背景
密度图\(D_g\)的生成对于最终网络预测结果\(D_e\)至关重要,但是密度图\(D_g\)生成的过程中,高斯核的大小常常是手动设定的,并且对于不同的数据集,核大小和形状通常不一样。这些手动选择的参数,对网络来说可能不是最优的。
本文贡献
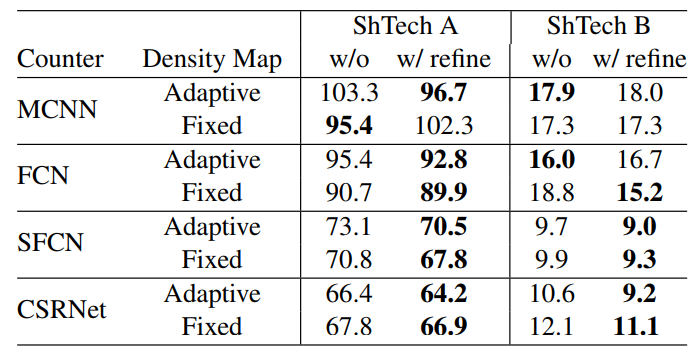
验证手动选择的高斯核不是最优的
为了验证手动选择的高斯核不是最优的,作者设计了一个Density Map Refinement网络,如下
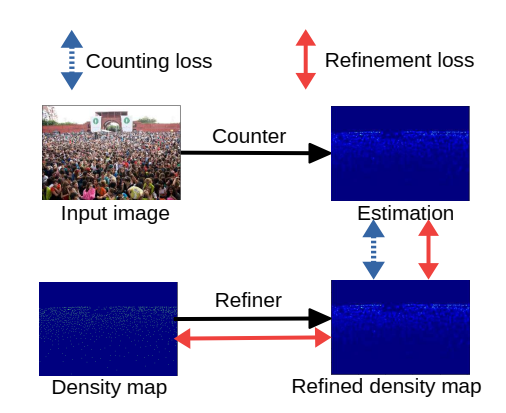
下半部分是一个Refiner网络,将手动生成的密度图 \(D_g\)进行refine,生成更为精细的密度图 \(D_{g'}\),作为上半部分Counter网络的回归目标。上半部分的网络为正常的预测密度图 \(D_e\)的网络。将原有的密度图 \(D_g\)Refine后,可以看到,网络的效果确实提升了,证实了作者观点。
提出了一个自适应生成密度图的方法
尽管前面提出的Refiner网络能够提升网络精度,但是仍然依赖于前期手动选择参数生成的密度图\(D_g\)。为了克服这个弊端,作者设计了一个自适应生成密度图\(D_g\)的网络,如下
