
1.W2V & Glove
Word2Vec和Glove都是基于共现统计来描述词向量,其中Glove可以利用全局信息,可以更好的描述整个词汇库中词和词之间的相关性,在词类比和衡量词之间相似度上性能优异,而word2Vec只利用词上下文的共现信息,对该类任务性能较差。
两者的区别,从另一角度看,word2Vec属于predictive预测模型,glove属于基于计数的模型。
这类模型都是基于单词水平的,及每个向量,表示一个完整的词,那么会有什么缺点呢?
首先,如果要表示所有单词,那么需要你的训练语料库足够大到包括所有词汇,这需要很大的单词库。
没有包含在词库的单词,将不能识别,即OOV问题。
例如:goooooood bye,该算法遇到这种情况,会两眼一抹黑,发憷。
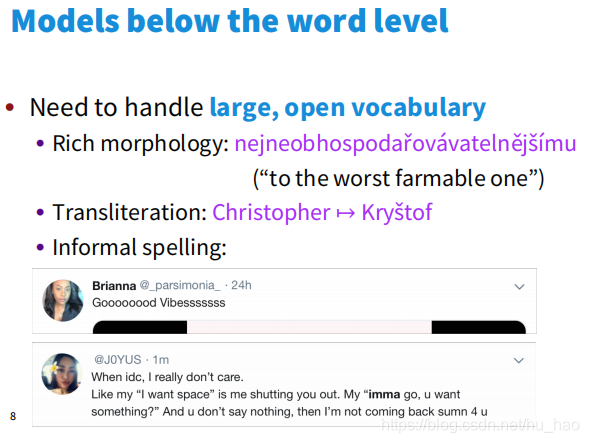
于是NLP专家在想,能不能有一种更基础的词向量表示,可以表示更为基础的语言单位,这样基础的语言单位可以构成词及其他所有词。
于是就有了字符模型。
2 Character-Level Models
字符级模型有两种思路,一种是将单个单词表示维分解为字符嵌入,那么相似的单词就有相似的嵌入,这样就可以解决OOV问题。另一种将连接的语言作为字符串处理,这里在连续的词上,取固定长度字符数作为嵌入词。两种方法都取得了不错的成绩。

但这类模型有个问题,就是从单词替换成字符导致处理的序列变长,原来一个单词,维度为300维,10个词只要3000个数据,现在一个词分为3个字符,需要30个向量,9000个数据,文本序列变长,处理速度变慢;由于序列变长,数据变得稀疏,数据之间的联系的距离变大,不利于学习。于是2017年,Jason Lee, Kyunghyun Cho, Thomas Hoffmann发表了论文Fully Character-Level Neural Machine Translation without Explicit Segmentation 解决了这些问题。
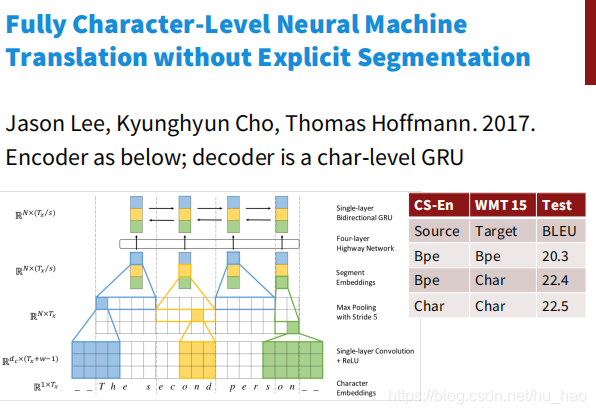
首先是对输入的character首先做一个embedding, 然后分别与大小为3,4,5的filter进行卷积运算,就相当于3-grams, 4-grams和5-grams。之后进行max-pooling操作,相当与选出了有语义信息的segment-embedding。之后将这些embedding送入Highway Network(相当于resnet, 解决了深层神经网络不容易训练的问题)后再通过一个单层的双向GRU,得到最终的encoder的output。之后经过一个character-level的GRU(作为decoder)得到最终结果。
3 subword models
子词模式是介于单词模型,和字符模型之间的模型,其基本单位为词片。
子词模型目前有两种类型:词片类型和混合模型

词片类型以字节对编码为代表:
Byte Pair Encoding(BPE)
Byte Pair Encoding,简称BPE,是一种压缩算法。
给定了文本库,我们的初始词汇库仅包含所有的单个的字符,然后不断的将出现频率最高的n-gram pair作为新的n-gram加入到词汇库中,直到词汇库的大小达到我们所设定的某个目标为止。如图所示:



混合模型:
混合模型即两种方式并存的模型,在正常处理时采用word-level的模型,当出现奇怪的词的后,使用char-level级的模型。


4 FastText
将subword的思想融入到word2vec中,FastText。处理文本速度,一个字,快。据说可以在10分钟内训练参数上亿的模型。
FastText embeddings是一个word2vec like embedding。用where举例, 它把单词表示成了: "where = <wh, whe, her, ere, re>, “这样的形式. 注意这里的”<>"符号是表达了开始和结束. 这样就可以有效地解决OOV的问题, 并且速度依然很快。

参考
Task 3: Subword Models (附代码)(Stanford CS224N NLP with Deep Learning Winter 2019)