1. 算法概述:
聚类是一种无监督的学习,它将相似的对象归到同一个簇中。它有点像全自动分类。聚类方法几乎可以应用到所有对象,簇内的对象越相似,聚类的效果越好。
K-means称为K-均值,是因为它可以发现k个不同的簇,且每个簇的中心采用簇中所含值的均值计算而成。
1.1 算法特点:
优点:容易实现
缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢
适用数据类型:数值型数据
1.2 工作流程:
K-means是发现给定数据集的k个簇的算法。簇个数k是用户给定的,每一个簇通过其质心(centriod),即簇中所有点的中心来描述。
K-means算法工作流程如下:
首先,随机确定k个初始点作为质心。然后,将数据集中的每个点分配到一个簇中,具体来讲,为每个点找距其最近的质心,并将其分配给该质心所对应的簇。这一步完成之后,每个簇的质心更新为该簇所有点的平均值。
伪代码表示:
创建k个点作为起始质心(经常是随机选择)
当任意一个点的簇分配结果发生改变时
对数据集中的每个数据点
对每个质心
计算质心与数据点之间的距离
将数据点分配到距其最近的簇
对每一个簇,计算簇中所有点的均值并将均值作为质心
K-means聚类的一般流程:

import numpy as np
#数据集X,K=?,停止条件:聚类结果不变,变化不大,提前预设迭代次数maxIt
def kmeans(X,k,maxIt):
#shape方法获取行数列数
numPoints,numDim = X.shape
#多加一列(label列)
dataSet = np.zeros((numPoints,numDim+1))
#除了最后一列 其他的内容与X一样
dataSet[:,:-1] = X
#一共numPoints行,从中选择k行,取其所有的列
centroids = dataSet[np.random.randint(numPoints,size = k),:]
#假设初始质心为前两列的值
centroids = dataSet[0:2,:]
#为新加的最后一列进行初始化为1,2,...,k
centroids[:,-1] = range(1,k+1)
iterations = 0
oldCentroids = None
#当不满足停止条件是进行下列操作
while not shouldStop(oldCentroids,centroids,iterations,maxIt):
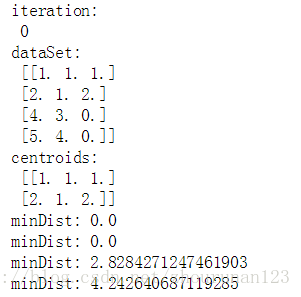
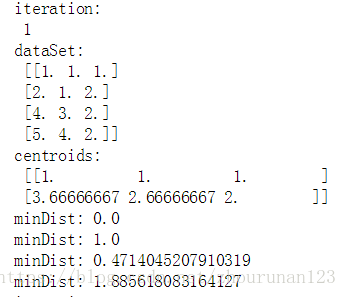
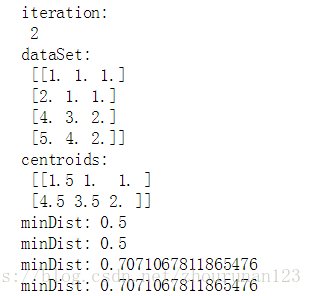
print("iteration:\n",iterations)
print("dataSet:\n",dataSet)
print("centroids:\n",centroids)
oldCentroids = np.copy(centroids)
iterations += 1
#重新划分标签
updateLabels(dataSet,centroids)
#更新质心
centroids = getCentroids(dataSet,k)
return dataSet
def shouldStop(oldCentroids,centroids,iterations,maxIt):
if iterations > maxIt:
return True
return np.array_equal(oldCentroids,centroids)
def updateLabels(dataSet,centroids):
numPoints,numDim = dataSet.shape
for i in range(0,numPoints):
dataSet[i,-1] = getLabelFromClosestCentroid(dataSet[i,:-1],centroids)
def getLabelFromClosestCentroid(dataSetRow,centroids):
label = centroids[0,-1]
minDist = np.linalg.norm(dataSetRow-centroids[0,:-1])
for i in range(1,centroids.shape[0]):
dist = np.linalg.norm(dataSetRow-centroids[i,:-1])
if dist < minDist:
minDist = dist;
label = centroids[i,-1]
print("minDist:",minDist)
return label
def getCentroids(dataSet,k):
result = np.zeros((k,dataSet.shape[-1]))
for i in range(1,k+1):
oneCluster = dataSet[dataSet[:,-1] == i,:-1]
result[i-1,:-1] = np.mean(oneCluster,axis = 0)
result[i-1,-1] = i
return result
x1 = np.array([1,1])
x2 = np.array([2,1])
x3 = np.array([4,3])
x4 = np.array([5,4])
testX = np.vstack((x1,x2,x3,x4))
result = kmeans(testX,2,10)
print("final result:")
print(result)