目录
1、绘制X轴、Y轴平行线
2、逻辑回归模型建立过程中存在的两个问题
1)问题一:如何将等式左右连续化
2)问题二:使用sigmoid函数,将任意范围的值,映射为(0,1)
3)使用matplotlib绘制sigmoid函数
4)逻辑回归函数的推导
3、逻辑回归——鸢尾花数据集的简单预测
1、逻辑回归的由来
本人是统计学专业,这里将自己学习中所理解的逻辑回归,给你们做一个详细的说明,希望能帮助到你们。如果觉得本文对您有帮助,可以关注一下这个博客,精彩抢先看。
先来回顾一下“线性回归模型”,它有如下两个特点:
- 因变量是连续性的变量,或者说因变量近似是连续性数据;
- 它研究的是x,y之间的线性相关关系;
这里,再回到逻辑回归,它区别于线性回归,最主要的特点就是:
- 逻辑回归的因变量是0-1型数据;
对于0-1型数据,就表示这个数据有两个可能的取值。数学上为了方便,把其中一个记为0,另外一个记为1。即:用0和1代表数据的两个结果。
eg:购买决定:我是买呢?还是不买?
eg:离职决定:离职?还是不离职?
我们可以定义:1 = 购买;0 = 不购买; 1 = 离职; 0 = 不离职;
简单地说:只要有抉择的地方,就会有0-1型数据。0-1型数据反映的不是阿拉伯数字0和1,它反映的是两个不能兼得的结果中的一个。
如果0-1数据关乎业务的核心诉求,那它就是我们的因变量z(z只是一个标记,你也可以写为y)。于是,同线性回归的定义一样,我们就会有一堆的自变量x(x也是一个标记,你也可以换成任何其他字母),尝试去解释那个因变量。
于是,我们也需要一个回归模型来解决此类问题。基于这种诉求,便产生了“逻辑回归”。
2、逻辑回归模型建立过程中存在的两个问题
根据上述叙述,我的目标现在很明确。基于一个0-1变量z,建立一个回归模型使得:
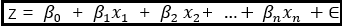
1)问题一
问题一:x为任意实数,β也为任意实数。因此上述等号右边的值,也为任意实数。但是等号左边的z却是一个0-1变量,显然有问题。
根本原因在于:0-1型变量z不是连续的,但是等号右边的值却是连续的。因此只有把0-1型变量变得连续了,上述等式才有可能成立。
于是科学家就想出了一种可能性度量表示这个0-1变量z。这种可能性度量一般用“概率”表示。回到之前的eg,我们定义了:1 = 购买;0 = 不购买;而介于高低之间的存在着很想购买,一般想购买,一点想购买等这样不同的概率程度。
于是,上式左侧已经变成了一个(0,1)之间的连续型变量了,不再是一个0-1的二值变量。
2)问题二
问题二:虽然上述“等号两边”都是连续性数据了,但是“等号右边”的取值范围是(-∞,+∞),而“等号左边”的取值范围却是(0,1)之间,很显然又存在问题。
鉴于上述问题,科学家又想出了一个方法,对于任意一个给定的输入,通过一个函数后,将这个(-∞,+∞)的值,映射到(0,1)之间。于是,引入了“sigmoid函数”。
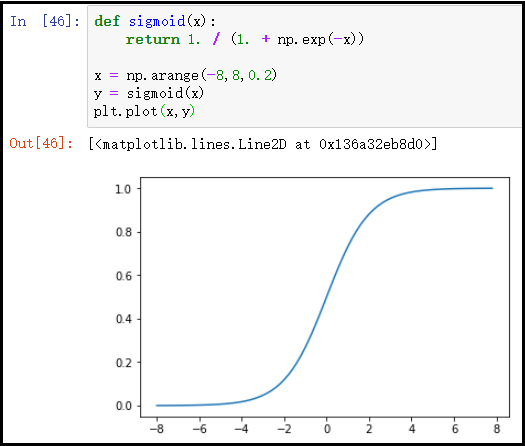
3)使用matplotlib绘制sigmoid函数
def sigmoid(x):
return 1. / (1. + np.exp(-x))
x = np.arange(-8,8,0.2)
y = sigmoid(x)
plt.plot(x,y)
结果如下:
4)逻辑回归函数的推导

注意:y表示取0或者1的概率。
3、逻辑回归——鸢尾花数据集的简单预测
1)相关代码的说明
- iris数据集是一个类字典格式的数据。以键-值对形式存在。其中数据存放在 “data”键中,目标变量存放在“target”键中,并且都是以数组形式存放数据的。
- pprint叫做“漂亮的打印”,对于有字典格式的数据,都能给你很工整的打印出来,尤其是做爬虫的时候很有用,一定要下去尝试一下。
- train_test_split()函数,用于切分数据集,参数test_size=0.2表示我们把整个数据的20%切分出来,作为测试集,那么剩下的80%就是用作训练集。参数random_state=12是一个随机种子,任意整数即可,这个为了保证每次运行代码时,任然是同一个切分。
2)代码如下
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from pprint import pprint
from sklearn.datasets import load_iris
iris = load_iris()
# pprint(iris)
x_tr,x_te,y_tr,y_te = train_test_split(iris["data"],iris["target"],
test_size=0.2,random_state=12)
model = LogisticRegression().fit(x_tr,y_tr)
pre = model.predict(x_te)
print(pre)
print("预测精度如下:")
print(sum(y_te == pre) / len(pre))
结果如下:

