在某某花网上搜到一个视频,为了将视频下载到本地,我们尝试利用爬虫抓取资源
第一,我们检查网页元素,之后刷新页面
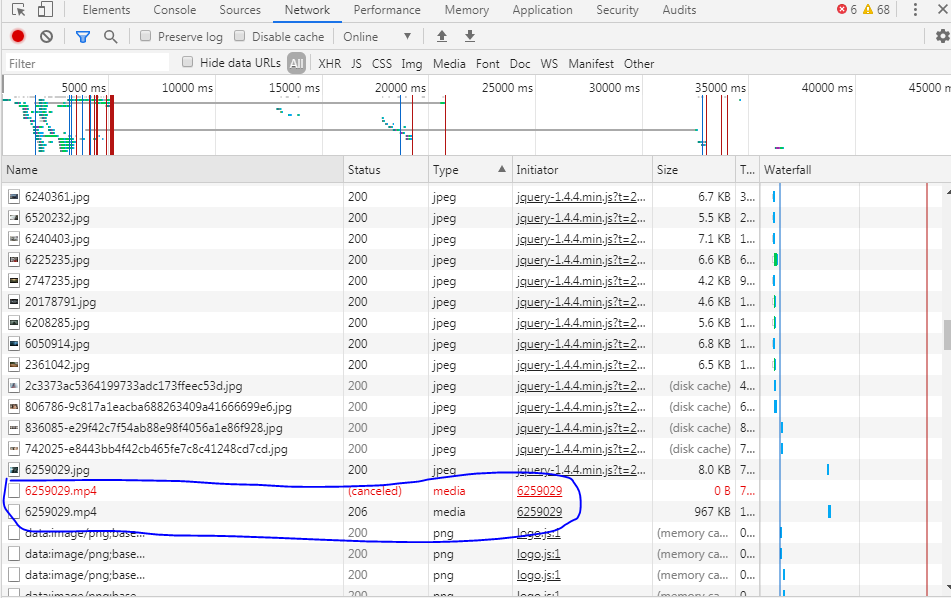
从上述信息中我们找到两个后缀名为.mp4的文件信息,其中第二条的status为206,留意它
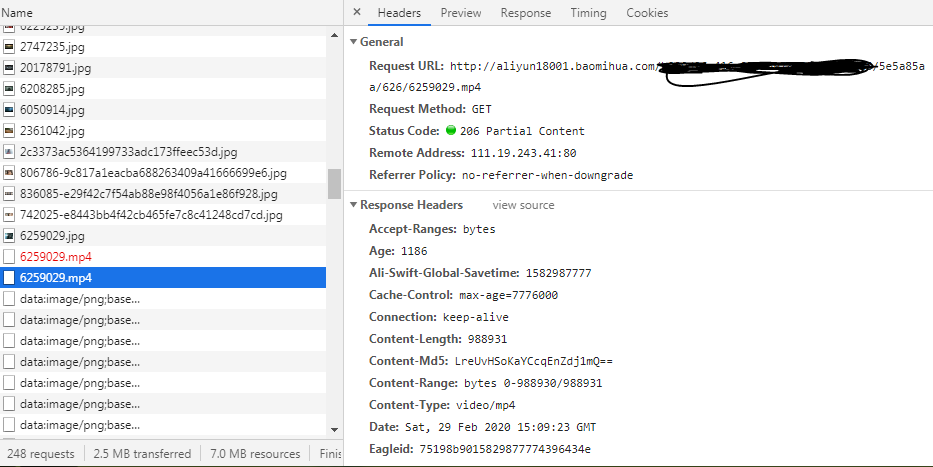
点击这条信息,从中我们获取到了这条视频真正的URL
根据视频URL信息,参照之前爬取网页图片的方法,我们成功将视频文件保存至本地
(方法与其大同小异,只需将爬取代码中的URL链接进行更换即可)
【传送门:https://www.cnblogs.com/fcbyoung/p/12291235.html】