初探k-means(Matlab)
俗话说:“物以类聚,人以群分”,聚类分析的目的是:在数据中发现数据对象之间的关系,并将数据进行分组,使得组内的相似性尽可能大,组间的差别尽可能大,那么聚类的效果越好。
例如在市场营销中,聚类分析可以帮助市场分析人员从消费者数据库中区分出不同的消费群体来,并且概括出每一类消费者的消费模式或者说习惯。在机器学习中,聚类分析也可以作为其他分析算法的一个预处理步骤。
下面介绍诸多聚类算法中的K-means算法。
在机器学习与数据挖掘中,K-Means是一种cluster analysis的算法,属于无监督学习的算法范畴。K-Means算法简单,易于理解。其具体算法流程如下:
(1)随机从数据中选取K个元素,作为k个簇(这里可以理解为各个分类)中各自的中心。
(2)分别计算各个元素到这K个簇的距离,并将这些元素划归到距离最近的簇。这里可以认为距离越近,两者之间越相似。而不同距离的度量其聚类结果不同。这里提供了不同的距离参考。点击打开链接
(3)重新计算各个簇的中心点。例如取平均的方式。
(4)重复2~3步,直到迭代次数达到最大值或者中心点移动小于某个临界值(即认为已经收敛)。
下面利用Matlab具体进行讲解:
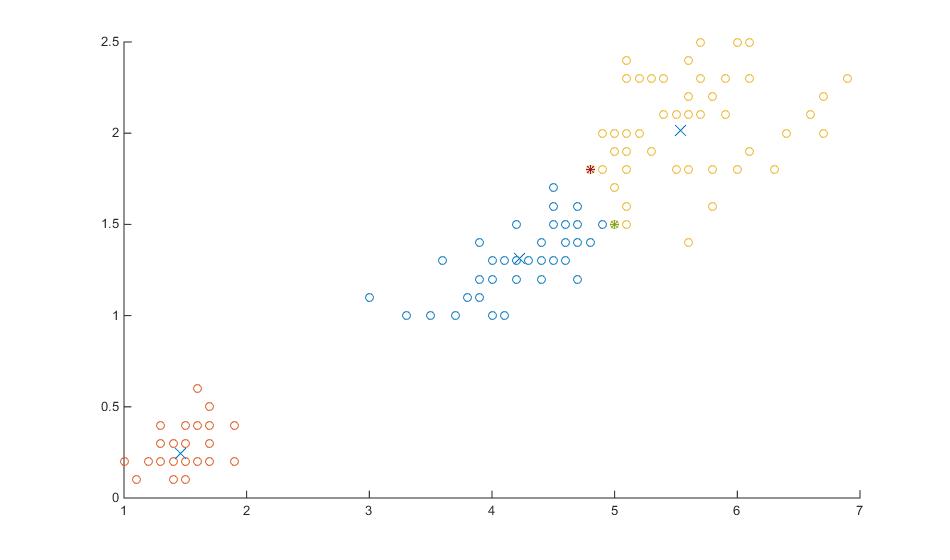
一、首先输入数据,这里选用Matlab自带的数据fisheriris,然后判断数据中是否含有异常值
clear
clc
%%输入数据
load fisheriris
data= meas(:,3:4);
figure(1)
plot(data(:,1),data(:,2),'*')
%%判断数据中是否含有错误数据或非法字符
isNAN = any(isnan(data),2); %any表示有非0元素时返回为1,any(A,2)表示矩阵的行向量进行判断
hadNAN=any(isNAN); %表示数据中含有坏数据
if hadNAN
disp('kmeans:MissingDataRemoved');
disp(['missaddress is located ' num2str(find(isNAN==1))])
data = data(~isNAN,:);
end
二、配置K-means参数,包括聚类类别K、设置距离方式以及最大迭代次数和偏差等。
%%设置聚类类别k
k=3;
%%设置距离方式
%距离选择
%欧式距离:'euclidean',标准欧式距离:'seuclidean'
%曼哈顿距离(城市区块距离):'cityblock'
%闵可夫斯基距离:'minkowski'
%切比雪夫距离:'chebychev'
%夹角余弦距离:'cosine'
%相关距离:'correlation'
%汉明距离:'hamming'
distanceSize='euclidean';
%%设置最高迭代次数step和偏差
step=10;
maxdeviation=1e-5;
三、开始K-means聚类
[m,n]=size(data); %数据个数为m个,维度为n维
center = zeros(k,n+1); %聚类中心
center(:,n+1) =1:k ; %生成聚类的类别
dataSize=zeros(m,1); %生成数据类别
for j=1:k
center(j,1:n)=data(randi([1,m]),:); %随机产生k个中心
end
for i=1:step
