第一节 倒排表
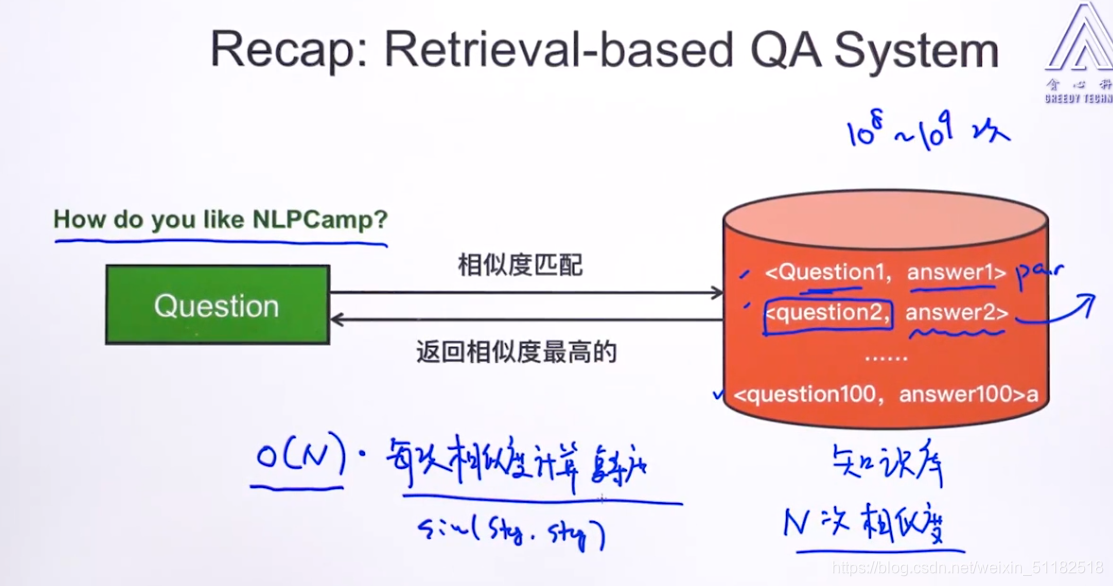
1、recap: retrieval-based QA system:
对于一个question,计算知识库中pair中问题与当前问题的相似度。时间复杂度为O(N)*每次相似度计算的复杂度。当N太大时,实用性不强
核心思路:层次过滤思想
先筛除掉完全不可能是答案的那些样本。
