题目:THE HSIC BOTTLENECK: DEEP LEARNING WITHOUT BACK-PROPAGATION
Abstract
这篇文章介绍了深度学习训练中的HSIC瓶颈(希尔伯特-施密特独立准则)HSIC瓶颈是传统反向传播的一种替代方法,它有许多明显的优点。这种方法有利于并行处理,并且需要的操作要少得多。它不受爆炸或消失梯度的影响。它在生物学上比反向传播更合理,因为不需要对称反馈。我们发现HSIC瓶颈在MNIST/FashionMNIST/CIFAR10分类上提供了与交叉熵目标反向传播相当的性能,即使不鼓励系统使输出类似于分类标签。附加一个使用SGD(无反向传播)训练的单层会导致最新的性能。
直观地说,IB主体在压缩有关输入数据的信息时保留关于标签的隐藏表示的信息。
Introduction
当前深度学习的误差反向传播算法在生物学上通常被认为是不合理的[1,2,3]。在实际应用中,反向传播和相关的随机梯度下降算法SGD及其变体非常耗时,存在梯度消失和爆炸的问题,需要跨层的顺序计算,并且通常需要探索学习率和其他超参数。这些考虑正在推动对理论和实际备选方案的研究[4]。
通过最大化隐藏表示和标签之间相互信息的代理项,同时最小化隐藏表示和输入之间的相互依赖。
我们进一步证明,用这种方法训练的网络的隐藏单元形成了有用的表示。具体地说,可以通过冻结无反向传播训练的网络,并使用传统的SGD将表示转换为所需的格式来附加和训练单层网络,从而获得完全竞争的精度。
提出了一种不需要反向传播的深度网络训练方法。它包括使用信息瓶颈的近似值来训练网络。由于随机变量间互信息的计算困难,本文采用了基于非参数核的Hilbert-Schmidt独立准则(HSIC)来描述不同层的统计依赖性。也就是说,对于每个网络层,我们同时最大化该层和所需输出之间的HSIC,并最小化该层和输入之间的HSIC。与标准的反向传播算法相比,这种HSIC瓶颈的使用导致了训练过程中的快速收敛。由于HSIC瓶颈直接作用于连续随机变量,它比传统的基于binning的信息瓶颈方法更具吸引力。该方法使用一个浅层的经过常规训练的后处理网络将得到的表示转换为输出标签的形式。在实际应用中,我们使用一个由多个层组成的网络,以可变维数(完全连接层)或不同核数(卷积层)为起点。
Related Work
反向传播的生物学合理性是一个备受争议的话题,也是探索其他方法的一个动机。一个问题是,突触的重量是根据下游的错误来调整的,这在生物系统中是不可行的[26,27]。另一个问题是前馈推理和反向传播是相同的
权重矩阵。这就是所谓的重量运输问题[28,11]。此外,反向传播梯度是线性计算的,但大脑有复杂的神经连接,在计算前馈时必须停止反向传播(反之亦然)[1]。
信息理论[29]是学习理论研究的基础[8,30,31]。信息瓶颈(IB)原理[7]推广了最小充分统计量的概念,表达了预测输出所需信息和保留的输入信息之间隐藏表示的折衷。
直观地说,IB主体在压缩有关输入数据的信息时保留关于标签的隐藏表示的信息.
