python3x下,我们可以通过一下两种方式获取网页内容
获取地址: 国家地理中文网
url = 'http://www.ngchina.com.cn/travel/'urllib库
1、导入库
from urllib import request2、获取网页内容
with request.urlopen(url) as file:
data = file.read()
print(data)运行发现报错了:
urllib.error.HTTPError: HTTP Error 403: Forbidden
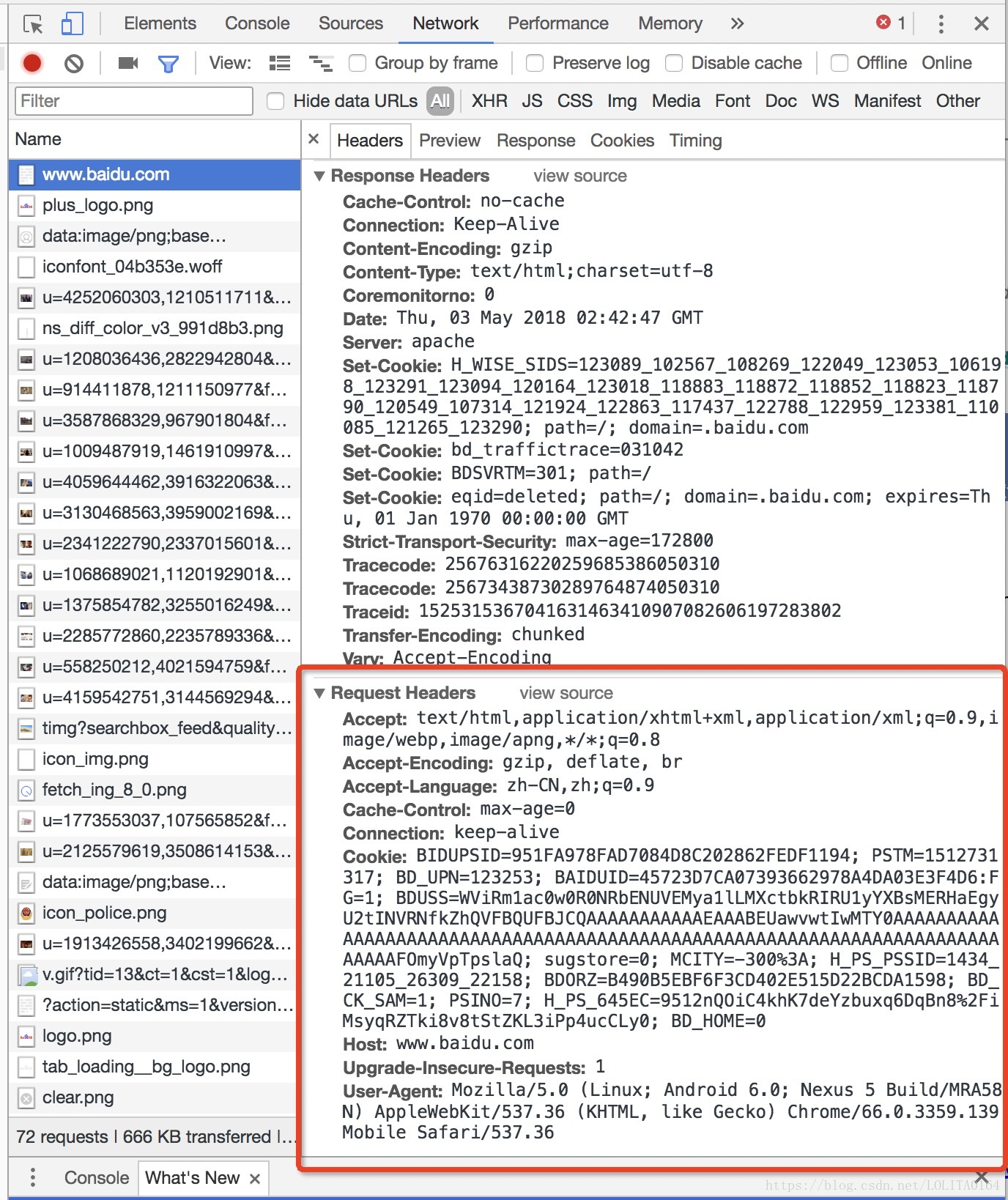
主要是由于该网站禁止爬虫导致的,可以在请求加上头信息,伪装成浏览器访问 User-Agent
那我们给请求头部里添加一个 ‘User-Agent’字段
headers = {'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Mobile Safari/537.36'}
# 创建请求
req = request.Request(url=url, headers=headers)
with request.urlopen(req) as response:
# 读取response里的内容,并转码
data1 = response.read().decode('utf-8') # 默认即为 utf-8
print(data1)关于 User-Agent,我们可以使用谷歌浏览器的开发者工具捕获查看
requests
1、导入库
import requests2、获取网页内容
with requests.get(url=url, headers=headers) as response:
# 读取response里的内容,并转码
data2 = response.content.decode()
print(data2)补充:
requests的response还可以获取更多信息的,包括cookies、头部、状态、url等等信息,想了解更多信息,请自行参考其他资料。
response.cookies
response.headers
response.status_code
response.url
在python2x下,可以参考这篇文章