一、逻辑回归数学背景
1、逻辑回归(Logistic回归)分析概要
如果现在想对某件事情发生的概率进行预估,比如一个非医用口罩,在疫情期间是否有人愿意买?这里的Y变量是“是否愿意购买”,属于分类数据,所以不能使用回归分析。如果Y为类别性(定性)数据,研究影响关系,正确做法是选择Logistic回归分析。
Logistic回归分析可用于估计某个事件发生的可能性,也可分析某个问题的影响因素有哪些。研究影响关系时,即X对于Y的影响情况。Y为定量数据,X可以是定量数据或定类数据。医学研究中,Logistic回归常用于对某种疾病的危险因素分析。像是分析年龄、吸烟、饮酒、饮食情况等是否属于2型糖尿病的危险因素。
Logistic回归和线性回归最大的区别在于,Y的数据类型。线性回归分析的因变量Y属于定量数据,而Logistic回归分析的因变量Y属于分类数据。
逻辑回归应用场景:广告点击率(是否会被点击),垃圾邮件、是否患病、金融诈骗、虚假账号等
2、Logistic回归分类
·按照反应变量类型
如果Y值仅两个选项,分别是有和无之类的分类数据,选择二元Logistic回归分析。Y值的选项有多个,并且选项之间没有大小对比关系,则可以使用多元Logistic回归分析。Y值的选项有多个,并且选项之间可以对比大小关系,选项具有对比意义,应该使用多元有序Logistic回归分析。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Rvosujtu-1582614978105)(attachment:image.png)]](https://img-blog.csdnimg.cn/20200225151641905.png)
·按照研究设计类型
- 非条件logistic回归(研究对象未经匹配)
- 条件logistic回归(研究对象经过匹配)
3、二元Logistic回归模型
注意:二元不是说只有两个自变量x,而是因变量Y只有两种取值,一般用0/1替换。
因变量Y=0 或 1 ,0表示不发生,1表示发生,自变量X1,X2,X3,...,Xm.
在m个自变量的作用下,因变量Y=1发生的概率是p,p=p(Y=1|X1,X2,...,Xm) 0<=p<=1
它与自变量X1,X2,...,Xm之间的Logistic回归模型为:
p = [exp(b0+b1X1+b2X2+...+bmXm)]/[1+exp(b0+b1X1+b2X2+...+bmXm)]
1-p = 1/[1+exp(b0+b1X1+b2X2+...+bmXm)]
换算一下:
p/(1-p) = exp(b0+b1X1+b2X2+...+bmXm)
ln(p/(1-p)) = b0+b1X1+b2X2+...+bmXm = logit(p)
当没有影响因素x的作用时,b0就表示发生与不发生概率比的自然对数值
当某个因素Xi 变化时(暴露水平变化),如x=0,变为x=1,Xi=1与Xi=0相比,发生某结果(如发病)优势比的对数值。用来表示bi的含义。
优势比OR = (P1/(1-P1))/(P0/(1-P0))
LnOR = ln[(P1/(1-P1))/(P0/(1-P0))] = ln[(P1/(1-P1))]- ln[(P0/(1-P0))] = logit(p1)-logit(p0)
参考:https://wenku.baidu.com/view/6c1421bef424ccbff121dd36a32d7375a417c675.html?sxts=1581917115648
二、逻辑回归在机器学习中的使用
1、回顾原理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gYZyQZGQ-1582614978111)(attachment:image.png)]](https://img-blog.csdnimg.cn/2020022515170117.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MTY4NTM4OA==,size_16,color_FFFFFF,t_70)
2、损失函数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Kuxxvv67-1582614978114)(attachment:image.png)]](https://img-blog.csdnimg.cn/20200225151713136.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MTY4NTM4OA==,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rGYs7NML-1582614978115)(attachment:image.png)]](https://img-blog.csdnimg.cn/20200225151723686.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MTY4NTM4OA==,size_16,color_FFFFFF,t_70)
3、优化
使用梯度下降优化算法,去减少损失函数的值。这样去更新逻辑回归前面对应算法的权重参数,提升原本属于1类别的概率,降低原本是0类别的概率。
4、逻辑回归API
·sklearn.linear_model.LogisticRegression(solver=‘liblinear’,penalty=‘L2’,C=1.0)
。solver.优化求解方式(默认开源的liblinear库实现,内部使用了坐标轴下降法来送代优化损失函数)
·sag:根据数据集自动选择,随机平均梯度下降
。penalty:正则化的种类(优化算法)
。C:正则化力度,取值0-1,1-10。正则化力度越大,权重系数会越小,正则化力度越小,权重系数会越大。
默认将类别数量少的当做正例
三、案例:癌症分类预测–良/恶性
import pandas as pd
import numpy as np