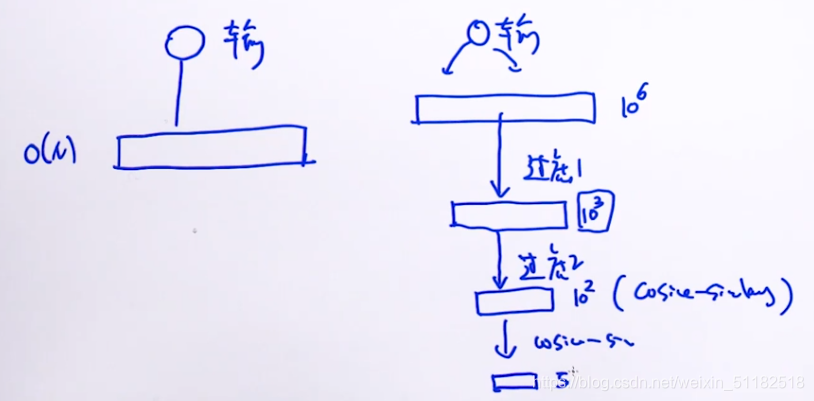
只有少部分的question会与输入question做余弦相似度。
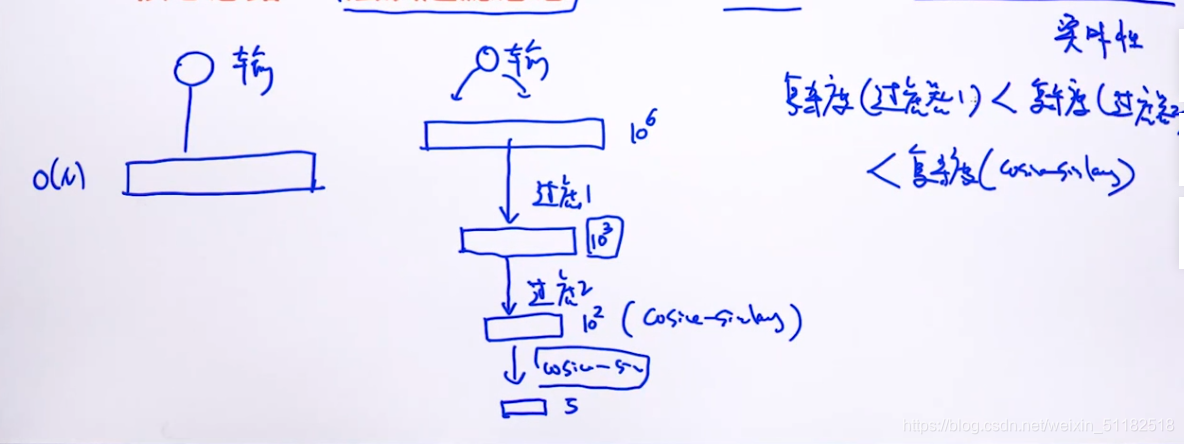
使用层级过滤思想,要求从上到下复杂度逐渐递增
2、解决问答系统复杂度过高的问题:
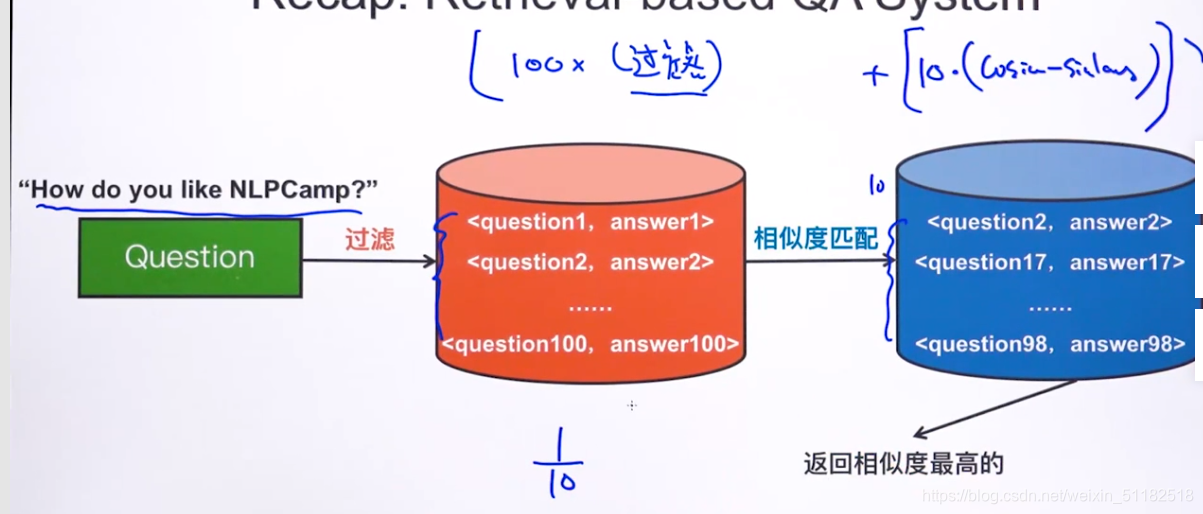
3、引入Inverted Index——倒排表