HSIC是再生核Hilbert空间(RKHS)中分布之间互协方差算子的Hilbert-Schmidt范数。
与互信息不同,HSIC没有信息论量(bits或nats)的解释。另一方面,HSIC不需要密度估计,计算简单可靠。像HSIC这样的核分布嵌入方法也可以抵抗异常值,这可以通过考虑高斯核下异常值的影响来看出。经验估计值以与数据维数无关的速率1=pn收敛到总体HSIC值[33],这意味着它部分规避了维数的诅咒。
原则上,HSIC可以发现变量之间的任意依赖关系,但在实际应用中,对于有限数据,HSIC核中σ参数的选择更强调某些尺度上的关系。直观地说,当两个数据点x;y的差足够小或足够大时,它们并没有被很好地区分,以至于它们位于高斯函数的小斜率部分。这通常是通过基于数据[35,36]中间距离选择核σ,或者通过参数搜索(如网格搜索[37]或随机搜索[38])来处理的。
此外,核分布嵌入方法HSIC也可以抵抗异常值,这可以通过考虑高斯核下异常值的影响来看出。
利用HSIC研究了自编码器的泛化特性。2018)使用HSIC来限制潜在空间搜索,以限制聚合变分后验。(Vepakomma等人。2019)使用距离相关性(HSIC的替代公式)从医疗培训数据中删除不必要的私人信息。
Proposed Method
本HSIC训练网络的输出包含分类所需的信息,但不一定是正确的形式首先,如果输出是一个hot,可以简单地对其进行排列,使其与训练标签对齐。在第二种方案中,我们在冻结的瓶颈训练网络中附加一个单层和softmax输出,并使用无反向传播的SGD训练附加层。这一步骤称为位置训练。

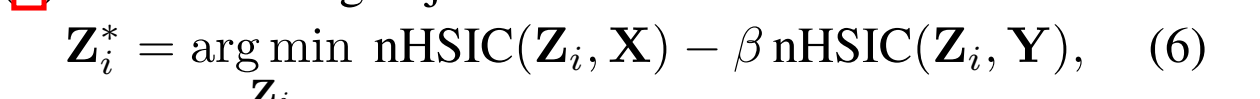

公式(6)、(7)表明,最优隐藏表示Zi在独立于不必要的输入细节和依赖于输出之间找到平衡。理想情况下,当(6)收敛时,预测标签所需的信息被保留,而允许过度拟合的不必要信息被移除。
