0. 前言
- 参考资料:
- kaggle ---- Humpback Whale Identification Challenge:
- 套用slim中很多线程的模型,发现连baseline都达不到……
- 学习 Discussion 中的内容后,发现要用人脸识别相关技术…
1. 素质四连
- 要解决什么问题?
- 使用深度学习进行人脸识别任务。
- 人脸识别可以细分为三个子任务:
- face verification:判断是否为同一人。
- face recognition:判断是数据库中哪个人。
- face clustering:寻找相似的人脸。
- 用了什么方法解决?
- 与Wrod2Vec类似,将人脸图像通过一个长为128的向量表示。(如果直接取全局池化后的特征向量,对当时的算力来说,维度将过大。)
- 不同图像之间的相似度通过两个向量的欧几里德距离来决定,距离小则相似度高,距离大则相似度低。
- 使用 triplet loss 来替代普通多分类任务中的 softmax。
- 效果如何?
- 在 LFW Dataset 和 Youtube Faces DB 中,对比当时最佳模型,错误率下降30%。
- 还存在什么问题?
- 感觉该模型是数据驱动的,必须有大量数据支撑……比如我想在kaggle的中使用Humpback Whale Identification Challenge,那么得到的结果就没有那么精确(因为数据少)。
- 对triplet的选择比较讲究。
-
2. 论文主要内容
2.1. 模型总体结构
- 论文配图如下:
- 总体流程:
- 一组图像通过分类模型(如论文中提到的ZFNet、Inception V1)提取特征。一个mini-batch的数据输入到使用的CNN结构中,获取得到128维的特征向量。
- 将提取到的特征进行L2 normalize,得到embedding结果(即一张图片使用128维向量表示)。如:

- 将得到的embedding结果作为输入,计算triplet loss。以triplet loss为目标,优化整体网络。
- 什么是 l2 normalize?
- 参考
tf.nn.l2_normalize方法的实现。 output = x / sqrt(max(sum(x**2), epsilon))
- 参考
2.2. Triplet Loss 的定义
- Triplet的含义:
- Triplet的意思是 三元组,即损失函数通过三个参数来计算(而softmax的损失函数通过预测标签、标签两个参数来计算)。
- Triplet 三元组指的是:anchor, negative, positive 三个部分,每一部分都是一个 embedding 向量。
- anchor指的是基准图片,positive指的是与anchor同一分类下的一张图片,negative指的是与anchor不同分类的一张图片。
- 论文配图如下
- 训练目标:anchor与positive的距离比anchor与negative的距离小(相似度高)。
- 损失函数公式如下:
- 不太明白有下降的加号是什么意思,后续看源码。
- 公式中的 α 是 是边界(margin),用于区分正例和反例。
对于任意triplet来说,我们希望anchor离positive尽量近,离negative尽量远。即:
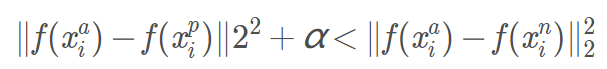
其中α\alphaα为阈值超参数,作为一个边际存在。因此有目标函数: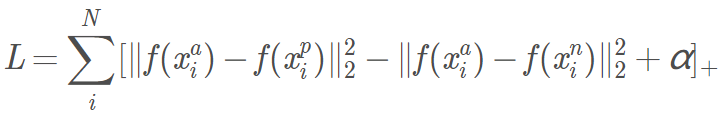
2.3. Triplet Selection
- Triplet 的选择对于模型收敛非常重要。
- 理想状态
- 选择 hard positive(即与anchor距离最大的同类图片)与 hard negative(即与anchor距离最小的不同类图片)。
- 这样做不太现实(计算量大),可能会由于错误标签图片导致难以收敛。
- 两种常用选择方法:
- 离线生成:每经过n次训练,计算某个子集中的 hard positive/negative。
- 在线生成(实时):在mini-batch中选择。
-
作者对两种生成方式都进行了实验,最终在论文中展现的均是以大mini-batch的方式进行在线生成。
- 在线生成Triplet的具体操作:
- 在每个mini-batch中,每个类型都有40个样本,再添加一些反例样本(理解的不太透彻,这段话原文是: In our experiments we sample the training data such that around 40 faces are selected per identity per mini-batch. Additionally, randomly sampled negative faces are added to each mini-batch)。
- 选择mini-batch中的所有 anchor-positve 对(而不是选择hard positive),并选择 hard negative。相比anchor-hard positive,这样收敛速度比较快。
- 选择hard negative会导致收敛到局部最小点,建议使用 semi-hard negative,即忽略损失函数中的$\alpha$。
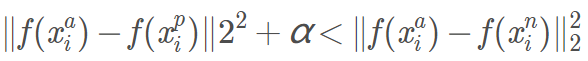
2.3 Deep Convolutional Networks
文章一共探索了两种神经网络:
- zeiler & Fergus model (NN1)
- GoogleNet Style Inception model (NN2)
- 两个网络都能接受[220,220,3]的输入,输出[1,1,128]维的输出
- 细节不再说了,就是一个特征提取网络的选择问题
4 论文其他内容
- embedding向量大小对于结果有一定影响(并不是越大越好),发现长度为128最佳。
- 训练集越大越好(文中最多用了两亿多张图片)
- 使用对齐工具后,效果更好
- 图像质量越高,效果越好
单词整理:
- downside 缺点
- thumbnail 缩略图
- alignment 对准,校准
- exemplar 模范,榜样
- illustration 例证
- variability 变化性
- corpus 资料集
- constrain 压制,抑制
- versus 与
- collasped 倒塌
- mitigate 减轻
- recitfy 纠正
