[目录]
- 第一章:概述
- 第二章:整体数据分层
- 第三章:整体实现框架
- 第四章:元数据
- 第五章:ETL
- 第六章:数据校验
- 第七章:数据标准化
- 第八章:去重
- 第九章:增量/全量
- 第十章:拉链处理
- 第十一章:分布式处理增量
- 第十二章:列式存储
- 第十三章:逻辑数据模型(数仓模型)
- 第十四章:数据模型参考
- 第十五章:维模型
- 第十六章:渐变维
- 第十七章:数据回滚
- 第十八章:关于报表
- 第十九章:数据挖掘
数据仓库实践杂谈(六)-数据校验
从数据源卸载出来的数据,进入仓库之前的第一个步骤就需要进行数据校验。数据校验的前提是在元数据中建立一套合适的数据标准。而其中,最重要的是确定每个字段的取值范围。基于这个数据标准,同步建立一套程序用于检查将要进入仓库的数据的有效性。
这套程序不但在运行阶段每日检查,在数据分析阶段也会用来做数据质量的检查。
数据的取值范围一般包括如下几种:
- 是否可空;
- 数值的取值范围:整数/小数点,取值起止范围等;
- 取值的枚举范围;
另外,还需要考虑数据是否有重复,乱码之类。对于从一些老旧系统导出的数据出现这个问题的可能性较大。
数据校验是最容易通过元数据驱动实现的模块。一般情况都应该利用元数据开发一套通用程序来处理。
数据校验的输出有以下三个:
- 验证正确的数据,进入加载处理(增量/全量)环节;
- 校验不通过的数据,进入到脏数据区,一般情况脏数据都需要人工介入处理;
- 生成数据质量报告,包含每个表、字段的空值率,有效率等。
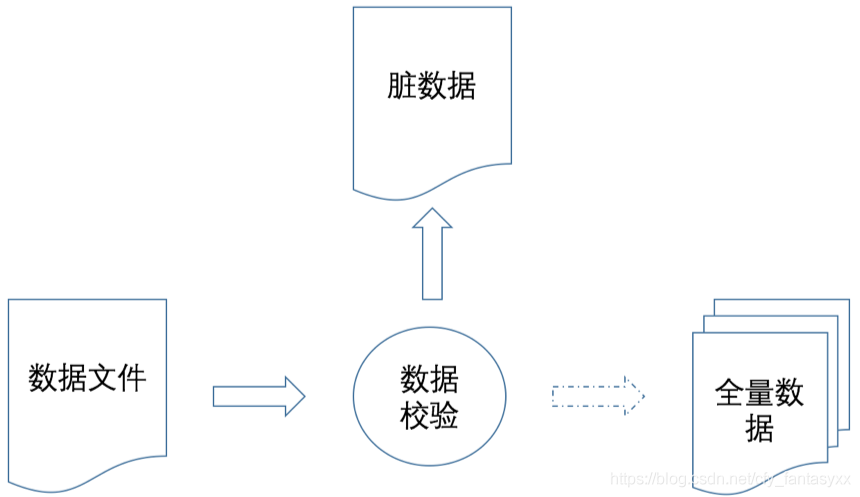
数据校验类似一个过滤器,让符合条件的数据往下走,同时抓出不符合条件的数据。这里有一个核心的问题需要优先考虑:
一份数据文件里面存在脏数据之后,是否还继续往下处理?
首先明确一点,大部分的数据问题,是系统无法自动解决的。只有类似FTP下来的数据文件不完整,可以去尝试重新下载之外,别的基本上没办法自动处理了。一般来说,可能会出现下列的错误类型:
- 网络错误:导致文件传输不完整、错位、乱码等;这类错误基本会导致文件无法解析,一般进行重试,或者直接报警,手工更新文件之后重新执行。
- 数据卸出系统错误:源系统卸出数据文件程序发生错误,导致文件不完整、错位、乱码甚至生成文件失败等,此类错误一般也会导致文件无法解析,需要立刻安排检查源系统程序重新生成文件。
- 数据错误:比如特定字段给了非法的值。这类错误往往是因为源系统业务流程或者数据校验不完善导致出现非法数据。然后,这种错误不是立马可以修复的。当然,在一个正常运作的系统,这类的错误往往只会占少数。
一般情况,有数据错误的文件,建议是把错误数据筛选出来之后,继续执行。停止一个文件执行对整个流程的伤害是非常大的,很可能整个流程都会停下来。毕竟,大部分业务数据文件,其中只会有一小部分数据有问题,只会影响部分业务的分析结果。
当然,如果发生系统性错误,经过自动重试仍失败,就需要停下流程,立即报警,马上处理。
重点考虑第三种问题。某个文件发现了部分不合规的数据,把违法数据单独保存起来,剩下的数据继续进行处理,进行增量处理以及后续相关的处理。正常数据的后续流程,从增量到建模到分析,后续章节会继续讨论。这里主要讨论异常数据怎么处理。
一般情况,或者说几乎所有的情况了,异常数据都是需要人工介入处理的。一般处理流程:
- 检查异常数据,对比源系统数据;
- 追溯业务起源,确定正确内容;
- 最后的选择:
- 在源系统修复数据重新导出;
- 在专门的界面修复异常数据;
- 直接无视。
数据的修复,别指望当天可以完成。一般都得好几天。源系统修复和升级,更不是短时间内能做到了。如果在确定不影响业务的情况下,可以把异常数据给一个专门的类别,比如某个分类字段,业务限定只能有01、02和03三个值。现在来的数据发现一个06。可以保留这个06。但如果这个字段存在层次汇总的话,需要设置成一个专门的类别来表示其他的值,比如99。把异常的数据都汇总到99上。
数仓平台一般都提供一个错误数据修复(补录)的界面。首先把不合法的数据,装到单独的数据库里面(便于检索和修改),然后提供一个界面,展示每一条违法数据。这个界面,严格按照元数据的定义来校验数据,避免造成二次错误。修复数据之后,重新生成一个数据文件/表重新进行数据处理。假设这个数据为D,只有T日处理中校验出来的违法数据,其他合法数据已经处理到仓里里面去了。
按如下策略执行:
- 重新进行数据校验,尤其是源系统重新导出的数据;
- 重新执行增量处理,但需要把处理日期设置为T,同时关闭对删除
- 数据的判断(也就是和全量文件对比,缺少的数据忽略即可,不认为是源系统删除了此数据);
- 增量式处理数仓模型数据(如果有的话);
- 维模型(星型模型)表,一般仓库的基础表只会保存最明细粒度的事实表,需要重新计算当日的事实表数据。
- 之后高层次的汇总分析集市部分,简单粗暴的,干掉重新生成吧。
如果是通过源系统自行修复之后重新导出数据的话,则有两种情况:
- 导出当日全天的数据,需要先行用保存下来的异常数据对比一下,把修复好的异常数据单独拿出来执行上面的流程;
- 如果导出的只有修复之后的错误数据,则直接执行上面的流程。
基于明细的表,包括全量历史表和数仓模型表,以及最明细粒度的维模型事实表,其结构都是支持增量叠加和修改某一天的数据。所以只需要确定处理的数据日期,重新执行一般来说问题不大的。但再往后,比如分析集市,其数据经过汇总的,就不一定很好进行处理了。但类似分析集市一类的数据,往往都不会单独保存在数据库或者自己设计的数据结构中了,都会使用专用工具,比如Cognos之类,不但数据需要汇总,还会压缩等。所以这部分数据,基本就是直接重建了。
需要注意的是,这里说的异常数据,主要是流水表,订单表这种业务发生记录的数据。如果是机构表、地区表之类的数据有错误,一方面一般程序自动校验不出来,另一方面涉及到统计维度,造成的问题会很严重。
所以:
- 数据尽量不要错;
- 仓库提供回滚机制,能恢复到一定期间内指定日期的样子。
未完待续。