我们使用块坐标下降法在每一层独立地优化方程(6),而不使用梯度传播

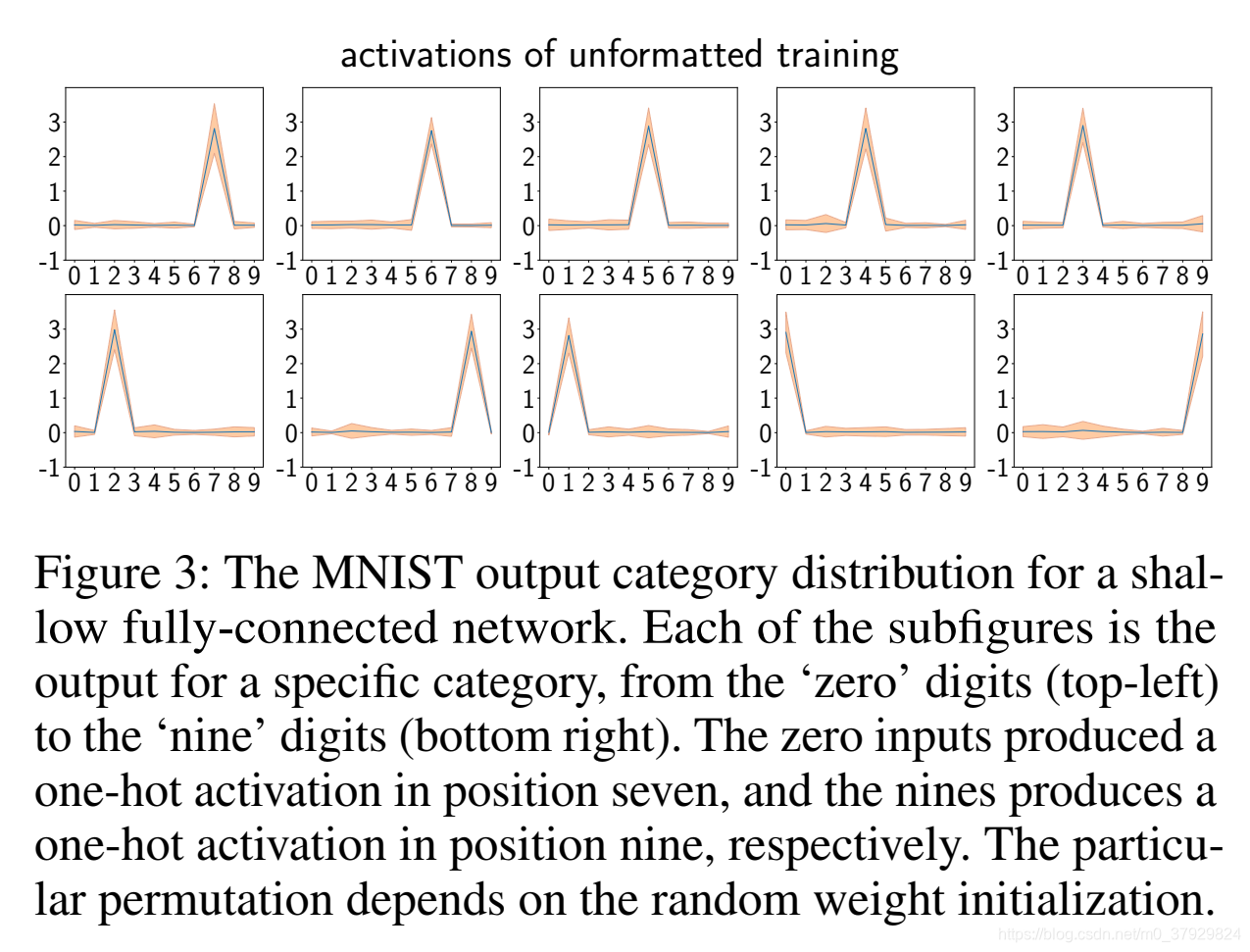
如实验部分所示,在某些实验中,HSIC瓶颈训练往往会产生一个One-hot输出。这启发我们利用HSIC瓶颈目标直接解决分类问题。这是通过设置最后一层ZL的维度来实现的,以匹配类的数量(例如,dL=dy)。由于所得到的激活通常是相对于标签的排列(例如,数字0的图像可能激活第四输出层条目),我们只需通过选择特定类的输入上具有最高激活的输出作为该类的输出来找到固定的排列。
原则上,HSIC是统计独立性的一个强有力的度量,然而在实践中,即使使用规范化形式(5),结果也在一定程度上取决于所选择的σ参数。为了解决这一问题,我们将具有不同σ的无格式训练网络组合起来,然后聚合得到的隐藏表示。这种多尺度网络架构如图1b所示,并且具有
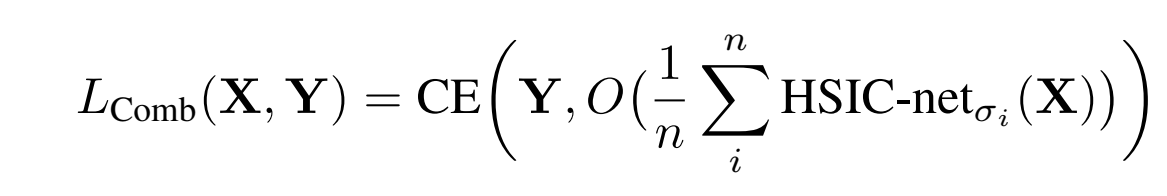
然而,学习收敛是一个最终的兴趣量。这个数量对于反向传播或HSIC瓶颈都是未知的,并且考虑到这两种方法的根本不同特征,它可能是不同的。由于消除了反向传播的需要,HSIC瓶颈更适合于层并行计算。
Experiment
在这一部分中,我们报告了几个探索和验证HSIC训练网络概念的实验。首先,为了激励我们的工作,我们绘制了一个简单模型在反向传播训练中的HSIC瓶颈值和激活分布。然后,我们将展示无格式训练如何产生一个热结果,直接准备好使用浅或深网络进行分类。接下来,我们比较了不同层数网络上的反向传播和格式训练。在接下来的实验中,我们考虑了HSIC训练对格式训练的价值以及超参数σ的影响。最后,我们简要讨论了HSIC训练在ResNet等其它网络体系结构中的应用。