'''# 1、读取数据'''
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data"
column_name = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv(path, names=column_name)
data.head()
| Sample code number | Clump Thickness | Uniformity of Cell Size | Uniformity of Cell Shape | Marginal Adhesion | Single Epithelial Cell Size | Bare Nuclei | Bland Chromatin | Normal Nucleoli | Mitoses | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1000025 | 5 | 1 | 1 | 1 | 2 | 1 | 3 | 1 | 1 | 2 |
| 1 | 1002945 | 5 | 4 | 4 | 5 | 7 | 10 | 3 | 2 | 1 | 2 |
| 2 | 1015425 | 3 | 1 | 1 | 1 | 2 | 2 | 3 | 1 | 1 | 2 |
| 3 | 1016277 | 6 | 8 | 8 | 1 | 3 | 4 | 3 | 7 | 1 | 2 |
| 4 | 1017023 | 4 | 1 | 1 | 3 | 2 | 1 | 3 | 1 | 1 | 2 |
'''2 数据预处理'''
# 2、缺失值处理
# 1)替换-》np.nan
data = data.replace(to_replace="?", value=np.nan)
# 2)删除缺失样本
data.dropna(inplace=True)
data.isnull().any() # 不存在缺失值

'''# 3、划分数据集'''
from sklearn.model_selection import train_test_split
# 筛选特征值和目标值
x = data.iloc[:, 1:-1]
y = data["Class"]
x_train, x_test, y_train, y_test = train_test_split(x, y)
'''# 4、特征工程---标准化'''
from sklearn.preprocessing import StandardScaler
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
'''# 5、预估器流程'''
from sklearn.linear_model import LogisticRegression
estimator = LogisticRegression()
estimator.fit(x_train, y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class=‘ovr’, n_jobs=1,
penalty=‘l2’, random_state=None, solver=‘liblinear’, tol=0.0001,
verbose=0, warm_start=False)
# 逻辑回归的模型参数:回归系数和偏置
print(estimator.coef_)
print(estimator.intercept_)
[[1.34024013 0.18048714 0.62944579 0.7852792 0.23563408 1.35251239
1.03318021 0.89956106 0.71665637]]
[-0.7170217]
'''# 6、模型评估'''
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
# print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
y_predict:
[2 2 2 2 2 4 2 2 2 2 2 2 2 4 4 2 4 2 4 2 4 2 4 4 2 2 4 2 2 2 4 2 2 2 4 4 2
4 2 2 2 2 2 2 4 4 2 4 4 2 2 2 2 2 2 2 4 4 2 4 2 2 2 2 4 2 2 4 2 4 4 4 2 2
4 4 2 2 2 2 2 4 2 4 4 2 2 4 2 2 4 4 4 2 4 2 2 2 4 2 2 4 4 2 4 2 2 4 4 4 2
4 2 2 4 2 2 2 4 4 2 2 2 2 2 4 2 2 2 2 2 2 2 2 2 2 4 4 2 4 2 2 2 4 2 2 2 2
2 2 2 2 2 2 4 4 2 2 4 2 2 2 2 2 4 4 4 4 2 2 2]
准确率为:
0.9824561403508771
# 查看精确率、召回率、F1-score
from sklearn.metrics import classification_report
report = classification_report(y_test, y_predict, labels=[2, 4], target_names=["良性", "恶性"])
print(report)
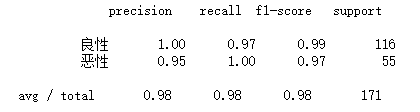
# ROC曲线与AUC指标
from sklearn.metrics import roc_auc_score
print(y_test.head())
# y_true:每个样本的真实类别,必须为0(反例),1(正例)标记
# 将y_test 转换成 0 1
y_true = np.where(y_test > 3, 1, 0)
print(y_true)

roc_auc_score(y_true, y_predict) #计算AUC指标:越接近1越好
0.9870689655172414
