[目录]
- 第一章:概述
- 第二章:整体数据分层
- 第三章:整体实现框架
- 第四章:元数据
- 第五章:ETL
- 第六章:数据校验
- 第七章:数据标准化
- 第八章:去重
- 第九章:增量/全量
- 第十章:拉链处理
- 第十一章:分布式处理增量
- 第十二章:列式存储
- 第十三章:逻辑数据模型(数仓模型)
- 第十四章:数据模型参考
- 第十五章:维模型
- 第十六章:渐变维
- 第十七章:数据回滚
- 第十八章:关于报表
- 第十九章:数据挖掘
数据仓库实践杂谈(十)——拉链处理
现代业务系统处理的数据越来越大,尤其大型金融机构、电商平台等,账户表,订单表都是庞大的。数据仓库要保留历史变更情况,需要每天加载当天的变更数据到仓库。相比整个全量数据来说,每天变化的数据还是属于少数的。比如千万账户级别的银行每天交易量一般也就是几十万条,也就意味着账户表中涉及变动的记录最多也就是几十万条。电商订单表可能数千万条,但每天新增以及之前订单变化的,可能不到一百万条。这种情况下,拉链方式做增量存储是最合适的方法。
考虑到大部分源系统只是单纯的交易系统,并不会预先做增量的处理。所以,往往我们面对的场景是源系统每天给一份当前系统的快照(包含所有或者有效时间内的订单),这里面有大量没有被修改以及小部分被修改过的、新增数据。这样我们需要做的事情就有两件:
- 找出增量(新增、变化)的数据;
- 把增量数据追加到历史库中。
考虑历史数据库的存储情况,先把关于拉链表的表示方式详细阐述:
- 首先,对于当前生效的记录截止日期可以设定为9999-12-31,基本上就是地球末日的日期;查询当前生效的记录,可以用截止日期等于9999-12-31来作为条件;这样也能减少全量对比的工作量;
- 一般来说,全量数据存储每天一个分区;当天数据对比之后把变更的数据所在分区的数据全部拿出来(也就是A日有一条数据变更了,把仓库里A日分区的数据全部拿出来),和新增数据合并成临时表;把涉及变更的分区删掉,重新插入。用“删除+插入”代替“更新”操作。
- 全量数据区可以反映任意时间点的业务状态,也就是给定任意日期,可以还原出指定日期的业务情况,记录数据的有效期有开始日期和截止日期就比较容易做到这点。
按一般情况,数据每天处理一次,T+1数据进入仓库。也就是2号仓库处理的数据是1号的。
利用一个典型的订单表为例:

一个简化的订单表内容。其中状态包括:下单、支付、发货、收货四种。订单数据创建的时候,形成了订单编号、订单内容,状态为“下单”,记录下单时间,其他字段留空。这样意味着,该订单每次状态发生变化,“状态”字段会被修改,对应的支付时间,发货时间和收货时间等内容会增加(也是修改,从空改为对应动作的发生时间)。为了简化起见,我们假定订单状态每天变化一次。
在全量历史表里面,根据拉链表的定义,我们把结构改成如下:

增加了流水号,开始时间、截止时间和状态(新增、修改、删除)。
假设每天一条新增订单,订单状态每天变化一次。
当前全量表的数据如下(A表):
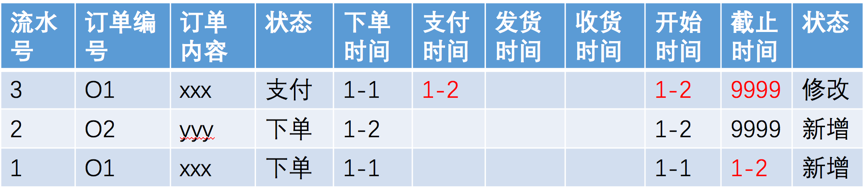
1月3日业务结束,一般业务系统会在1月4日凌晨开始做数据导出的动作,然后把数据传送给仓库。1月4日拿到3日(T-1)的数据(B表):

当前系统日期是4日,处理的业务日期是3日。也就是本次处理新增或变更的的有效期开始是3日,而历史数据中被变更的记录有效期截止日期是2日。
3日数据中,可以分成如下三部分:
- 当日新增的订单;
- 之前的订单状态发生了变化的;
- 没有变化的订单。
根据元数据配置,“下单时间”字段为时间戳,此字段值为T-1(下单时间为3日,T为系统日期)的,可以直接判断是新增记录,因此这部分数据可以直接先拿出来,插入到仓库表中。
剩下的数据,则需要找出那些记录发生了变化。由于给过来的数据只有当前状态的快照,从快照表本身无法知道那些记录变化,需要和历史表中数据进行对比才可以。如果在关系数据库中处理,并不复杂,只需选出全量表中有效截止时间为9999的,然后两表的订单号关联,并且找出所有字段内容不相同的记录。
但对数据库有所了解的人都应该知道,这样会非常非常慢,尤其数据量很大的时候。可以使用分布式的思路来处理,把数据分区保存,分布处理。这个后面介绍。
这里重点说一下如何比较“异同”。一般这种业务表的字段很多,逐一字段比较很耗费时间。一个比较好的做法,是通过Hash算法(散列)快速比较,也可以选择通用的MD5,下面都用Hash来表示。所谓Hash算法是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值。但要记住,这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。也就是Hash值不同的记录,内容肯定不同,但Hash值相同的记录,还得具体比较里面的内容。
具体做法就是在全量表中增加一个字段,记录原始业务字段按特定顺序(如字段的拼音字典值,一定要固定顺序)拼接而成的长字符串计算所得Hash值。当日快照表也增加一个字段,每条记录也按照相同的顺序拼接后计算Hash值。对于同一个订单号且全量表中有效截止日期为9999的记录,比较Hash值,如果不同,那就是有变化,如果相同,再具体比较里面字段是否真的相同。
这种做法对于变化越多的数据,优势越明显。
比较完成之后,处理结果数据有三种:
- 需要进到全量表的变化来的订单数据;
- 全量表中由于数据变化了需要修改有效截止日期的数据;
- 没有变化的数据,即当天没有变化的订单。
如下表(这里不包含3日新下单的数据):
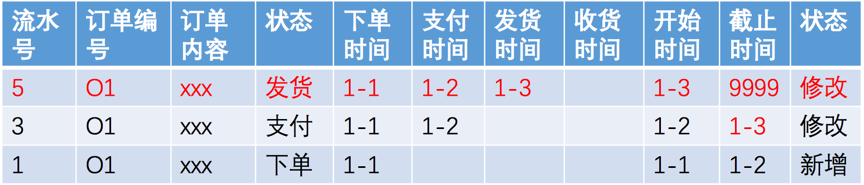
记住,全量表是不能改变的。因此,需要形成一个上表一样的临时表,然后,把全量表中1号的分区删掉,然后,把上述临时表插入进去。当然,可以把Hash字段也加上。每个分区都处理完,就形成了最终的全量表。
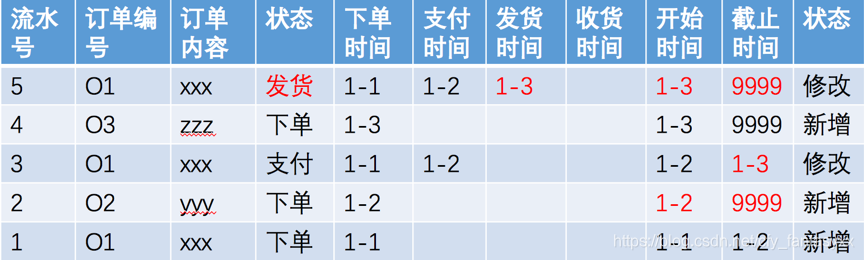
再提一句,Hash算法对变化多的分区效果明显,但对于没有数据变化的分区,则没有效果,必须全部字段比对一次才能确定。对于订单表这种场景,变化主要集中于最近的日期,比如,最近一个月内。更远的订单,基本上修改的几率非常低。所以对于订单表这种形式的数据,最好能从业务上确定订单变更的最长周期,比如过了退换期,则不可以改变了。维保等后续售后服务用单独的表来记录。否则会很消耗增量处理的时间。
未完待续。
