
1 什么是BN?
数据归一化方法,往往用在深度神经网络中激活层之前。其作用可以加快模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失。并且起到一定的正则化作用,几乎代替了Dropout
2 原理
BN的基本思想其实相当直观:因为深层神经网络在做非线性变换前的激活输入值x随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数(激活函数)的取值区间的上下限两端靠近,所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因。
而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
到了这里,又会发现一个问题:如果都通过BN,那么不就跟把非线性函数替换成线性函数效果相同了?我们知道,如果是多层的线性函数变换其实这个深层是没有意义的,因为多层线性网络跟一层线性网络是等价的。这意味着网络的表达能力下降了,这也意味着深度的意义就没有了。所以BN为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scale*x+shift),每个神经元增加了两个参数scale和shift参数,这两个参数是通过训练学习到的,意思是通过scale和shift把这个值从标准正态分布左移或者右移一点并长胖一点或者变瘦一点,每个实例挪动的程度不一样,这样等价于非线性函数的值从正中心周围的线性区往非线性区动了动。核心思想应该是想找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢。当然,论文作者并未明确这样说。
对于输入的网络参数,第一步先计算均值和标准差,然后将参数集合转换成均值为0,标准差为1的标准正态分布,最后公式的后面还有一个反向操作, 将 normalize 后的数据再扩展和平移. 原来这是为了让神经网络自己去学着使用和修改这个扩展参数 γ \gamma γ, 和 平移参数 β \beta β, 这样神经网络就能自己慢慢琢磨出前面的 normalization 操作到底有没有起到优化的作用, 如果没有起到作用, 我就使用 γ \gamma γ 和 β \beta β 来抵消一些 normalization 的操作.
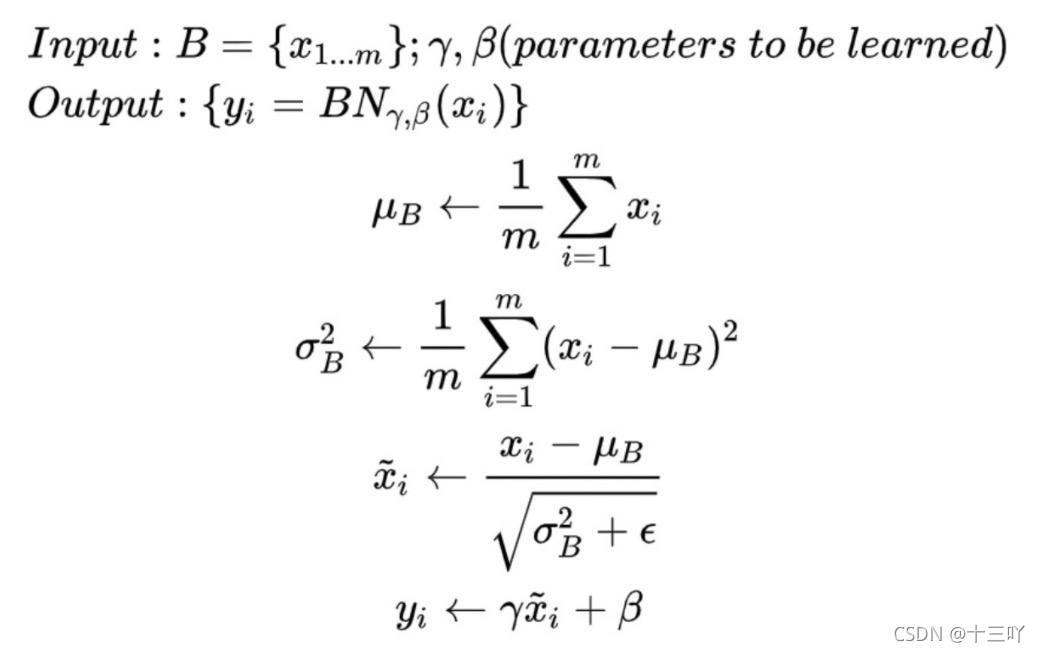
3 BN带来的好处:
(1)没有它之前,需要小心的调整学习率和权重初始化,但是有了BN可以放心的使用大学习率;
(2)极大提升了训练速度,收敛过程大大加快;
(3)Batch Normalization本身上也是一种正则的方式,可以代替其他正则方式如Dropout等。
4 BN的缺陷:
Batch Normalization中的batch就是批量数据,即每一次优化时的样本数目,通常BN网络层用在卷积层后,用于重新调整数据分布。假设神经网络某层一个batch的输入为X=[x1,x2,…,xn],其中xi代表一个样本,n为batch size。当batch值很小时,计算的均值和方差不稳定。研究表明对于ResNet类模型在ImageNet数据集上,batch从16降低到8时开始有非常明显的性能下降。所以BN不适应于当训练资源有限而无法应用较大的batch的场景
参考
- 《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
- https://blog.csdn.net/qq_42823043/article/details/89765194
- https://zhuanlan.zhihu.com/p/93643523
欢迎关注微信公众号(算法工程师面试那些事儿),本公众号聚焦于算法工程师面试,期待和大家一起刷leecode,刷机器学习、深度学习面试题等,共勉~