实验中,我们在MNIST/Fashion MNIST/CIFAR10数据集上使用了具有批处理规范化的标准前馈网络(Ioffe和Szegedy 2015)。所有实验,包括标准反向传播、未格式化训练和格式训练,都使用一个简单的SGD优化器。将HSICbottleneck的系数β和核尺度因子σ分别设置为500和5,在经验上平衡了压缩和分类任务可用的相关信息。
在考虑使用“HSIC”作为训练目标之前,我们首先在传统深度网络训练的背景下验证其相关性(图2)。利用反向传播技术对一个简单网络的输入输出和隐藏激活之间的nHSIC进行监测,结果表明,随着表征的形成,nHSIC(Y;ZL)在早期训练中迅速增加,而nHSIC(X;ZL)则迅速下降。nHSIC(Y;ZL)的值随网络深度而变化(图2e),并取决于激活的选择(图2b)。此外,它与训练精度的提高明显平行(图2c,图2f)。总之,图2示出了一系列不同的网络遵循信息瓶颈原理。

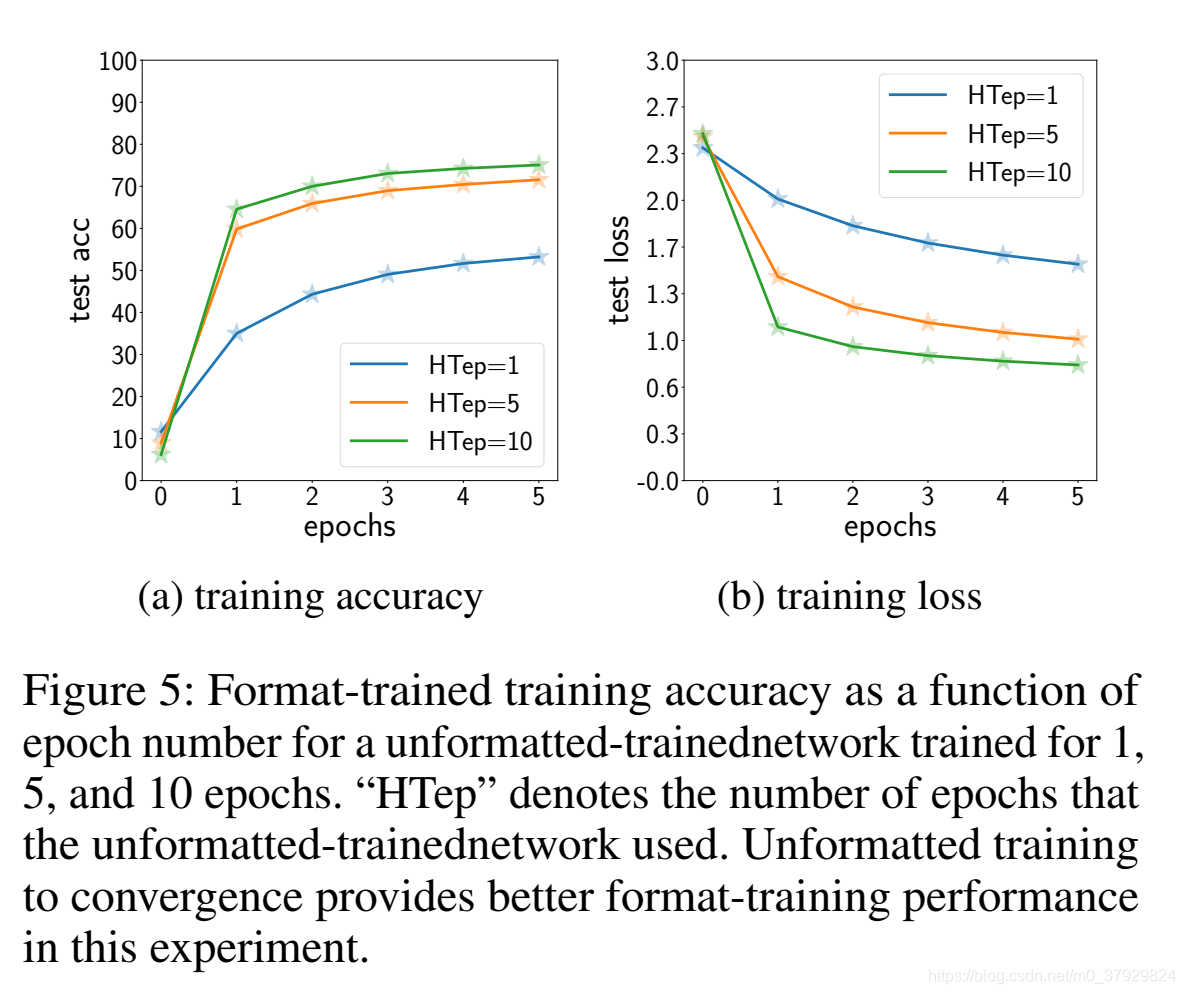
关于深层神经网络,一个有趣的问题是这些层叠层如何有效地从输入和标签中学习信息。为了探索这个问题,我们修正了非格式化训练网络的所有超参数,除了训练时间(历元数)。我们期望为更多的时代训练未格式化的训练网络将导致隐藏的表示,更好地表示预测标签所需的信息,从而在格式训练阶段获得更高的精度。图5示出了该实验的结果,具体地,在由1、5和10个阶段训练的五层无格式训练网络上的格式训练的准确性和丢失。从图5可以看出,在SGD格式训练开始时,无格式训练网络可以提高精度。另外,0随着未格式化训练网络训练时间的延长,formattraining产生更高的精度。

结果表明,在多尺度网络上进行的格式训练优于其他实验,表明它在格式训练阶段提供了与相应尺度相关的附加信息。这也表明单个σ不足以捕获这些网络中的所有依赖项。把σ当作一个可学习的参数留给以后的工作。
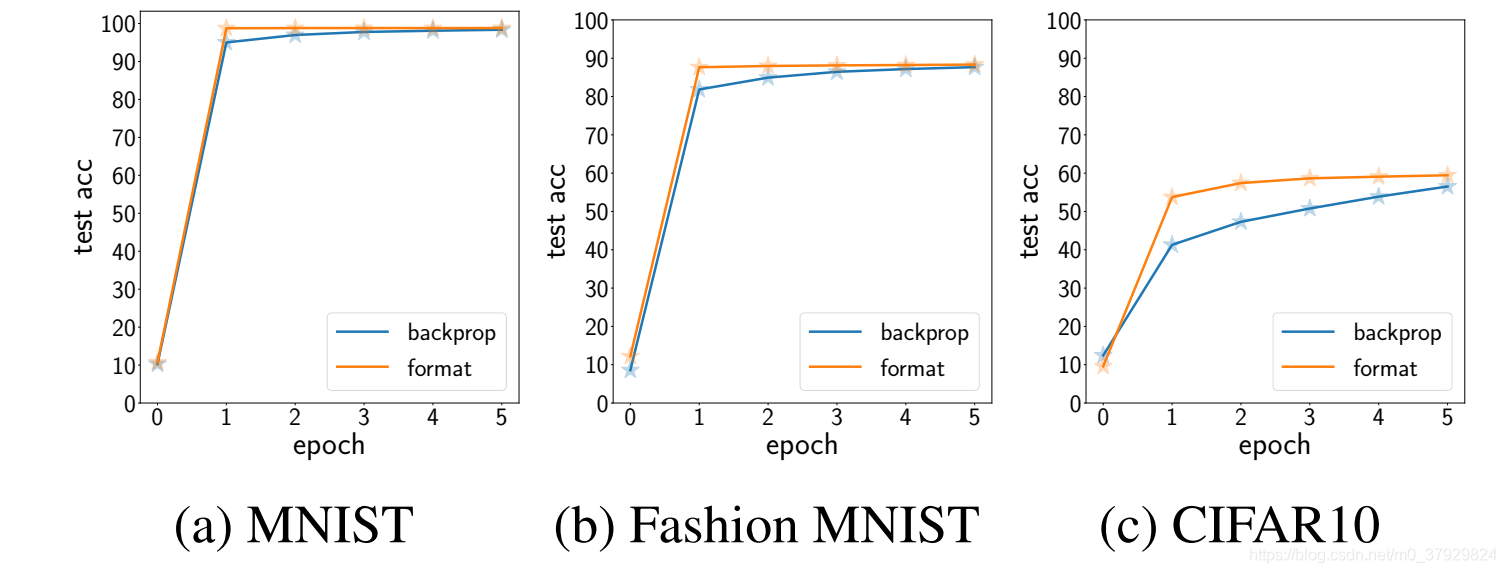