%%第二步,分别计算各个点到中心的距离,并将离中心距离近的点归为一类
%计算距离
for j=1:k
distance(:,j)=pdist2(data,center(j,1:n),distanceSize);
end
%取距离最小的点归为一类
[~,temp]=min(distance,[],2);
dataSize=temp;
oldcenter=center;
%%更新中心点
for j=1:k
center(j,1:n)=mean(data(dataSize==j,:));
end
deviation=sum(abs(center-oldcenter)); %残差
if deviation<maxdeviation
break;
end
end
四、画出各个类别
figure(2)
for i=1:k
scatter(data(dataSize==i,1),data(dataSize==i,2));
hold on
end
plot(center(:,1),center(:,2),'x','MarkerSize',10);
hold off
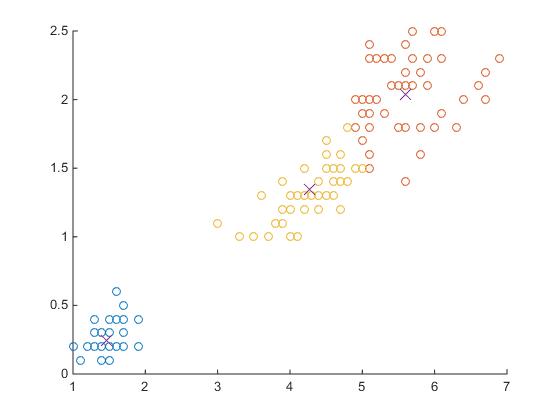
可以看出这里标注了聚类结果和各个簇的中心点位置。下面是运算数据结构:
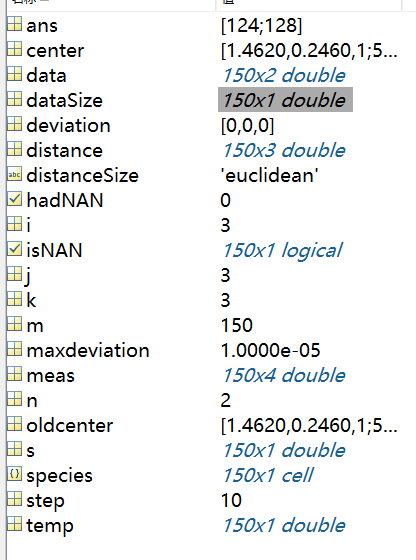
我们可以看到这里j=3;也就是说只迭代了3次,算法达到收敛。
因此,K-means具有如下优点:
(1)算法简单,特别对于类球型分布的数据效果特别好。
(2)收敛速度快,往往只需要5~6步即可达到收敛。
(3)算法复杂度为O(t,k,n)。其中t为迭代次数,k为分类的个数,n为数据点的个数。
当然,K-means也有一些缺点。
(1)由于聚类算法为无监督学习,人们事先无法确定到底需要分多少个簇,也就是说k值无法提前确定。
(2)同很多算法一样,它可能会收敛到局部最优解。而这和初始点的选取有关,我们可以采用多次选取初始点,最后选择效果最好的结果。
(3)对噪声影响敏感。我们可以看出K-means中means表示平均值,而平均值往往对噪声敏感,一个离群点往往会对整个结果造成很大影响。
(4)不适合某些非球类数据分布。
值得注意的是,这些缺点也正是K-means可以改进的地方。
最后,这里再介绍一个指标:silhouette。
这里,silhouette(i)=(b(i)-a(i))/max{b(i),a(i)}
a(i)表示第i个点到所被分类的簇的中心点的距离。
b(i)表示第i个点到其他簇中心点距离的最小值。
那么silhouette表示什么呢?我们可以看出,当a(i)<b(i)时,silhouette>0,表示该点距离该类中心距离更近;当a(i)>b(i)时,silhouette<0,表示该点距离其他类中心距离更近,这就好比一个人与他宿舍的人不如与他隔壁宿舍的人更加亲近。
如图所示为silhouette结果
%%silhouette
figure(3)
s=silhouette(data,dataSize);
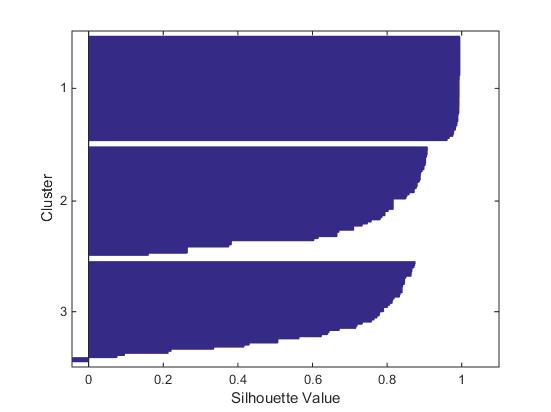
可以看到图中有个别点的silhouette为负数,我们将其找到,这里‘*’表示该点silhouette为负数。我们可以看到由于数据的分布为狭长的倾斜向上的分布,右上方两类距离很近,在这两类的交界处,很容易出现划归为A类的数据离另一类B更近的现象。