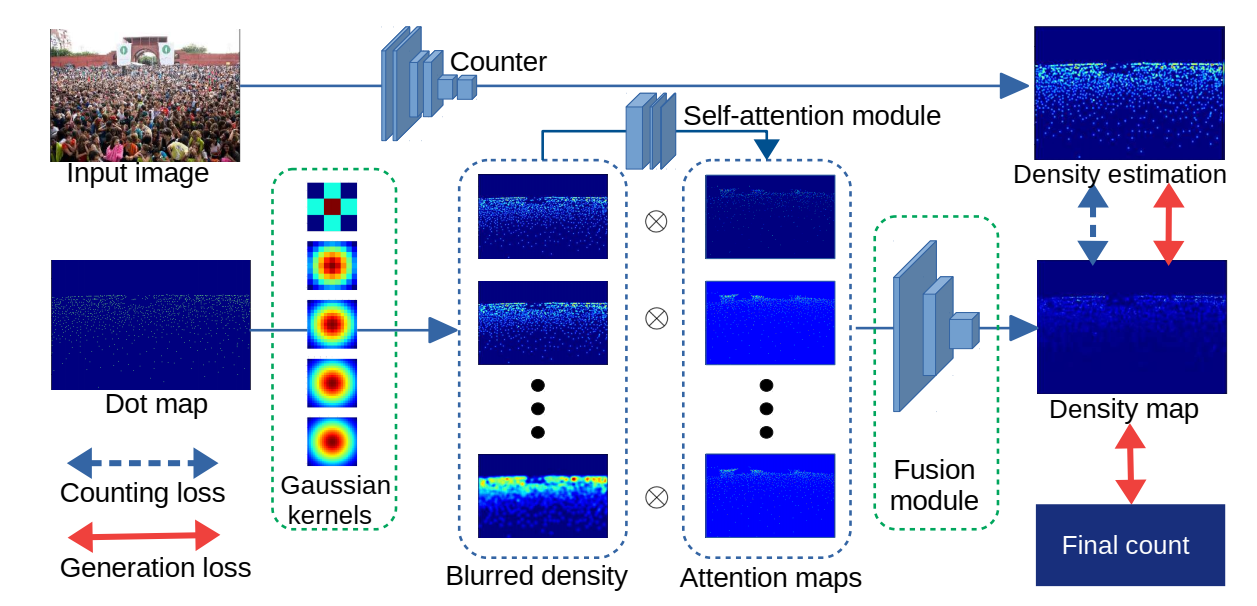
第一行与前面提到的网络没有什么区别,主要改动是将下面的Refiner网络改成了自适应生成密度图的网络。首先,预先给定K个高斯核,与标注的点图作用生成K个密度图 \(B_i\),然后每个密度图经过self-attention网络,生成对应的attention map,将attention map和对应的 \(B_i\)按像素相乘,就能够自适应地选择输入图片每个区域使用哪种核,最后一起送入fusion模块进行融合,就得到了密度图 \(D_g\),与第一行的Counter网络一起,完成整个网络的训练。
下图是使用后的效果
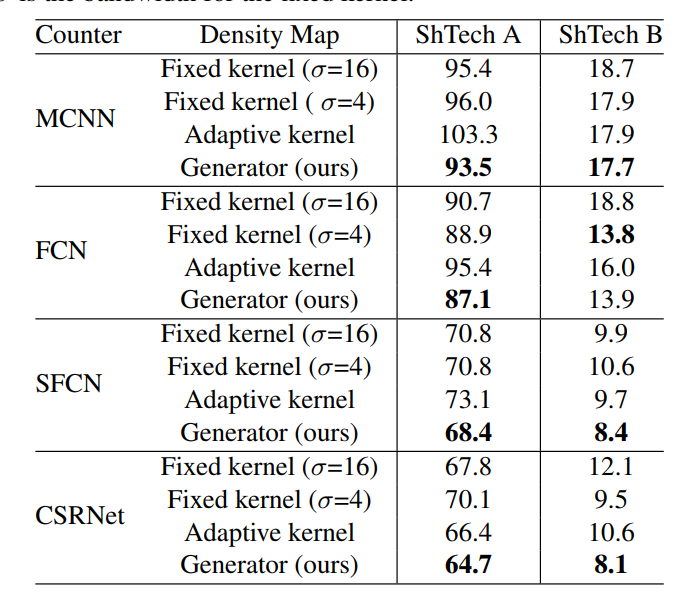
这里有一点要说明,作者尝试了不预先设定K个高斯核的参数,改为网络自适应学习高斯核参数,发现效果均不如固定设置的
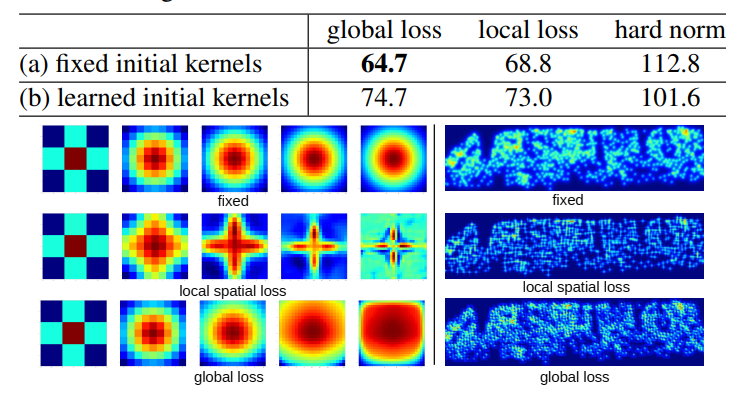
其中global loss, spatial loss, hard norm是自适应网络在不同loss下的表现,高斯核途中,第一行表示固定高斯核参数,第二三行表示不同loss下学得的高斯核形状