- 统计文档库中出现的所有的词
- 为每一个词创建一个列表,列表中元素为出现了该词的文档名称
- 当用户输入一个问题时,将这个问题做分词后,依次找到对应的词的列表,返回两个列表的交集(即出现a,也出现b词的文档名称)
4、在问答系统中使用倒排表:
- 过滤:保留那些至少包含了一个问题中其中一个单词的pair。
- 如果第一层过滤后去除的pair数量不理想,可以给予更严格的规则,如保留下的pair 的 问题中包含了至少两个输入问题的单词。
第二节:Noisy Channel Model

给定一些信号,将信号转为文本。
1、机器翻译
English====>Chinese
a r g m a x p ( 中 文 ∣ 英 文 ) ∝ p ( 英 文 ∣ 中 文 ) p ( 中 文 ) argmax p(中文|英文) \propto p(英文|中文)p(中文) argmaxp(中文∣英文)∝p(英文∣中文)p(中文)
- 前半部分:translation model
- 后半部分:语言模型
2、拼写纠错
p ( 正 确 的 写 法 ∣ 错 误 的 写 法 ) ∝ p ( 错 误 的 写 法 ∣ 正 确 的 写 法 ) p ( 正 确 的 写 法 ) p(正确的写法|错误的写法) \propto p(错误的写法|正确的写法)p(正确的写法) p(正确的写法∣错误的写法)∝p(错误的写法∣正确的写法)p(正确的写法)
- 前半部分:编辑距离
- 后半部分:语言模型
3、语音识别
输入是一个波形,把波形转换为文本
p ( 文 本 ∣ 语 音 信 号 ) ∝ p ( 语 音 信 号 ∣ 文 本 ) p ( 文 本 ) p(文本|语音信号) \propto p(语音信号|文本)p(文本) p(文本∣语音信号)∝p(语音信号∣文本)p(文本)
- 后半部分:语言模型
4、密码破解
p ( 明 文 ∣ 暗 文 ) ∝ p ( 暗 文 ∣ 明 文 ) p ( 明 文 ) p(明文|暗文) \propto p(暗文|明文)p(明文) p(明文∣暗文)∝p(暗文∣明文)p(明文)
- 后半部分:语言模型
第三节:Language Model——语言模型
1、介绍
语言模型用来判断:是否一句话从语法中通顺。

使用已经训练好的模型。
语言模型的目标:
Compute the probability of a sentence of sequence of words.

第四节:chain rule:
把联合概率用条件概率表达出来。

1、chain rule for language model
把一句话通过language model的概率转变为每个词组合的联合概率:

当条件特征过多时,会有稀疏性,即由多个单词组成的很长的一句话只有很低的概率出现在文章中。

第五节 Markov Assumption
使用马尔可夫假设去估计上述问题:如果条件特征太多,条件概率大部分为0。
1st order markov assumption:
对于一个单词出现的概率以及它的条件分布,它只依赖于前一个单词。即除了前一个单词,前面的其他单词都对它在文档中是否出现不产生影响。


Example: language model using 2nd order Markov assumption

从语义上,今天是周日好于今天周日是
第六节:语言模型
1、 Unigram language model——最简单的语言模型
当前单词全部都是条件独立的单词。联合概率为每个单词出现概率的乘积。
Unigram language model是无法考虑单词组成相同,但是语序不同的两个句子。
2、Bigram Unigram language model
来自 first order Markov assumption

考虑了顺序,尽管语句成分相同,但语序不同,概率不同
3、N-gram Language Model
N>2: higher order
N=3时:
4、估计语言模型的概率——Estimating Probability
4.1 Unigram:
统计语料库中每个词出现的次数/语料库中单词的总数

4.1 Bigram:

4.2 N-gram, N=3

一旦有一个条件概率没有,那么它的联合分布一定为0
5、评估一个语言模型—— Evaluation of Language Model

该方法的问题:
- 消耗时间,需要构建模型,还要使用模型
- 需求:在任务外评估好模型,选择最好的模型
核心思路:使用语言模型,给定一个句子,给定句子的第一个单词,让它预测下一个单词。
5.1 Perplexity:评估语言模型

5.2 example

- 召回率,精确率
- 准确率

使用Trigram时,perplexity最小,语言模型性能越好。
6、加入平滑项——adding smoothing
解决如果对于某个条件概率为0时,整个联合分布概率也为0的情况。
- Add-one smoothing: 拉普拉斯平滑
- Add-k smoothing
- Interpolation
- Good-Turning smoothing
6.1 Add-one smoothing

在分子加1,分母加入语料库中单词的个数(去重)。保证条件概率在该条件未发生时,依然有很小的概率可以得到。
为什么分母+v?
本来条件为0,如果加1,且上一个词出现的次数较少,那么该条件概率将变得很大。
保证给定相同条件,所有可能的结果的条件概率相加结果为1

