理这么多程序,让团队都明白,以及后续接手的人都明白每一个程序是做什么的。实践告诉我们,指望先写好一套程序说明文档然后再开发程序,或者反过来,都是无效的,最终结果都是项目没做完,文档和程序就对应不上了,费力气弄出一堆垃圾了。
好在现代软件技术给了我们很好的工具。使用类似Swagger工具,在开发代码的时候按照一定的规范写好注释,然后生成接口文档,最后把文档转换成元数据内容。这样可以最大程度保证文档与程序的一致性,只需要保持程序员的良好编程习惯——写程序带注释即可——无需额外增加文档工作量。
未完待续。