在图7中,我们展示了在初始时间段的多个数据集上具有五个卷积残差块的网络的测试性能。每个实验包括五个未格式化的训练阶段,然后使用单层分类器网络进行格式训练,并与标准的反向传播训练阶段进行比较。
结果表明,利用非格式化训练网络的不同表现形式,格式训练能更快地收敛到高精度性能。
图7的最终测试精度分别为(98.8%,88.3%,59.4%)和(98.4%,87.6%,56.5%)对于反向传播训练网络,对于MNIST,FashionMNIST和CIFAR10。CIFAR10的结果远远低于最先进的性能,因为我们没有使用最先进的架构。然而,HSICbottleneck网络在收敛性方面提供了显著的提升。
Conclusion
本文提出了一种不使用反向传播的深层神经网络训练方法。该方法受到信息瓶颈的启发,可以看作是一种近似,但是(据我们所知)是第一种利用HSIC作为代理来回避在深神经网络中计算互信息的方法。几个标准分类问题的“无格式”HSIC瓶颈训练产生一个One-hot,可以直接排列来执行分类,其精度接近于同一体系结构的标准反向传播训练。通过使用输出作为格式训练阶段的表示,进一步提高了性能,在格式训练阶段中,使用常规SGD附加和训练单层(和softmax),但不使用反向传播。HSIC瓶颈训练网络通过去除无关信息并保留对目标任务重要的信息,提供了良好的隐藏表示。
与传统的反向传播相比,HSIC瓶颈培训有几个好处:
•能够训练反向传播训练失败的深层网络(图4);
•它缓解了传统反向传播中的消失和爆炸梯度问题,因为它不使用链式规则逐层解决问题;
•它消除了向后清扫的需要;
•它可能允许使用分层块坐标下降并行训练层;
•尽管我们的方法在生物学上并不合理,但它确实解决了重量传递问题(Lillicrap等人。2016)和更新锁定问题。
参考文献
https://arxiv.org/abs/1908.01580
