**
机器学习之k-means的实现
**
# -*- coding: utf-8 -*-
"""
Created on Mon Nov 26 20:48:38 2018
@author: Administrator
"""
import numpy as np
def kmeans(X, k, maxIt):
'''
:param X: 数据集
:param k: 聚类个数
:param maxIt: 最大迭代次数
:return:
'''
numPoints, numDim = X.shape #返回数据集的行数与列数
dataSet = np.zeros((numPoints, numDim + 1)) #加一是想在最后一列增加类别
dataSet[:, :-1] = X #dataset最后一列还是0
# Initialize centroids randomly
centroids = dataSet[np.random.randint(numPoints, size = k), :] #挑选dataset中任意K行作为初始化聚类中心
#centroids = dataSet[0:2, :]
#Randomly assign labels to initial centorid
centroids[:, -1] = range(1, k +1) #初始化标记类别,即centroids最后一列是存储所属类别,即类别1,2,3,,,,
# Initialize book keeping vars.
iterations = 0
oldCentroids = None
# Run the main k-means algorithm
while not shouldStop(oldCentroids, centroids, iterations, maxIt): #返回True则不执行该函数
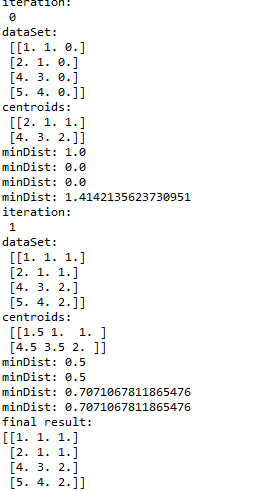
print ("iteration: \n", str(iterations))
print ("dataSet: \n", str(dataSet))
print ("centroids: \n", str(centroids))
# Save old centroids for convergence test. Book keeping.
oldCentroids = np.copy(centroids)
iterations += 1
# Assign labels to each datapoint based on centroids
updateLabels(dataSet, centroids)
# Assign centroids based on datapoint labels
centroids = getCentroids(dataSet, k) #求同一类中的所有点的均值作为新的聚类中心
return dataSet #返回一个矩阵,每一行代表一个实例,最后一列代表每个实例所属类别
def shouldStop(oldCentroids, centroids, iterations, maxIt):
if iterations > maxIt: #达到最大迭代次数则返回True
return True
return np.array_equal(oldCentroids, centroids) #若新的聚类中心与上一次的聚类中心相等,则返回True
def updateLabels(dataSet, centroids):
numPoints, numDim = dataSet.shape
for i in range(0, numPoints):
dataSet[i, -1] = getLabelFromClosestCentroid(dataSet[i, :-1], centroids) #将第i个样本的标签存储到dataset最后一列
def getLabelFromClosestCentroid(dataSetRow, centroids):
'''
计算某个样本与所有聚类中心 的距离,并得到距离最近的中心
:param dataSetRow: 第i个实例的特征,一行向量
:param centroids: K行,列数包含了标签
:return:返回所属标签
'''
label = centroids[0, -1]; #初始化一个标签,比如为1
minDist = np.linalg.norm(dataSetRow - centroids[0, :-1]) #计算一个样本与第一个中心点的距离作为初始最小化距离
for i in range(1 , centroids.shape[0]):
dist = np.linalg.norm(dataSetRow - centroids[i, :-1]) #计算传参过来的样本与所有中心点的距离
if dist < minDist:
minDist = dist
label = centroids[i, -1] #记录标签
print ("minDist:", str(minDist))
return label
def getCentroids(dataSet, k):
result = np.zeros((k, dataSet.shape[1])) #K行,所有列
for i in range(1, k + 1):
oneCluster = dataSet[dataSet[:, -1] == i, :-1] #dataSet[:, -1] == i,遍历i,找出所有等于i所属的行,返回索引值
result[i - 1, :-1] = np.mean(oneCluster, axis = 0) #axis=0 即对每一行所有列求平均值 如三行求出一行
result[i - 1, -1] = i #赋标签
return result
x1 = np.array([1, 1])
x2 = np.array([2, 1])
x3 = np.array([4, 3])
x4 = np.array([5, 4])
testX = np.vstack((x1, x2, x3, x4)) #组成一个矩阵
result = kmeans(testX, 2, 10)
print ( "final result:")
print (result)
结果