6.2 Add-k smoothing
k是模型的超参数,需要调参
如何选择k?
优化f(k)
使用训练好的语言模型,应用在验证集语料库,计算perplexity,对k调参,使得perplexity在验证集上最小。

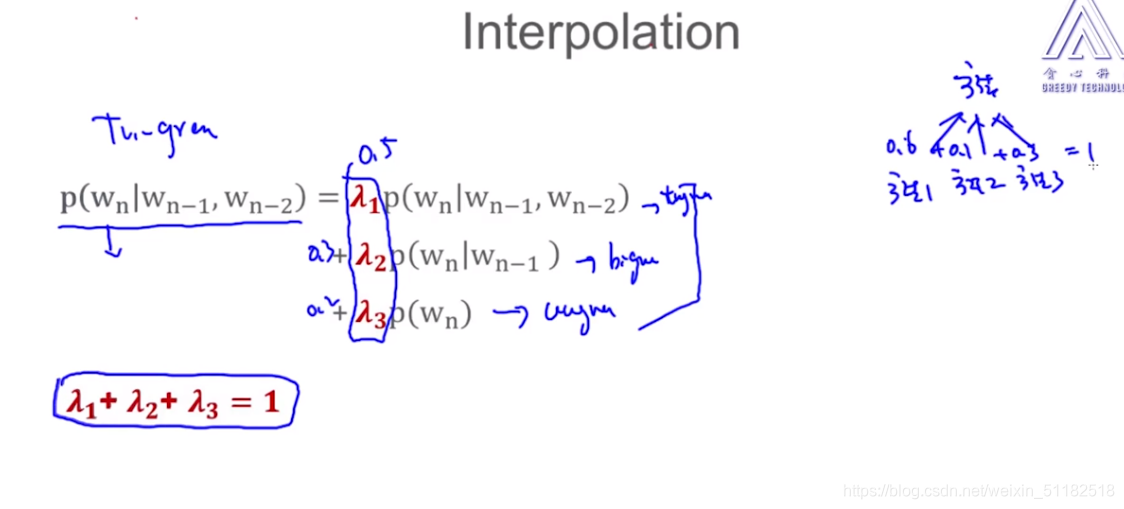
6.3 Interpolation
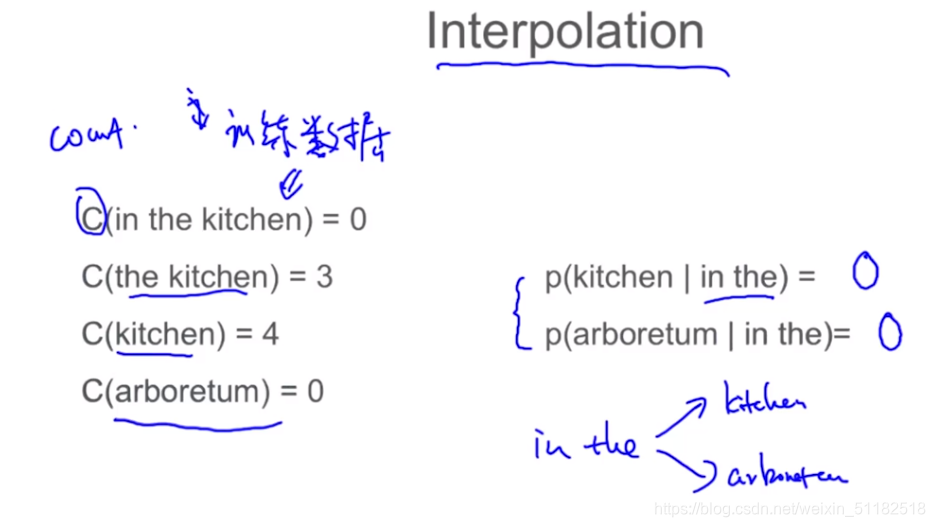
kitchen 出现的次数为4,arboretum出现的次数为0,那么给定in the 条件下,出现kitchen的条件概率应该大于arboretum。
思路:在使用Trigram时,是否应该考虑 unigram或者bigram出现的频次。
同时使用三种方法,对这三种方法加权。